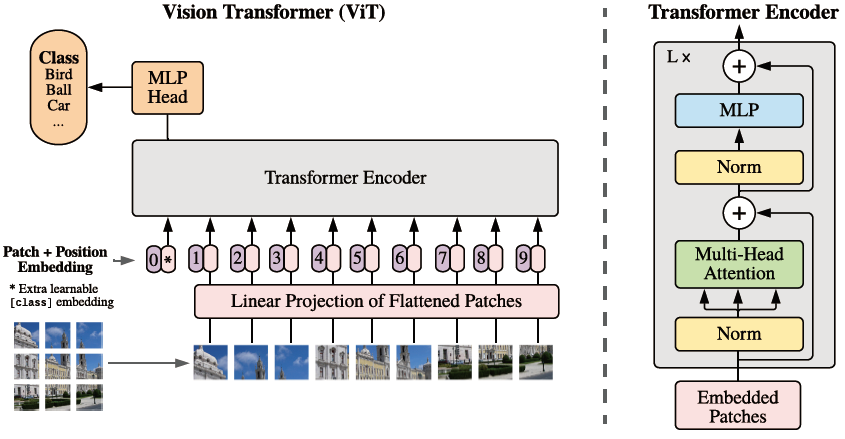
0 概述
- 论文模型结构
代码地址
对应代码的详细模型结构
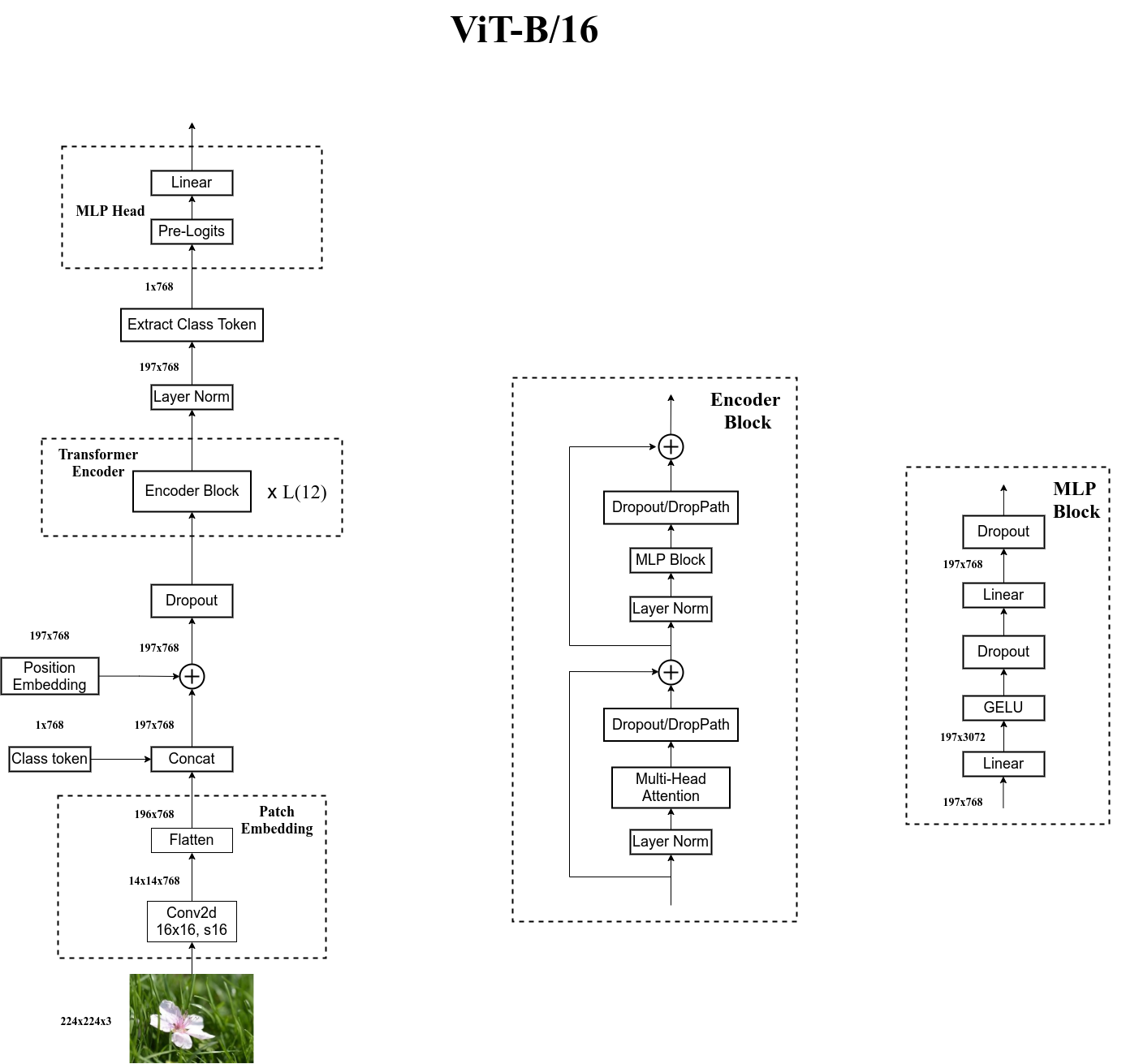
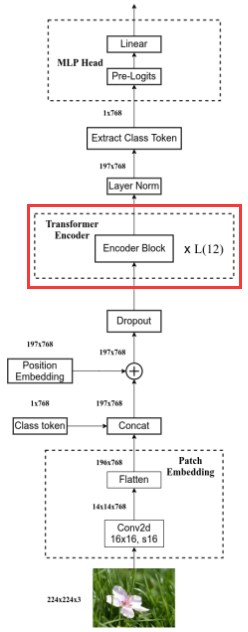
1 Vision Transformer
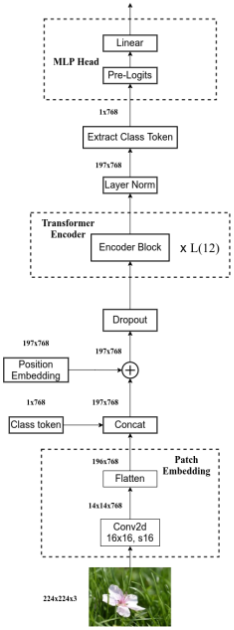
class VisionTransformer(nn.Module):def __init__(self, img_size=224, patch_size=16, in_c=3, num_classes=1000,embed_dim=768, depth=12, num_heads=12, mlp_ratio=4.0, qkv_bias=True,qk_scale=None, representation_size=None, distilled=False, drop_ratio=0.,attn_drop_ratio=0., drop_path_ratio=0., embed_layer=PatchEmbed, norm_layer=None,act_layer=None):"""Args:img_size (int, tuple): input image sizepatch_size (int, tuple): patch sizein_c (int): number of input channelsnum_classes (int): number of classes for classification headembed_dim (int): embedding dimensiondepth (int): depth of transformernum_heads (int): number of attention headsmlp_ratio (int): ratio of mlp hidden dim to embedding dimqkv_bias (bool): enable bias for qkv if Trueqk_scale (float): override default qk scale of head_dim ** -0.5 if setrepresentation_size (Optional[int]): enable and set representation layer (pre-logits) to this value if setdistilled (bool): model includes a distillation token and head as in DeiT modelsdrop_ratio (float): dropout rateattn_drop_ratio (float): attention dropout ratedrop_path_ratio (float): stochastic depth rateembed_layer (nn.Module): patch embedding layernorm_layer: (nn.Module): normalization layer"""super(VisionTransformer, self).__init__()self.num_classes = num_classesself.num_features = self.embed_dim = embed_dim # num_features for consistency with other modelsself.num_tokens = 2 if distilled else 1norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6)act_layer = act_layer or nn.GELUself.patch_embed = embed_layer(img_size=img_size, patch_size=patch_size, in_c=in_c, embed_dim=embed_dim)num_patches = self.patch_embed.num_patchesself.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))# dist_token用于建立DeiT,ViT用不到self.dist_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) if distilled else Noneself.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.num_tokens, embed_dim))self.pos_drop = nn.Dropout(p=drop_ratio)dpr = [x.item() for x in torch.linspace(0, drop_path_ratio, depth)] # stochastic depth decay ruleself.blocks = nn.Sequential(*[Block(dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,drop_ratio=drop_ratio, attn_drop_ratio=attn_drop_ratio, drop_path_ratio=dpr[i],norm_layer=norm_layer, act_layer=act_layer)for i in range(depth)])self.norm = norm_layer(embed_dim)# Representation layerif representation_size and not distilled:self.has_logits = Trueself.num_features = representation_sizeself.pre_logits = nn.Sequential(OrderedDict([("fc", nn.Linear(embed_dim, representation_size)),("act", nn.Tanh())]))else:self.has_logits = Falseself.pre_logits = nn.Identity()# Classifier head(s)self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()self.head_dist = Noneif distilled:self.head_dist = nn.Linear(self.embed_dim, self.num_classes) if num_classes > 0 else nn.Identity()# Weight initnn.init.trunc_normal_(self.pos_embed, std=0.02)if self.dist_token is not None:nn.init.trunc_normal_(self.dist_token, std=0.02)nn.init.trunc_normal_(self.cls_token, std=0.02)self.apply(_init_vit_weights)def forward_features(self, x):# step 1: 生成tokens# [B, C, H, W] -> [B, num_patches, embed_dim] eg: [B, 196, 768]x = self.patch_embed(x)# step 2: 拼接class token# [1, 1, 768] -> [B, 1, 768]cls_token = self.cls_token.expand(x.shape[0], -1, -1)if self.dist_token is None:# [B, 197, 768]x = torch.cat((cls_token, x), dim=1)else:x = torch.cat((cls_token, self.dist_token.expand(x.shape[0], -1, -1), x), dim=1)# step 3: 累加position embeddingx = self.pos_drop(x + self.pos_embed)# step 4: pass transformer encodersx = self.blocks(x)x = self.norm(x)if self.dist_token is None:return self.pre_logits(x[:, 0])else:return x[:, 0], x[:, 1]def forward(self, x):x = self.forward_features(x)# 构建ViT时,head_dist为Noneif self.head_dist is not None:x, x_dist = self.head(x[0]), self.head_dist(x[1])if self.training and not torch.jit.is_scripting():# during inference, return the average of both classifier predictionsreturn x, x_distelse:return (x + x_dist) / 2else:# step 5: pass MLP Headx = self.head(x)return x
2 Patch Embedding
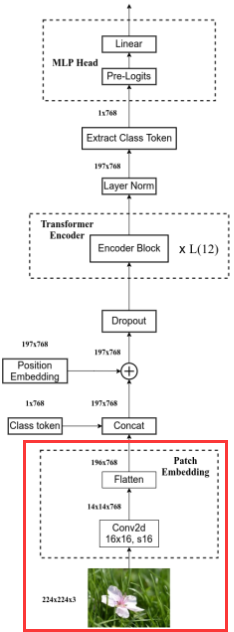
代码
class PatchEmbed(nn.Module):"""2D Image to Patch Embedding"""def __init__(self, img_size=224, patch_size=16, in_c=3, embed_dim=768, norm_layer=None):super().__init__()img_size = (img_size, img_size)patch_size = (patch_size, patch_size)self.img_size = img_sizeself.patch_size = patch_sizeself.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])self.num_patches = self.grid_size[0] * self.grid_size[1]# 卷积核大小 = patch_sizeself.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()def forward(self, x):# 传入图像的H和W与预设值不一致时将报错B, C, H, W = x.shapeassert H == self.img_size[0] and W == self.img_size[1], \f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."# Conv2d eg: [B, 3, 224, 224] -> [B, 768, 14, 14]# flatten eg: [B, 768, 14, 14] -> [B, 768, 196]# transpose eg: [B, 768, 196] -> [B, 196, 768]x = self.proj(x).flatten(2).transpose(1, 2)x = self.norm(x)return x
3 Encoder-Block
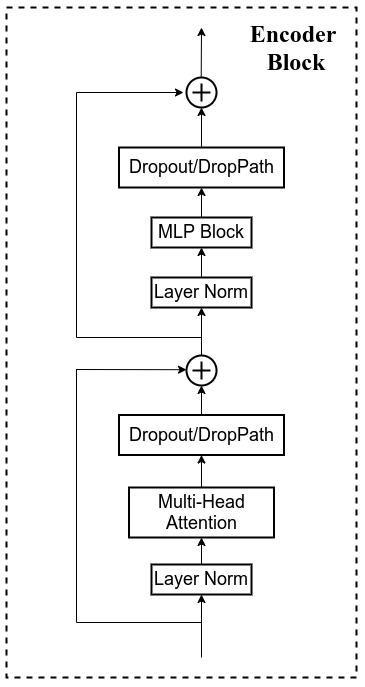
代码
class Block(nn.Module):def __init__(self,dim,num_heads,mlp_ratio=4.,qkv_bias=False,qk_scale=None,drop_ratio=0.,attn_drop_ratio=0.,drop_path_ratio=0.,act_layer=nn.GELU,norm_layer=nn.LayerNorm):super(Block, self).__init__()self.norm1 = norm_layer(dim)self.attn = Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,attn_drop_ratio=attn_drop_ratio, proj_drop_ratio=drop_ratio)self.drop_path = DropPath(drop_path_ratio) if drop_path_ratio > 0. else nn.Identity()self.norm2 = norm_layer(dim)mlp_hidden_dim = int(dim * mlp_ratio)self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop_ratio)def forward(self, x):x = x + self.drop_path(self.attn(self.norm1(x)))x = x + self.drop_path(self.mlp(self.norm2(x)))return x
4 Encoder-Block: Multi-Head Attention
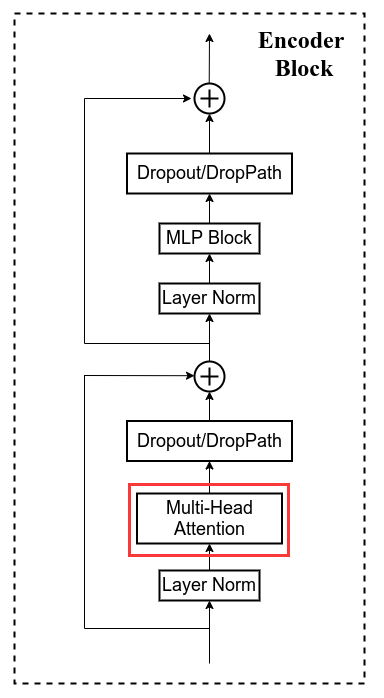
- Transformer Encoder
- Self-Attention
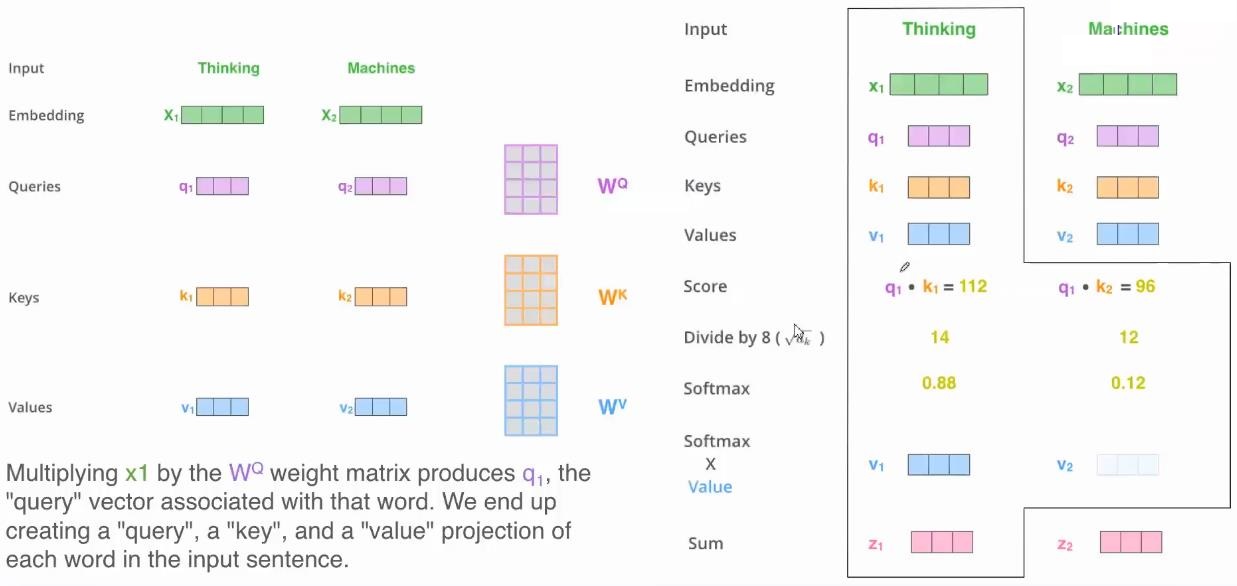
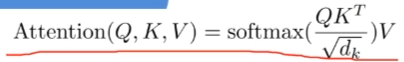
- Multi-Head
用不同的 、
、 、
、 就能得到不同的Q、K、V
就能得到不同的Q、K、V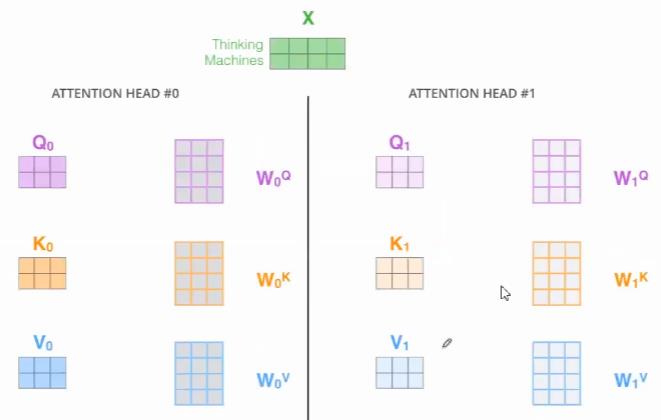
现在一个 对应多个版本的
对应多个版本的 ,那么怎么结合为一个
,那么怎么结合为一个 ?
?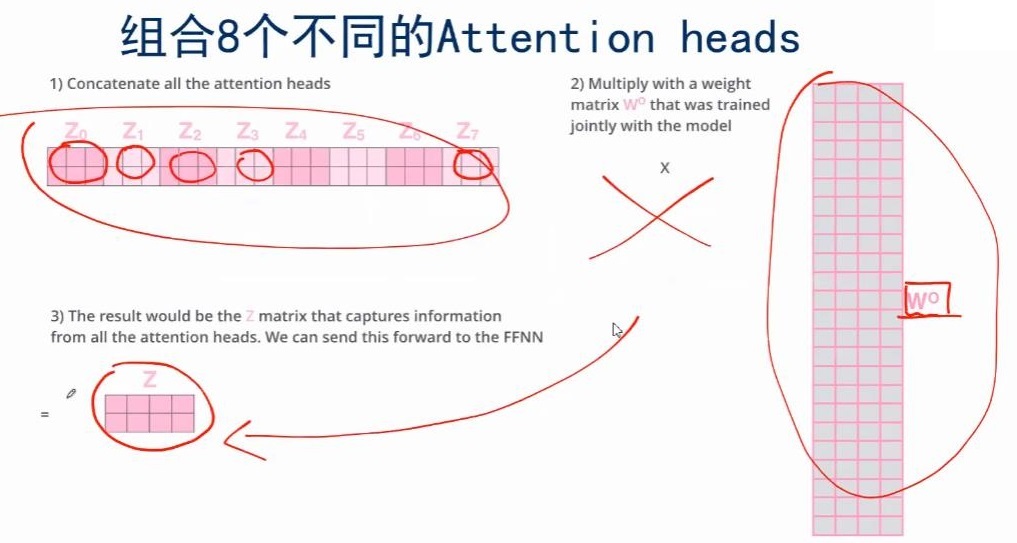
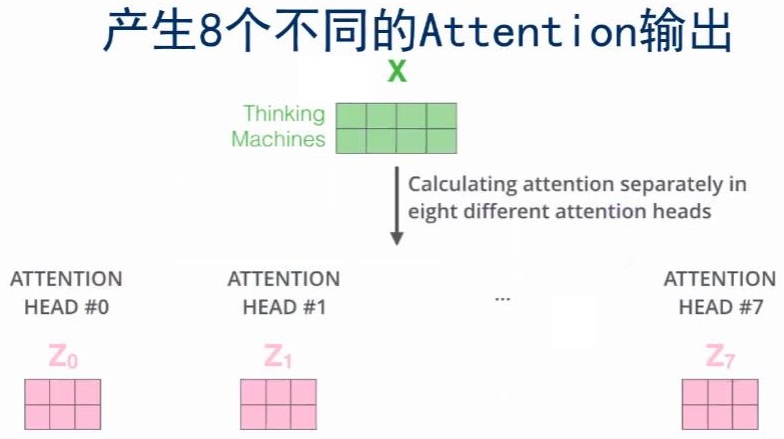
- Multi-Head Attention总结
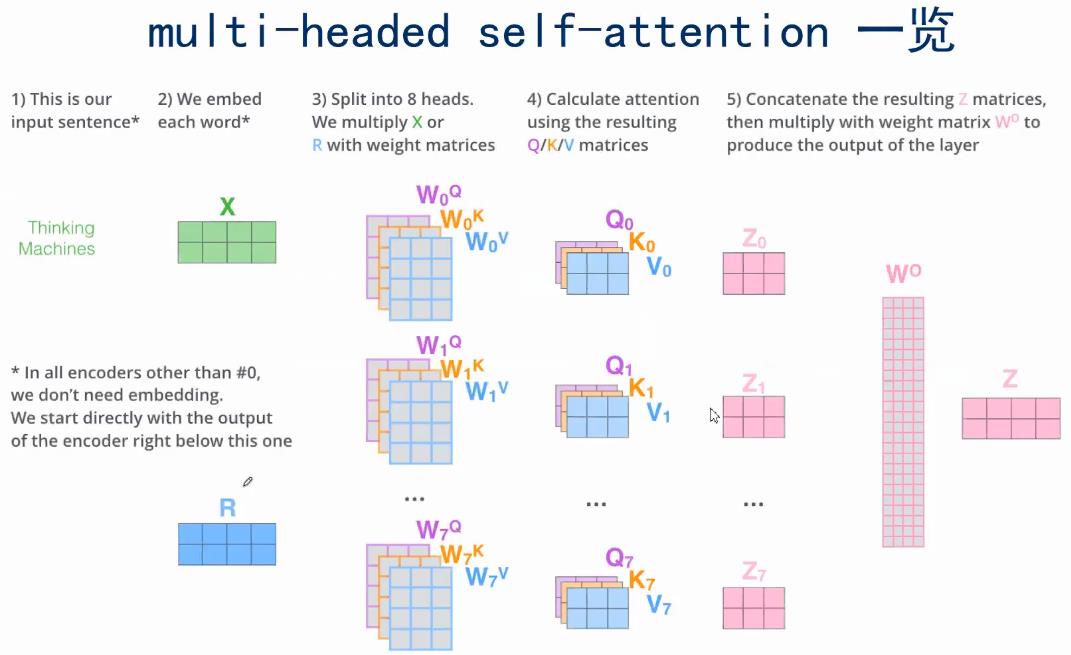

- 代码中的流程
代码
class Attention(nn.Module):"""Multi-head self-attention"""def __init__(self,dim, # 输入token的dimnum_heads=8, # multi-head中head的个数qkv_bias=False,qk_scale=None,attn_drop_ratio=0.,proj_drop_ratio=0.):super(Attention, self).__init__()self.num_heads = num_headshead_dim = dim // num_headsself.scale = qk_scale or head_dim ** -0.5self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop_ratio)self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop_ratio)def forward(self, x):# [batch_size, num_patches + 1, total_embed_dim]# +1是因为class tokenB, N, C = x.shape# qkv(): -> [batch_size, num_patches + 1, 3 * total_embed_dim]qkv = self.qkv(x)# reshape: -> [batch_size, num_patches + 1, 3, num_heads, embed_dim_per_head]# reshape相当于把qkv和多head分离开来# 其中embed_dim_per_head == head_dim == C // self.num_headsqkv = qkv.reshape(B, N, 3, self.num_heads, C // self.num_heads)# permute: -> [3, batch_size, num_heads, num_patches + 1, embed_dim_per_head]# 这一步用来调整维度顺序qkv = qkv.permute(2, 0, 3, 1, 4)# q.shape = [batch_size, num_heads, num_patches + 1, embed_dim_per_head]# 分别拿到q、k、vq, k, v = qkv[0], qkv[1], qkv[2]# softmax(QKt/根号下dk)# 矩阵乘法@ -> [batch_size, num_heads, num_patches + 1, num_patches + 1]attn = (q @ k.transpose(-2, -1)) * self.scaleattn = attn.softmax(dim=-1)attn = self.attn_drop(attn)# @ -> [batch_size, num_heads, num_patches + 1, embed_dim_per_head]x = (attn @ v)# transpose: -> [batch_size, num_patches + 1, num_heads, embed_dim_per_head]x = x.transpose(1, 2)# reshape: -> [batch_size, num_patches + 1, total_embed_dim]# 这一步就是拼接multi-head的结果x = x.reshape(B, N, C)# x = xW0x = self.proj(x)x = self.proj_drop(x)return x
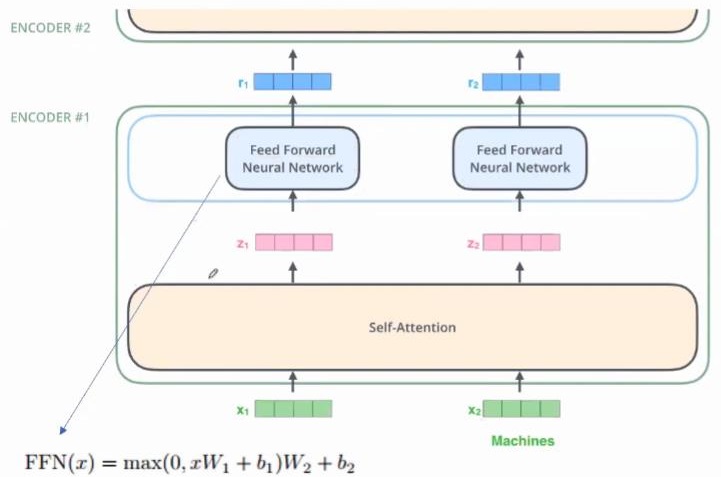
5 Encoder-Block: MLP Block
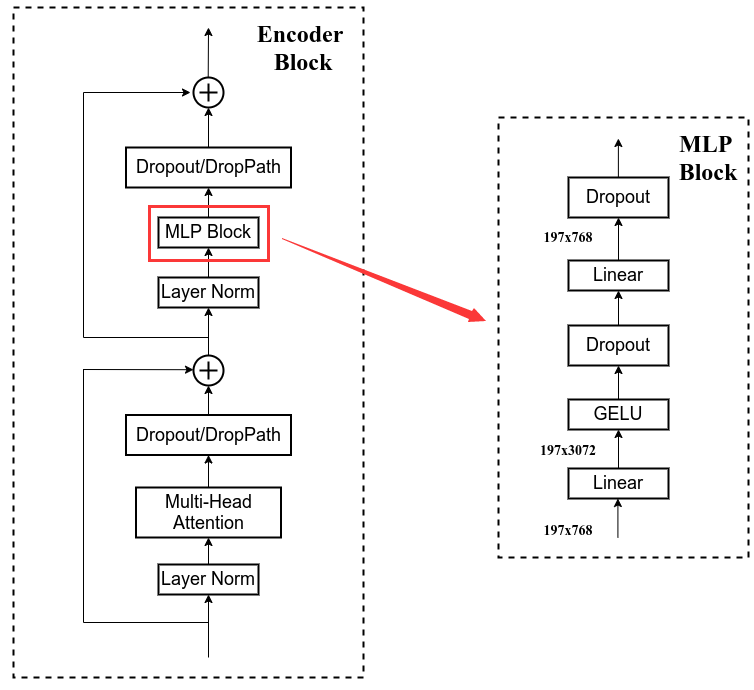
代码
class Mlp(nn.Module):def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = nn.Linear(in_features, hidden_features)self.act = act_layer()self.fc2 = nn.Linear(hidden_features, out_features)self.drop = nn.Dropout(drop)def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return x

若有收获,就点个赞吧
0 人点赞
