前言:从直击现场(copy)开始
记忆还停留Gradient descent理论,停留在数行代码手写出的线性回归![3U(]BK(%L67XQ8KK$JR}~KH.png](/uploads/projects/openlab2020@ai/11511deb3d5743df30dc8e2929e25a23.png) ,从手写细节开始,于是“吴恩达”最后就进了我的收藏夹吃灰。
,从手写细节开始,于是“吴恩达”最后就进了我的收藏夹吃灰。
这次,则是从直击现场的实践开始……
实验0:用多层全连接拟合一条二次曲线
问题1:什么是激活函数?
无激活函数时,输出都是输入的线性函数;
为了使非线性的函数被拟合,需要在传播中加一个激活函数,引入非线性因素。
激活函数有
Sigmoid函数:  (似乎常用于分类,据说有很多缺点现在不用了)
(似乎常用于分类,据说有很多缺点现在不用了)
Rule函数:  (常用,本实验用的就是这个)
(常用,本实验用的就是这个)
Leaky ReLU函数 
问题2:为什么不加激活函数多层全连接的输出一直是直线?
不加激活函数时,实际上是做了多次矩阵乘法,这样就会导致一直是线性映射,一直输出的是直线。
探索1:梯度下降在神经网络里是怎么工作的?
每次,通过损失函数我们可以计算出一个loss(是正数),这个loss是关于参数的函数。
显然loss接近0(最小)是我们想要的,我们就用梯度下降实现这个目标。
我们可以让loss对参数求梯度(对每个参数叫求偏导,对参数向量叫求梯度),从而求出在目前参数处loss的变化趋势,我们向着下降的趋势走,不就可以下降到最小了吗?(虽然并不是这么简单hhh)
在pytorch的世界里,求梯度是通过反向传播实现的。参数向量(tensor)每次参与一次计算,我们的tensor.grad就记录下来了这次计算的梯度,最后,使用反向传播(tensor.backward),我们让这些梯度都乘到了一起,就求出了总的梯度。 ,记得一般用的公式好像大概是这样的……这样就按照梯度的大小与方向进行了“梯度下降”。
,记得一般用的公式好像大概是这样的……这样就按照梯度的大小与方向进行了“梯度下降”。
探索2:其他函数的尝试
 的情况:
的情况: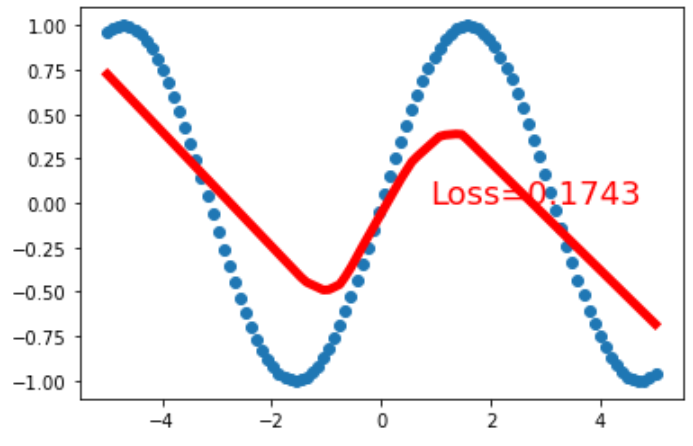 (epcho=300,显然效果不好)
(epcho=300,显然效果不好)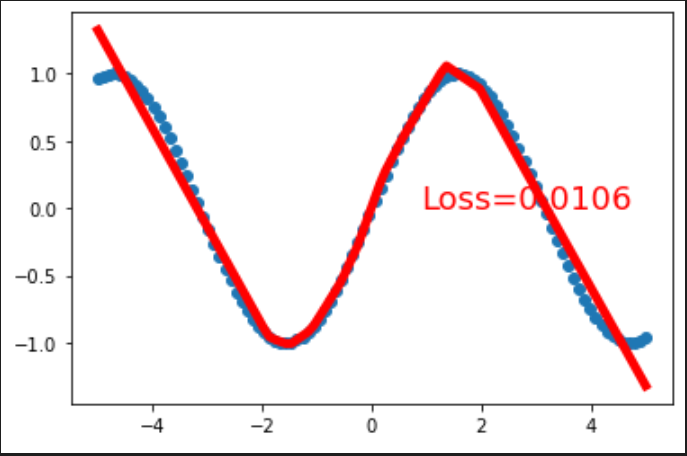 (epcho=30000,好多了,但好像偏向两侧的部分太直了?)
(epcho=30000,好多了,但好像偏向两侧的部分太直了?)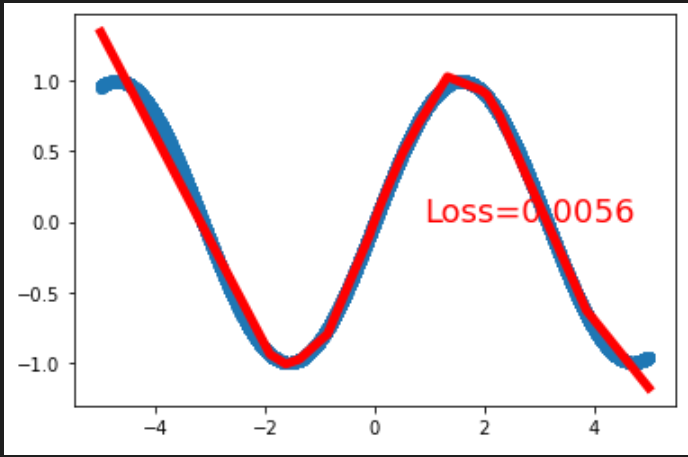 (epcho=30000,并且样本数为原来的100倍,发现略有提升,但提升不大)
(epcho=30000,并且样本数为原来的100倍,发现略有提升,但提升不大)
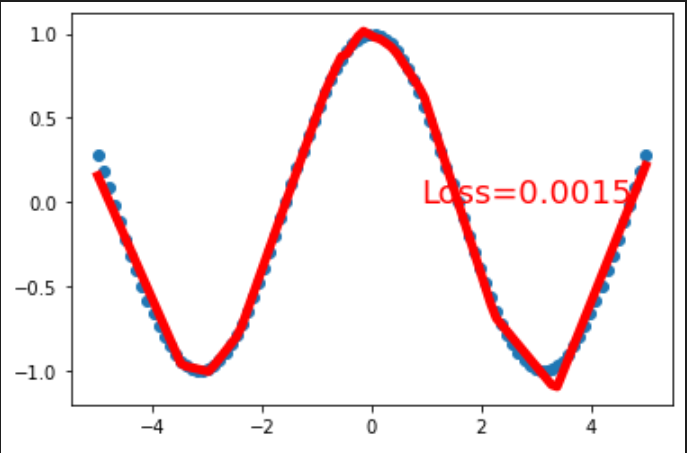 (epcho=30000,确实两边会太直,不知道为什么)
(epcho=30000,确实两边会太直,不知道为什么)
结论:唯一的收获,多训练几轮,一般就会好很多了2333

若有收获,就点个赞吧
0 人点赞
