花了一些时间理解了全连接网络的东西,改了改实验0,先占个位置,长期更新
实验0
问题回答
注意!这里会给出问题答案,如果你想独立完成,请略过答案部分,如果你卡了,看完之后也请自己仔细思考
问题1
这个问题要从神经元模型说起,神经元接受n个输入,并给出一个输出,n个输入乘以权值并累加。也就是如下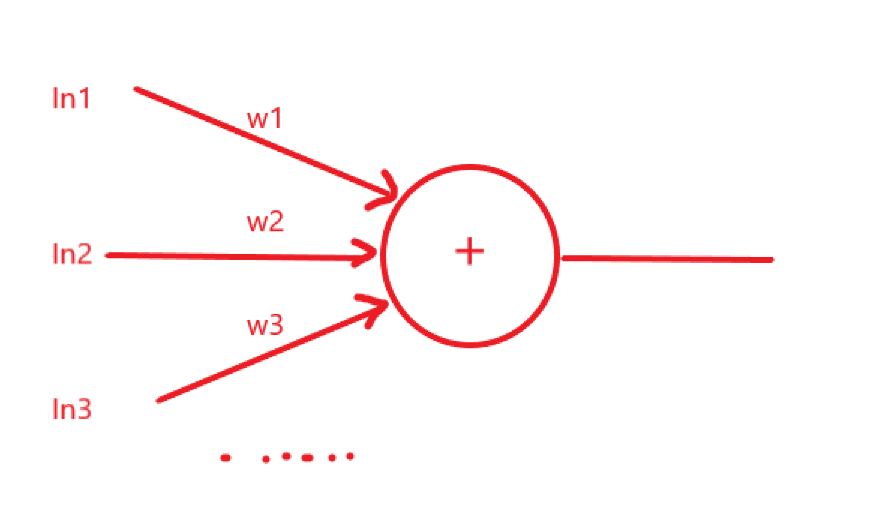
这里计算的输出为 (这里的b为偏置,是一个常数)
(这里的b为偏置,是一个常数)
以模拟真实的神经元(复习高中生物,一个神经元可能被多个神经末梢连接,又可能连接着多个神经元,以突触传递电位)
然而,直接这样加起来有点太暴力了(全是线性变换),而且现实中的神经元也是在某种条件下才活跃(被激活)所以这里加入激活函数。
(下面出现答案)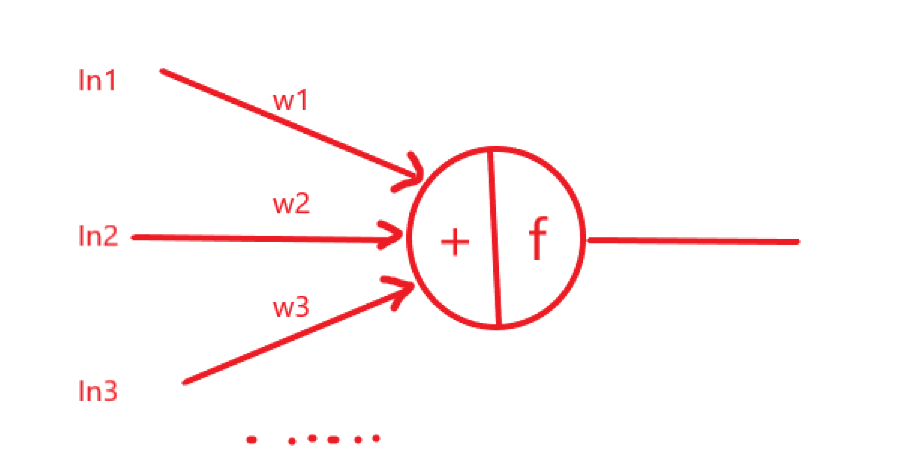
引入函数 ,这样,我们的输出就是
,这样,我们的输出就是
实际上,激活函数在神经网络中起到将非线性引入神经网络的作用。因为通过上面计算Sum的公式我们可以看到,输入之间的变换全都是线性的,即使再加上几层神经网络、多几个神经元,还是线性的(线代课上应该讲过)。
这个实验我们使用的激活函数十分简单但非常有效,即ReLU,它的函数表达式为
x小于零函数值为0,x大于0函数值为其本身。
问题2
如果了解了激活函数,那么这一问就十分简单了,首先我们看神经网络模型,我们希望拟合 那么,神经网络输入是一个数(一维向量),输出也是一个数(一维向量)(理想情况下这个数是输入的平方)
那么,神经网络输入是一个数(一维向量),输出也是一个数(一维向量)(理想情况下这个数是输入的平方)不要被学长一次生成100个数据骗了其实那个100是batch_size即一次处理多个输入数据。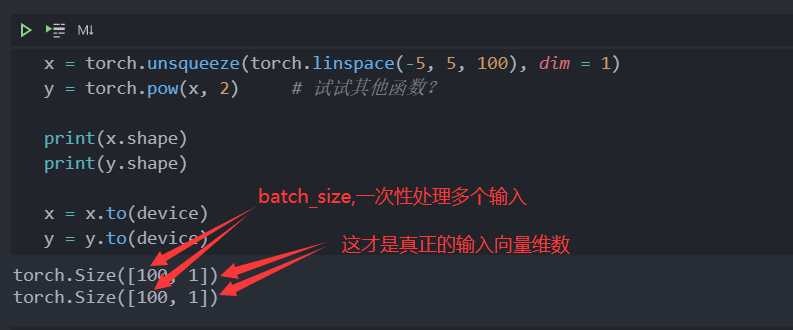
再看我们的神经网络,它有两个hidden组成(虽然我觉得hidden2是输出层)
如果你理解了全连接,那么你应该了解,每一层的输入向量维数是上层的神经元数(或者说输入向量维数)而输出向量维数是本层神经元数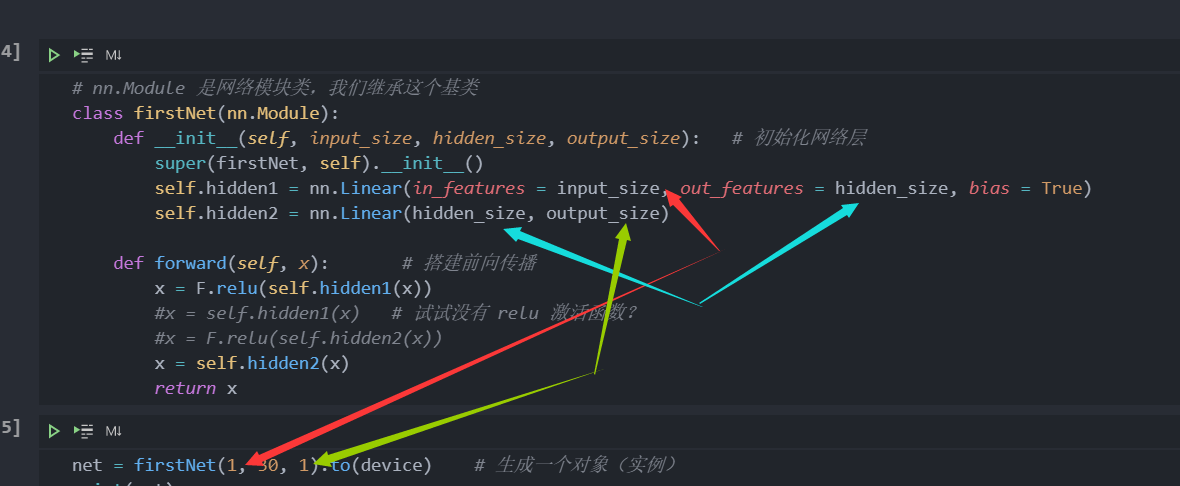
图示:(画渣)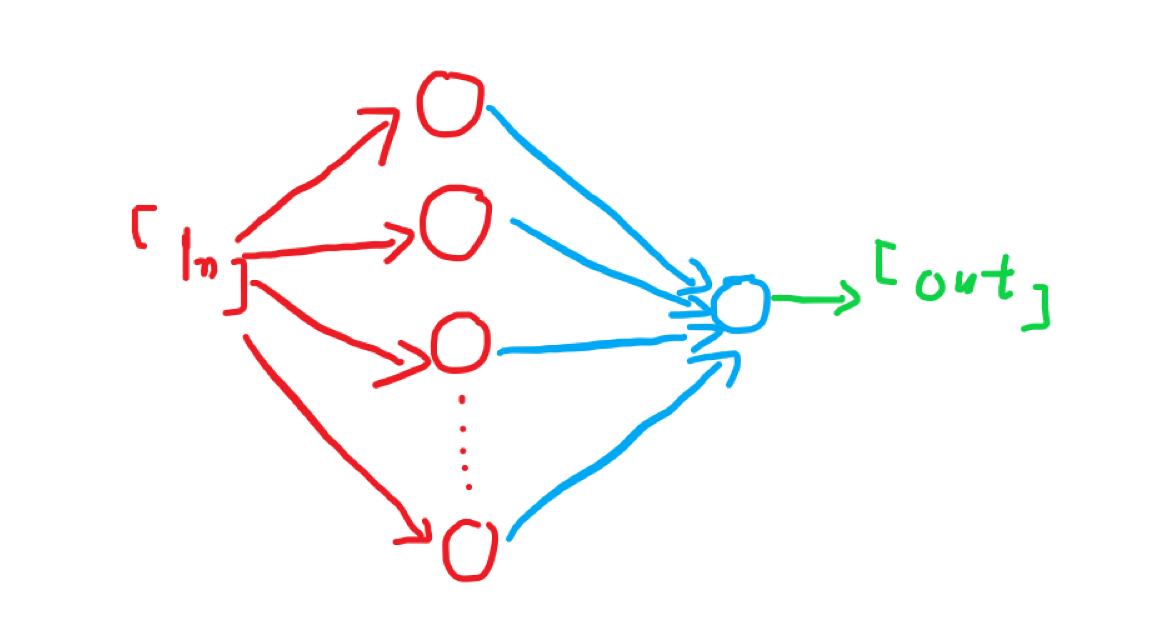
为什么要花这个?我们看上一问的公式
(下面出现答案)
_如果没有激活函数!!!**
对于第一层的输出(二层输入)

而对于

我们对In做了两次线性变化,不明白?展开!

等等,我们把In的系数提出来,加在一起,发现,这TM不就是 吗???无论你权值偏置怎么变化,都是个线性的,一条直线的方程,那怪不得是一条直线了。
吗???无论你权值偏置怎么变化,都是个线性的,一条直线的方程,那怪不得是一条直线了。
爆改一些东西
用CPU炼丹,那是肯定不行的
通过后面几个实验,大家也可以发现,为了让大家炼丹炼化的快一点,学长的代码贴心的帮大家根据是否能够使用cuda选择了炼化模型的设备(cuda
or cpu)那么使用GPU炼丹需要改些啥东西呢(
这一行是用来选择device(一个字符串的)如果你的显卡有cuda加速,就给你用GPU炼丹,要不然的话就乖乖用CPU吧。
那么要改哪些呢(
首先。模型要放到GPU上去
你觉得这就行了?一跑,报错
这是因为GPU有自己的“主存”,也就是传说中的显存,GPU实际上也是一堆运算单元封装在一起,有自己的总线、存储,它与CPU不同的是,它有大量仅能做简单重复计算工作的单元,例如浮点运算,进行大量浮点运算时要比CPU快很多,但是CPU更具备通用性,功能更多。
显存一般来说板载在显卡上(焊死)并不能扩充。
这也是大显存更适合DL的原因之以——更大的现存能存储更多的数据,就能开更大的batch_size,一次处理更多的数据而不用一直从内存Load。
那么我们训练用的数据、计算损失的数据、验证用的数据都需要扔到GPU上去。

实验1
就冲着题目的函数图像,外星人也知道这是正态分布了
直接开始探索。
探索
探索1
(话说Loader和Set不是下面题目的问题吗,为啥这就来了)
Dataset就是数据集(直译)它时一堆标记好数据的集合(训练集、测试集都可以),它负责直接打开一个文件,读取数据(所有的)
DataLoader可以将Dataset按照batch_size分成多个批便于神经网络分批处理,另外,它还是可以迭代的,方便网络训练。
探索2


实验3
???Ag2S你怎么直接跳到实验三了???你前面的东西呢?
其实也看了,但是实验三好玩,而且可以动手搭网络,所以直接上了。
网络模型
如下
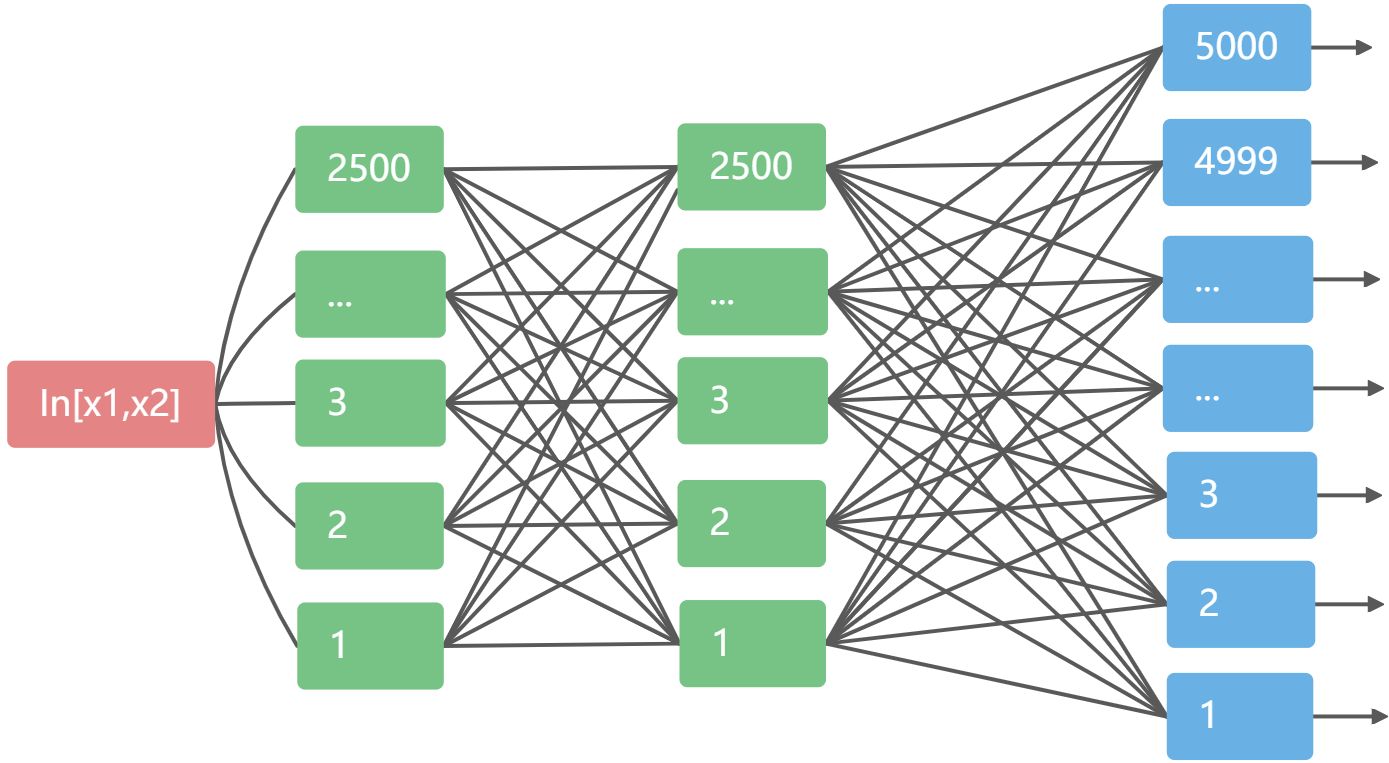 别问,问就是摸索出来的,三层全连接网络网络,
别问,问就是摸索出来的,三层全连接网络网络,hidden_size=2500,输入输出按照题目给的来。
激活函数用的都是RELU。
训练和各种参数
(内含代码,想完全独立完成请做完或卡了再看)
好了,模型构建好了,写好代码,欢欢喜喜的准备训练。
那么有几个参数就要确定下来:learning_rate optimizor epochs criterion
第一个是学习率的,刚开始炼还不懂,看前面的比这抄了抄,先来了个5e-3训练到后面震荡太大了,然后用了几个不同的试了试,最后用了2e-4,然后optimizor使用的是SGD(照抄前面的)criterion用的是交叉熵MSELoss。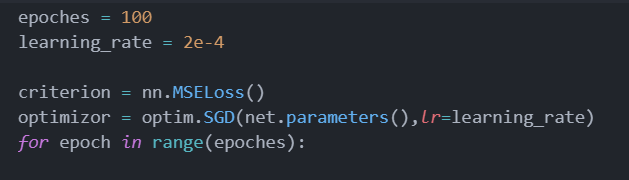
然后开始训练,epochs 先定的30,后面改成六十如果不太好的话后面还可以继续训练,果然,需要训练好几轮。大概来了200多次训练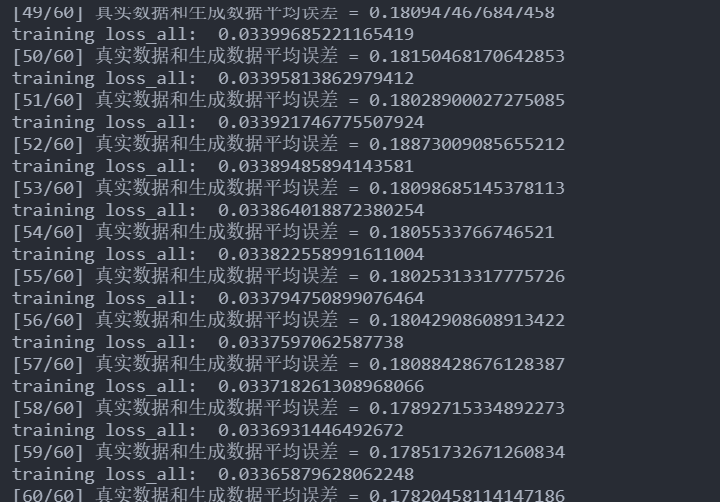
嗯,训练集上0.03-0.04左右,测试集上0.2以下,模型收敛的又快又好(
好个头,这已经慢到不能再慢了,这样下去那是肯定不行的,那么我们就要开始寻找优化器是什么、学习率又是什么了。**
WTF is lr
如果你已经理解了梯度下降,那么学习率其实就没有什么难解释的。
我们知道,在神经网络中,连接输入、输出、和神经元之间的东西叫权值也就是
下面直接给出公式:
新的权值为旧权值减去学习率与梯度的乘积
这里的梯度是一个偏导,我们知道输出(和算是函数)都是一个关于权值的函数(在全连接中,这不难证明)我们需要在训练中不断修正权值使得损失函数越小越好,那么梯度可以看作是损失函数对每个权值求的偏导数(这个过程是用反向传播法完成的)。
那么我们只要顺着导数往下走,就总会找到一个极值点(局部的最优解)而这个 可以看作“步幅”。
可以看作“步幅”。
如果过大,会发生什么?前期很舒服,模型收敛的很快,但是后面呢?接近极值点,步幅却越来越大,会产生震荡现象。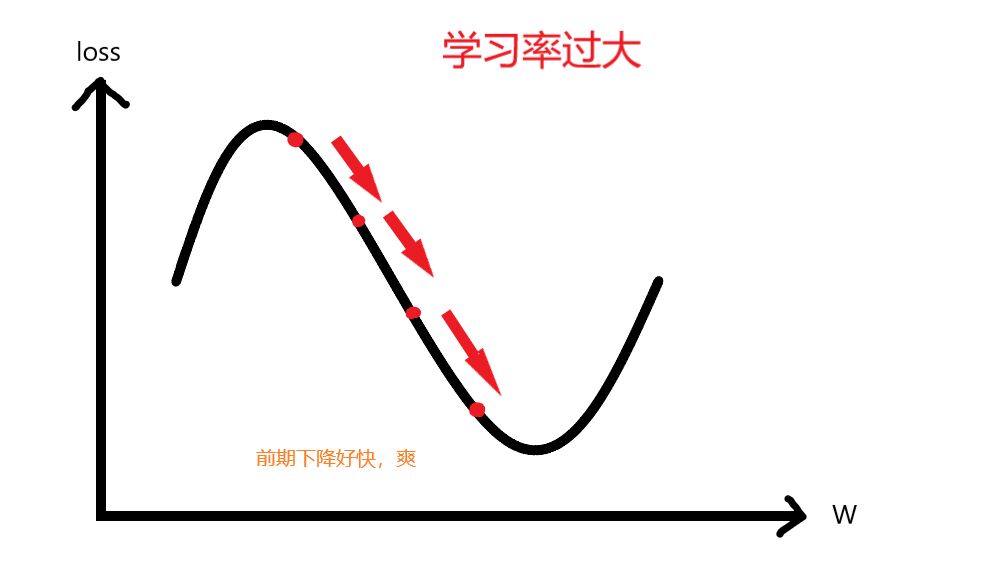
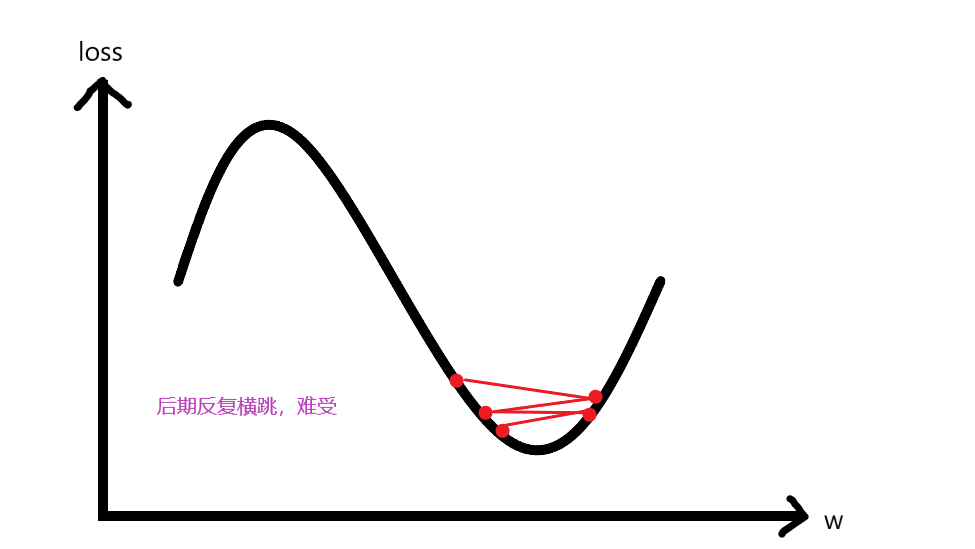
而如果学习率过小,则有可能产生的问题是:下降过慢、而且被困鞍点不能自拔。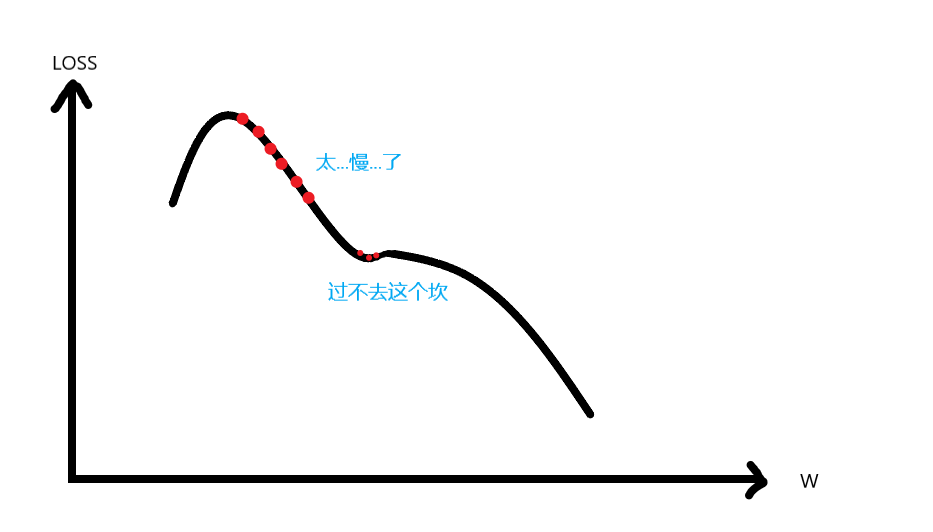
实际训练时,一般在开始阶段选取比较大的,而在后期将其减小,且一般在0.01-0.001
调整学习率训练
这里我选择比较粗暴的方法,学习率初始为0.1,然后不断减半,到0.001(实际上,在最后几段训练过程中,学习率甚至会小到原来的百分之一)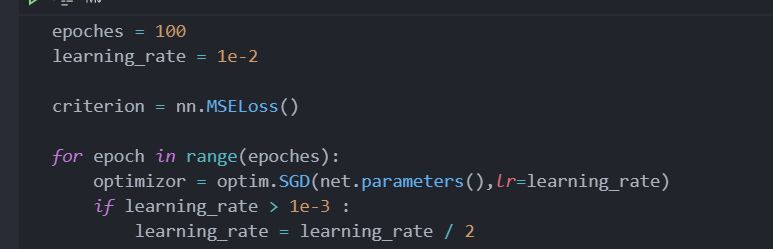
此时再进行训练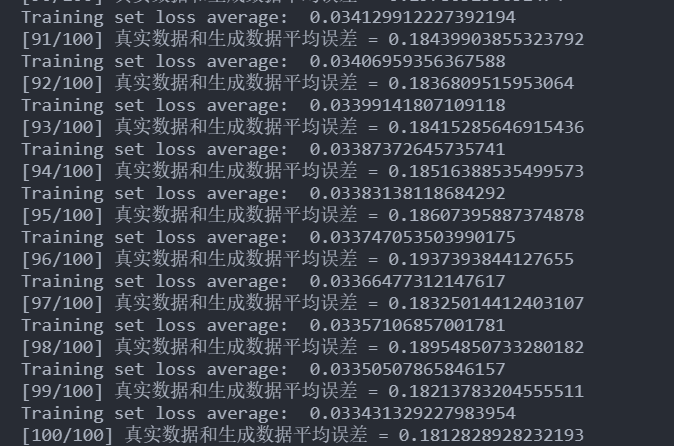
嗯,这次快多了而且能收敛到一个不错的值上。
好家伙,全连接到底有啥特征
全连接网络依靠着激活函数,线性组合大量非线性函数,依靠损失函数评价模型好坏,依靠梯度下降和反向传播不断优化模型。全连接网络实质上的作用就是对目标函数的拟合。
但是,全连接网络十分依赖数据,在训练集范围内的数据,它可以轻松的给出较优解,而出了训练集,它就不认识了比如你看第实验零,我们在 上训练,结果十分优秀,但是一旦数据范围超过这个,损失函数就直接爆炸了。
上训练,结果十分优秀,但是一旦数据范围超过这个,损失函数就直接爆炸了。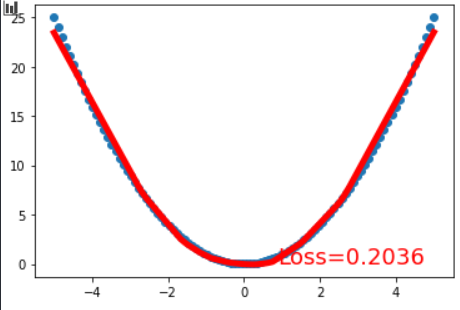
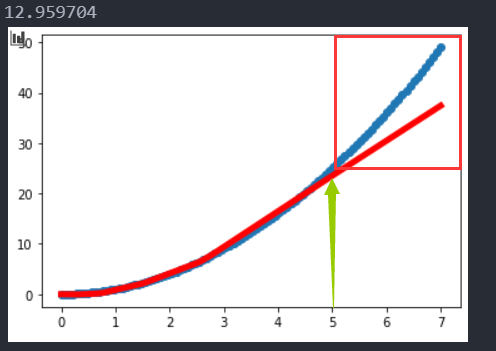
而且它还存在过拟合问题(不过在函数拟合方面,这倒是和好事情)
不排序会发生?
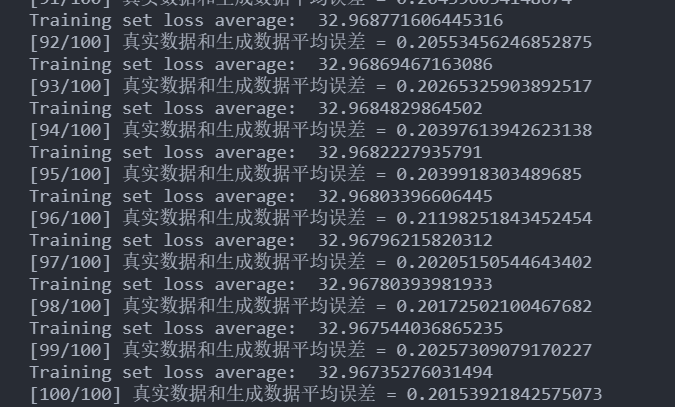
很奇怪,在测试集上收敛的勉强还行(不如带有sort的)但是在训练集上的平均误差却极大。
这是啥情况,画出来图看看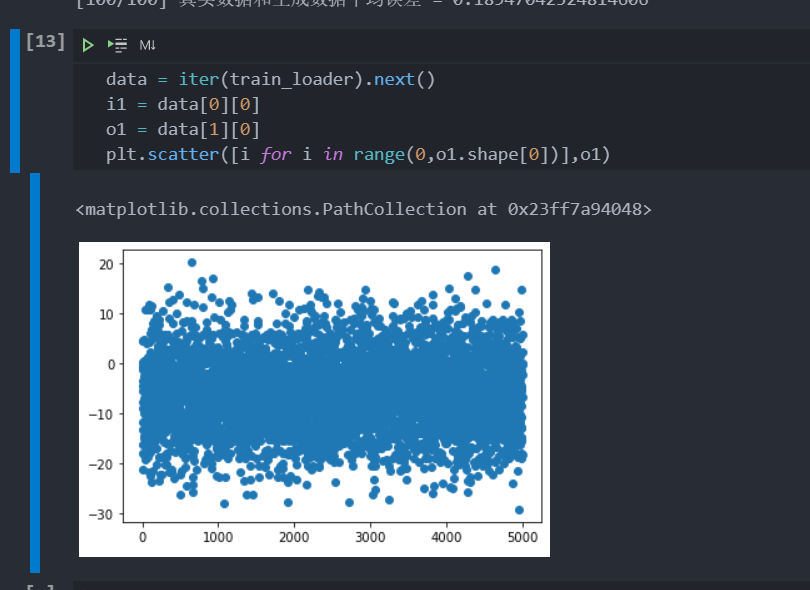
WTF……
Sort 下(图二带有神经网络生成的)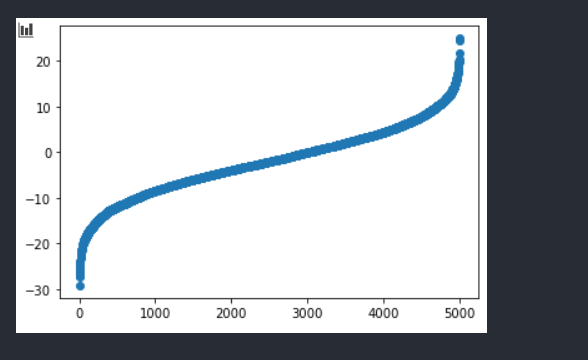
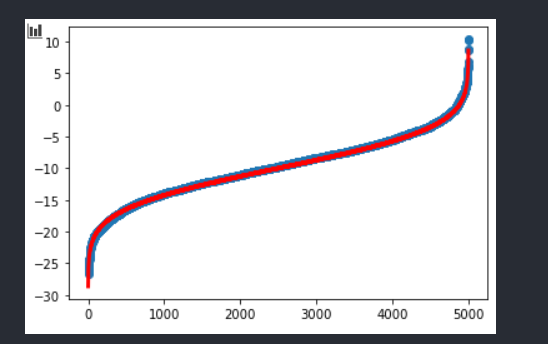
好多了……
那么不sort会发生?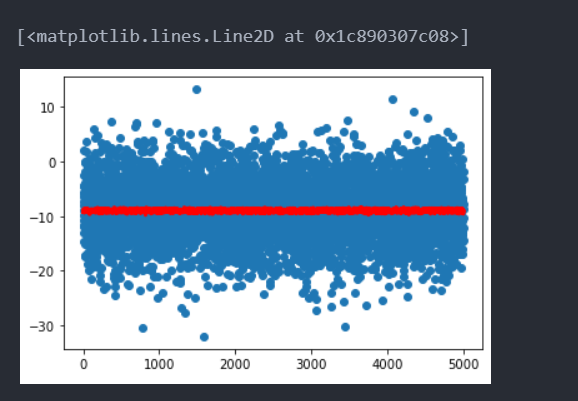
好家伙,因为训练数据为了让交叉熵小一点,直接取所有这些所有点的均值点生成了……

若有收获,就点个赞吧
0 人点赞

{kind=link}
{kind=link}
{kind=link}