激活函数:
全连接神经网络分为输入层、隐藏层与输出层。激活函数存在于隐藏层中,而激活函数则是在神经网络中引入非线性特征。常用的函数主要有:


全连接层与线性相关:
每一个输入层会与每一个输出层进行连接,一共有输入层个数*输出层个数个连接,而连接写为矩阵的形式为: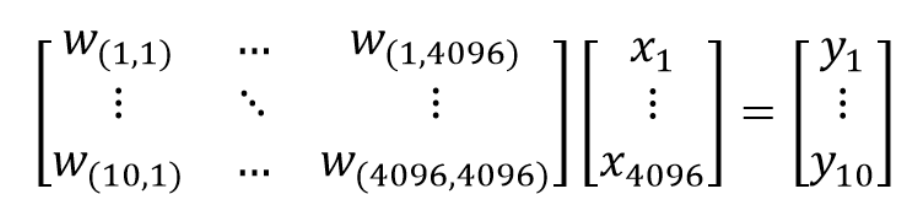
即全连接层中输出层的每个元素在没有激活函数的情况下都是由输入层经过线性运算来完成的。计算都是通过简单的加法与乘法运算来进行的。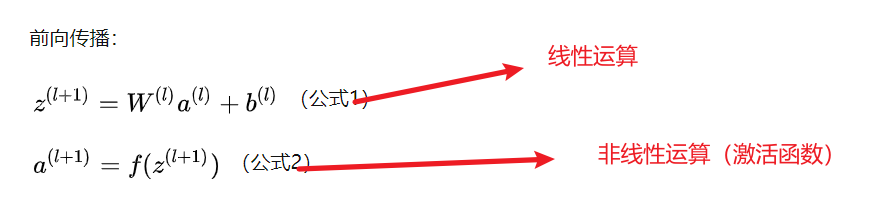
梯度下降:
在训练全连接层时,我们需要对将损失函数下降到最小值。假设损失函数与两权值的函数关系如下图所示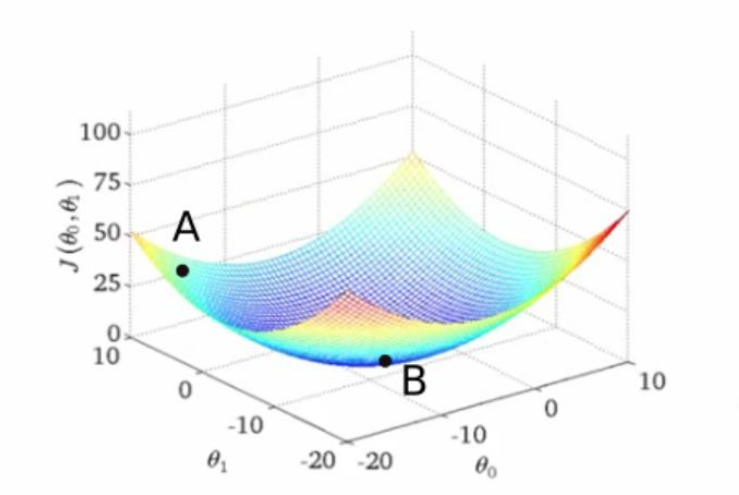
我们训练神经网络的目的则就是将损失函数的值由当前位置(A)下降到最低点(B)。而我们在寻找最低点(B)时首先要从当前位置(A)的xy平面找到的所有可能方向,在所有可能方向上找到损失函数下降坡度最为陡峭的地方。而这个梯度最为陡峭的方向与梯度(高阶导数的另一种说法)的方向相反。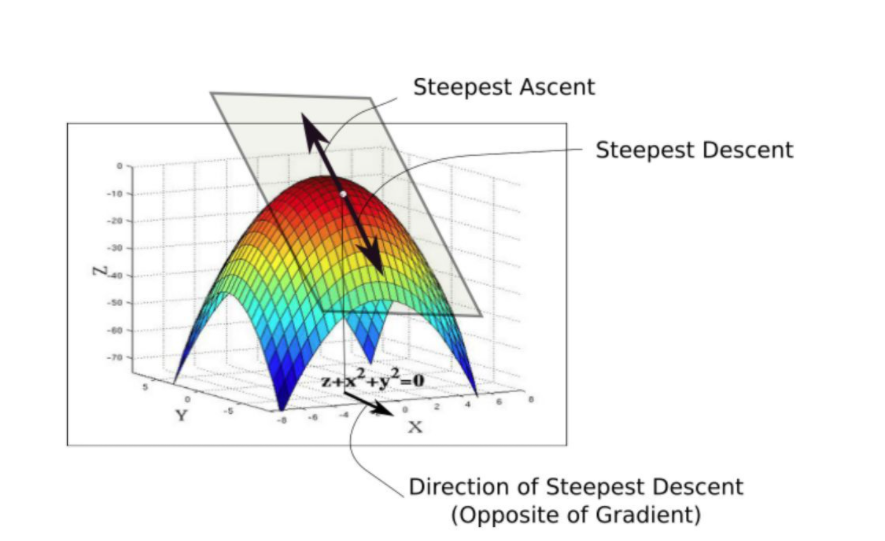
如上图所示,我们在一个三维平面上可以找出一个与其相切的平面,我们通过对此三维平面的函数进行求导操作,当求出该相切平面上的梯度方向后其反方向也就是改平面下降的最陡峭的方向。
在选择好梯度下降的方向后,我们需要确定采取步子的大小,而控制下降步幅大小的参数即学习率。为了保证降到最小值,我们必须谨慎地选择学习率。过快的学习率可能会导致越过最小值。如果移动太慢,训练可能花费太长的时间,也容易让算法陷入极小值。到达下一个点后再重复上述操作,(当到达最低点时梯度为0)。
一般情况下梯度下降过程为上图所示,当下降到一定程度后会在最小点附近震荡。
梯度下降主要面临的问题:局部最小点、鞍点。(因为梯度下降的最终结果是找到梯度为0的点)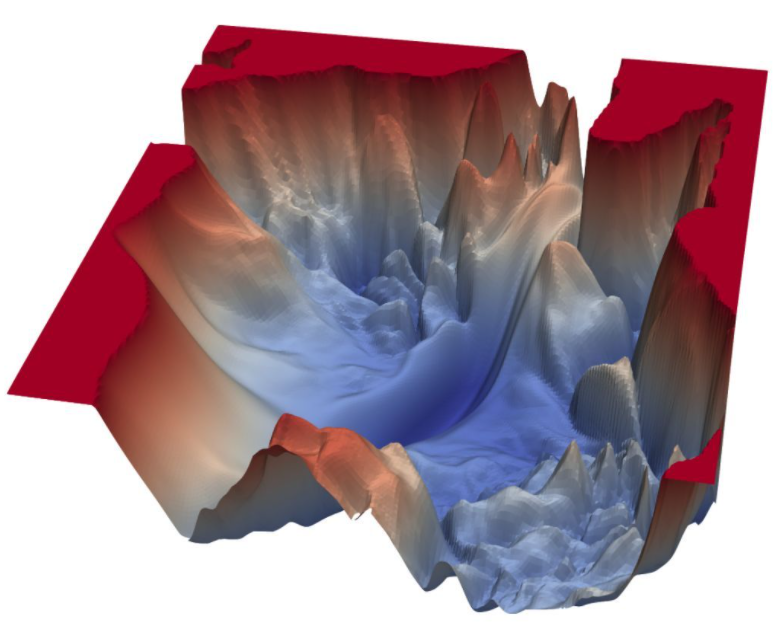
(局部最小点)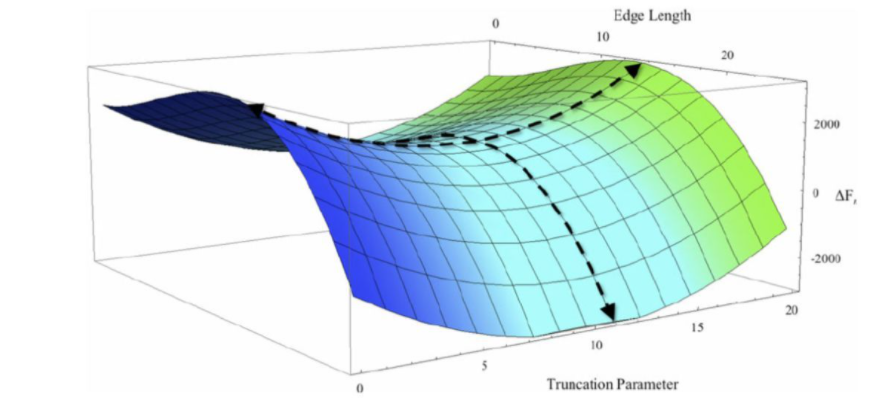
(鞍点)
而解决上述两问题的方法则是使用批梯度下降。即我们使用固定数量(例如 16、32 或者 128 个)的样本形成一个 mini-batch 来构建损失函数,而不是使用整个数据集或者单个样本。选择mini-batch 的大小是为了保证我们有足够的随机性摆脱局部最小值,同时可以利用足够的并行计算力。
反向传播算法:
- 先看对矩阵的求导:


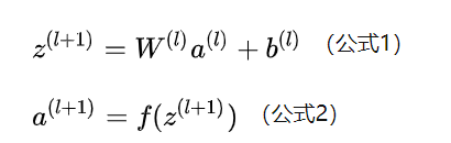

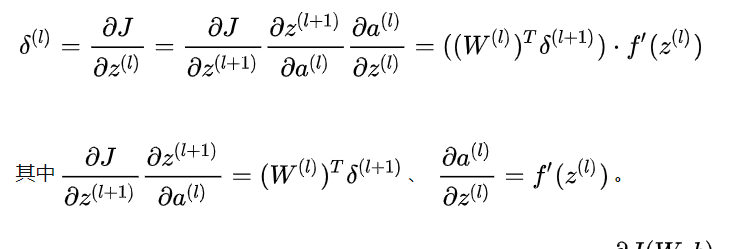


函数:
二次函数: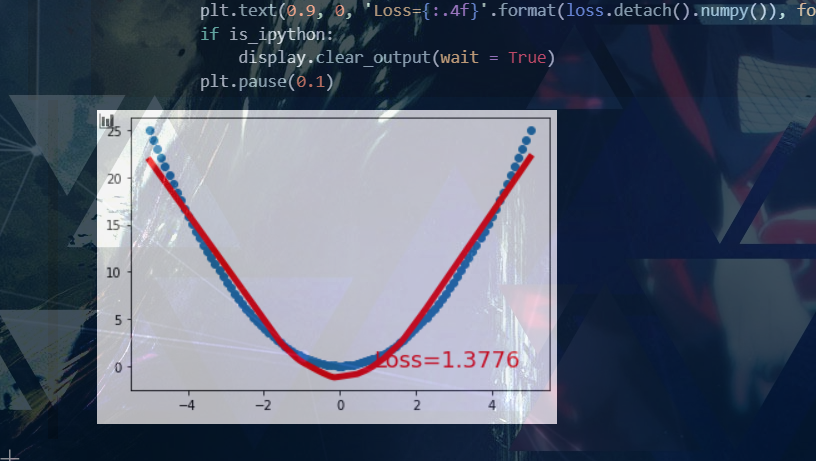
三次函数: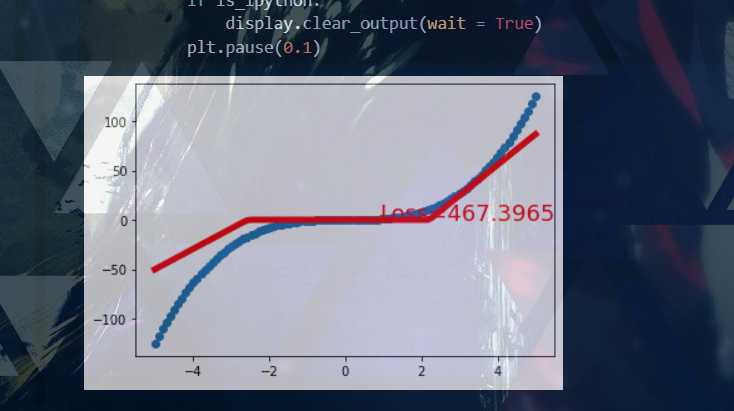
可能是因为损失函数,优化器选择,学习率大小出现了问题。
Dataset 与 dataloader:
Dataset是一个包装类,用来将数据包装为Dataset类,然后传入DataLoader中,我们再使用DataLoader这个类来更加快捷的对数据进行操作。
Code1分布及约束:
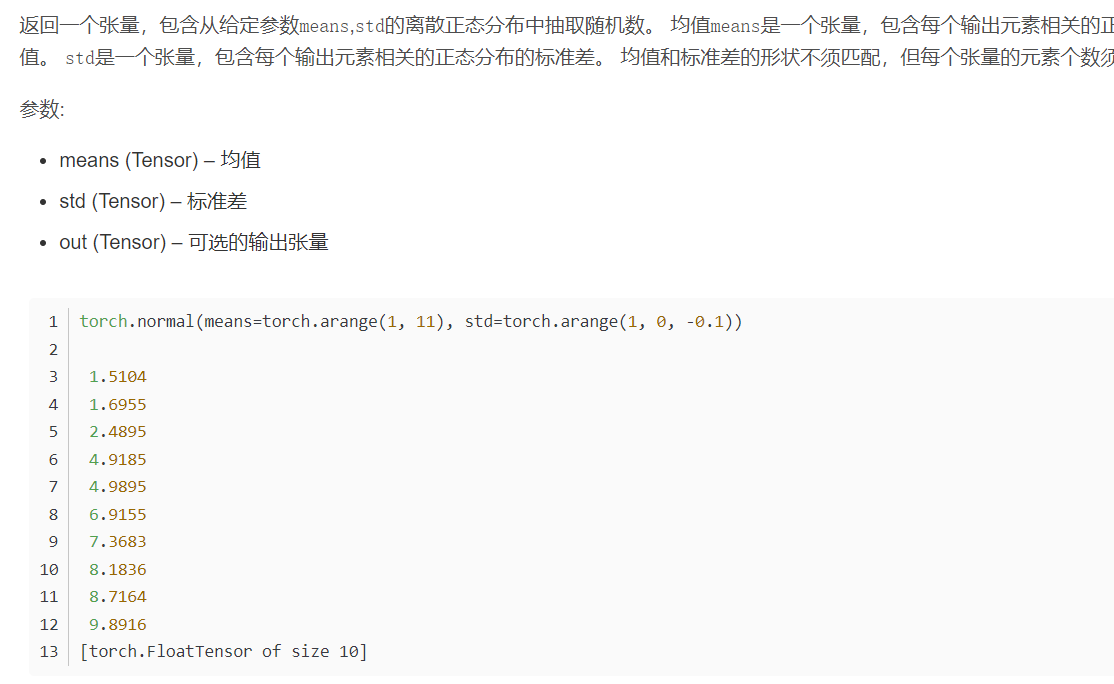
Sigmoid():
是一个激活函数,肯定不能去掉,去掉的话输入和输出就完全是线性相关关系了。
输出区别:
Batch_size问题:
如果全部投入会出现局部最小点与鞍点问题,如果过小会导致一次一个会导致运行速度过于缓慢。
数据规律:
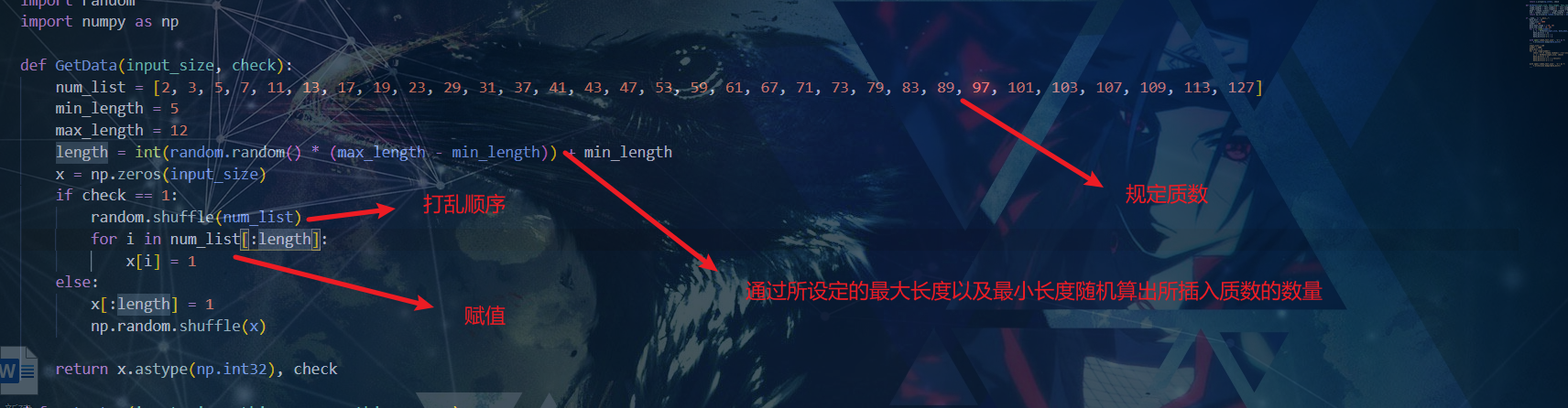
Softmax函数
即通过softmax的值来分析各点出现的概率,最终找出黑客滴代码~
Code3:
平均误差大了,阿巴阿巴……
但是只要epochs值足够大,我就可以无限缩,╭(╯^╰)╮(bushi)。具体问题我猜应该是调用的函数的问题,但具体是哪个函数也没再深究(因为ddl赶不完了啊啊啊啊啊)。
全连接网络的特性嘛,大概就是输入,隐藏,输出层,具体步骤大概就是:1.选择损失函数以及优化器。之后进入循环。2. 清空梯度 3.前向传播4.计算损失5.反向传播6.统计本轮的loss7.按照学习策略进行优化

若有收获,就点个赞吧
0 人点赞
