🎈开始的开始——查查看不懂的🌱
Epoch:使用训练集的全部数据对模型进行一次完整训练,被称之为“一代训练”。
当一个完整的数据集通过了神经网络一次并且返回了一次,这个过程称为一次>epoch。(也就是说,所有训练样本在神经网络中都 进行了一次正向传播 和一次反向传播 )
再通俗一点,一个Epoch就是将所有训练样本训练一次的过程。
实验0
🎡问题1 你明白什么是激活函数吗?
激活函数(Activation Function),就是在人工神经网络的神经元上运行的函数,负责将神经元的输入映射到输出端。激活函数(Activation functions)对于人工神经网络 模型去学习、理解非常复杂和非线性的函数来说具有十分重要的作用。
✨如果我们不运用激活函数的话,则输出信号将仅仅是一个简单的线性函数。线性函数一个一级多项式。现如今,线性方程是很容易解决的,但是它们的复杂性有限,并且从数据中学习复杂函数映射的能力更小。一个没有激活函数的神经网络将只不过是一个线性回归模型(Linear regression Model)罢了,它功率有限,并且大多数情况下执行得并不好。我们希望我们的神经网络不仅仅可以学习和计算线性函数,而且还要比这复杂得多。同样是因为没有激活函数,我们的神经网络将无法学习和模拟其他复杂类型的数据,例如图像、视频、音频、语音等。这就是为什么我们要使用人工神经网络技术,诸如深度学习(Deep learning),来理解一些复杂的事情,一些相互之间具有很多隐藏层的非线性问题,而这也可以帮助我们了解复杂的数据。
🎉问题2 为什么不加激活函数多层全连接的输出一直是直线? **
如果不使用激活函数,那么不管多少层的神经网络,y=wn⋯w2w1x=w¯xy=wn⋯w2w1x=w¯x,就都变成了单层神经网络,也就是说输出都变成了直线,所以在每一层我们都必须使用激活函数。
🎊
比如一个两层的神经网络,使用 A 表示激活函数,那么
y=w2A(w1x)y=w2A(w1x)
如果我们不使用激活函数,那么神经网络的结果就是
y=w2(w1x)=(w2w1)x=w¯xy=w2(w1x)=(w2w1)x=w¯x
🎆探索1 道理我都懂,可是梯度下降在神经网络里是怎么工作的?
在神经网络的训练中,通过梯度下降算法,求取每个参数的偏导数,更新参数实现反向传播以此来让我们的模型更能准确的预测问题。梯度下降主要用于在神经网络模型中进行权重更新,即在一个方向上更新和调整模型的参数,来最小化损失函数。反向传播技术是先在前向传播中计算输入信号的乘积及其对应的权重,然后将激活函数作用于这些乘积的总和。这种将输入信号转换为输出信号的方式,是一种对复杂非线性函数进行建模的重要手段,并引入了非线性激活函数,使得模型能够学习到几乎任意形式的函数映射。然后,在网络的反向传播过程中回传相关误差,使用梯度下降更新权重值,通过计算误差函数E相对于权重参数W的梯度,在损失函数梯度的相反方向上更新权重参数。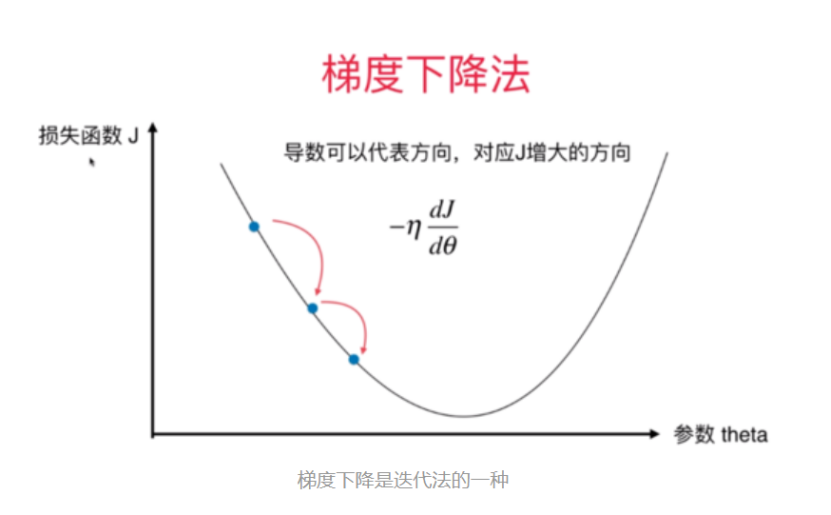
🎠探索2 就一个二次函数有啥意思啊,试试其他函数!、
(1)y=x^3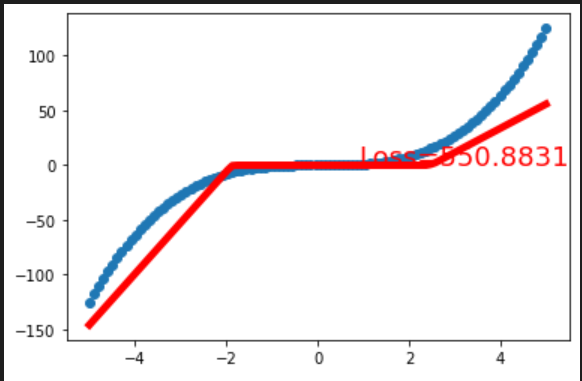
(2)y=2^x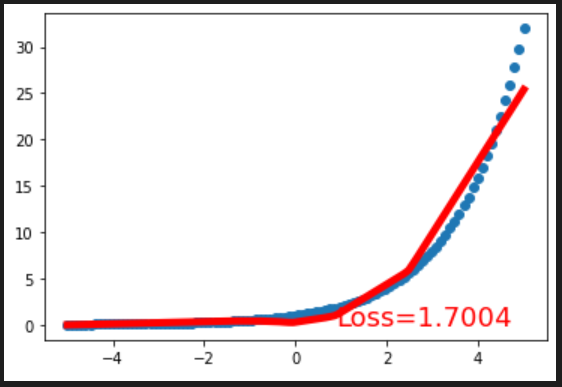
(3)y=cos x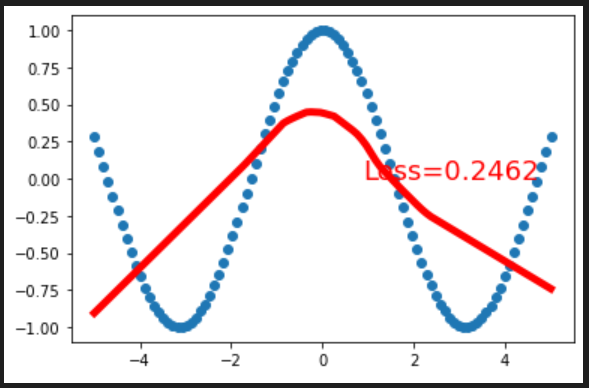
(4)y=tan x **?????
实验1
🎏探索1 对 Dataset 和 DataLoader 很好奇?他们是什么?
DataLoader和Dataset是pytorch中数据读取的核心,
Dataset是一个抽象类,需要派生一个子类构造数据集,需要改写的方法有init,getitem等。
DataLoader是一个迭代器,方便我们访问Dataset里的对象
🎇探索2 你发现这个数据分布是什么分布了吗?那你知道这个分布的这两个约束该怎么求吗?
正态分布
实验2
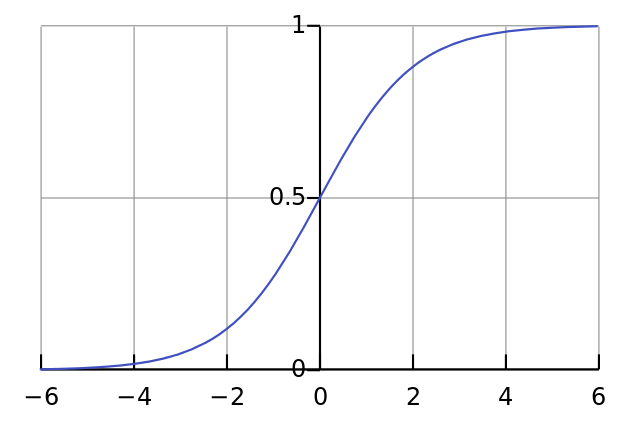
🍵问题1: Sigmoid() 是什么?不加这个东西可以吗?
sigmoid函数也叫Logistic函数,用于隐层神经元输出,取值范围为(0,1),它可以将一个实数映射到(0,1)的区间,可以用来做二分类。在特征相差比较复杂或是相差不是特别大时效果比较好。Sigmoid作为激活函数有以下优缺点:
优点:平滑、易于求导。
缺点:激活函数计算量大,反向传播求误差梯度时,求导涉及除法;反向传播时,很容易就会出现梯度消失的情况,从而无法完成深层网络的训练。
应用:logistic函数在统计学和机器学习领域应用最为广泛或者最为人熟知的肯定是逻辑回归模型了。逻辑回归(Logistic Regression,简称LR)作为一种对数线性模型(log-linear model)被广泛地应用于分类和回归场景中。此外,logistic函数也是神经网络最为常用的激活函数,即sigmoid函数。
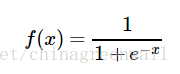
🍿添加 Sigmoid()函数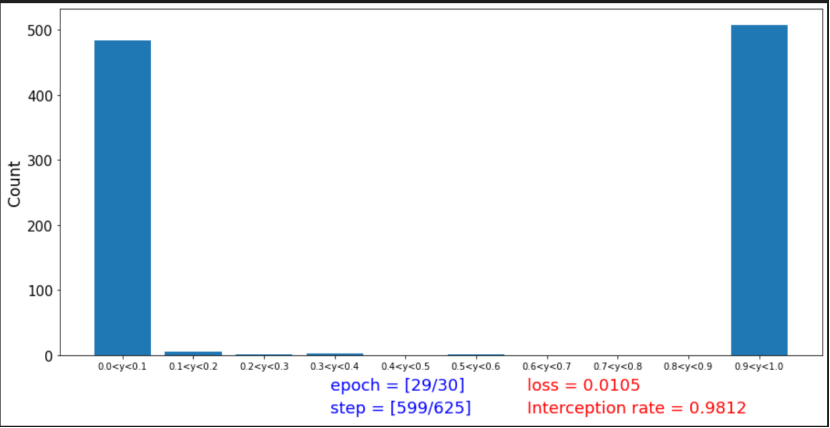
🍕删去Sigmoid()函数

🍨问题 2: 你发现实验 1 和 实验 2 之间任务输出的区别了吗?
实验一的输出是两个约束数字是离散的;实验二的输出拦截率的变化是连续的。
🍟问题 3: 为什么一次要把一个 batch_size 的数据投进去训练,一次1个不行 吗,一次全部不行吗?
(1)Batch_Size 太小 收敛太慢,算法在 200 epoch 内不收敛。
每次只训练一个样本,即 Batch_Size = 1。这就是 在线学习(Online Learning)。线性神经元在均方误差代价函数的错误面是一个抛物面,横截面是椭圆。对于多层神经元、非线性网络,在局部依然近似是抛物面。使用在线学习,每次修正方向以各自样本的梯度方向修正,横冲直撞各自为政, 难以达到收敛。
(2)盲目增大 Batch_Size 有何坏处?
- 内存利用率提高了,但是内存容量可能撑不住了。
- 跑完一次 epoch(全数据集)所需的迭代次数减少,要想达到相同的精度,其所花费的时间大大增加了,从而对参数的修正也就显得更加缓慢。
- Batch_Size 增大到一定程度,其确定的下降方向已经基本不再变化。
(3)最优化结果——在合理范围内,增大 Batch_Size 有何好处?
- 内存利用率提高了,大矩阵乘法的并行化效率提高。
- 跑完一次 epoch(全数据集)所需的迭代次数减少,对于相同数据量的处理速度进一步加快。
- 在一定范围内,一般来说 Batch_Size 越大,其确定的下降方向越准,引起训练震荡越小。
(4)补充: 批梯度下降法(Mini-batches Learning)。因为如果数据集足够充分,那么用一半( 甚至少得多)的数据训练算出来的梯度与用全部数据训练出来的梯度是 几乎一样的。

若有收获,就点个赞吧
0 人点赞
