上一篇我们学习了利用 GROUP BY 子句的扩展选项(ROLLUP、CUBE 以及 GROUPING SETS)实现数据的层次统计、交叉汇总以及自定义维度分析等高级功能。
不过,产品和业务对于复杂报表的需求并不仅仅止步于此。例如,如何分析员工在部门内的薪酬排名、计算产品每个月的累计销量以及与去年同期相比的增长率等。这些分析功能通过分组汇总操作通常很难或者无法实现,因此我们需要了解更加强大的 SQL 窗口函数(Window Function)。
窗口函数定义
与聚合函数类似,窗口函数也是针对一组数据进行分析计算;但窗口函数不是将一组数据汇总成单个结果,而是为每一行数据返回一个分析结果。下图演示了两者之间的区别: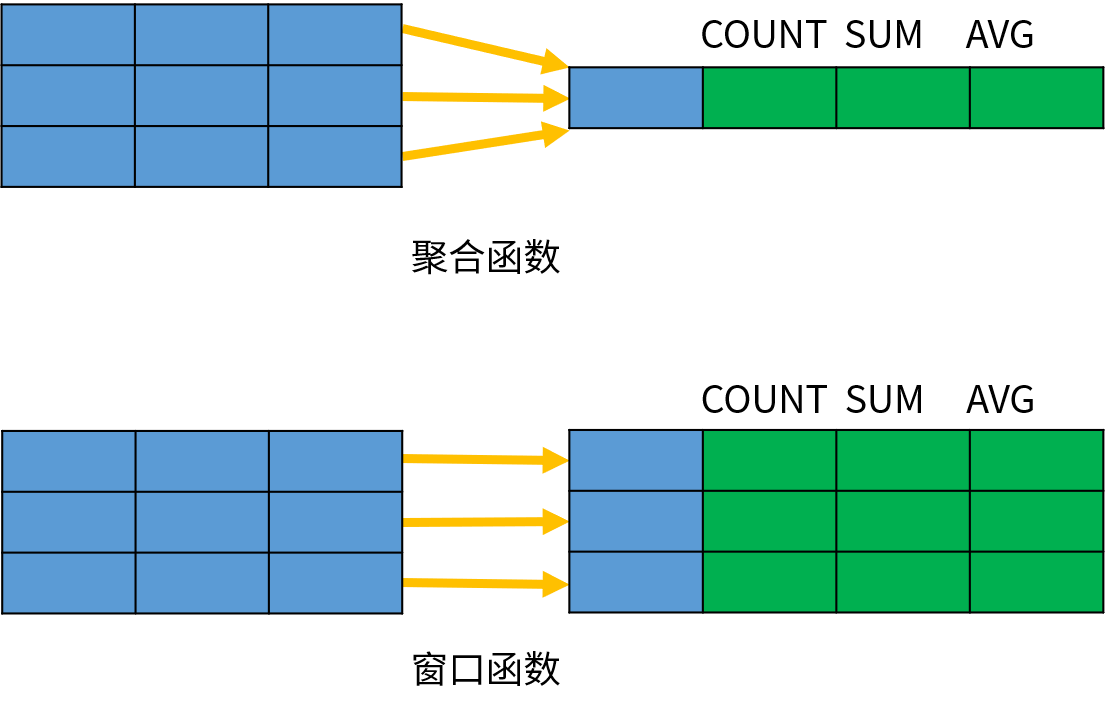
聚合函数会将同一个组内的多条数据汇总成一条数据,但是窗口函数保留了所有的原始数据。
窗口函数也被称为联机分析处理(OLAP)函数,或者分析函数(Analytic Function)。
我们以 SUM 函数为例,比较这两种函数的差异。以下语句将 SUM 作为聚合函数使用,统计所有员工的总月薪:
SELECT SUM(salary) AS sumsalary FROM employee; sum_salary| —————|_ 245800.00| 复制
SUM 聚合函数将所有员工的数据汇总成了一个结果。再来看 SUM 作为窗口函数使用的效果:
SELECT emp_id, emp_name, SUM(salary) OVER () AS sum_salary FROM employee; 复制
其中,OVER 关键字表明 SUM 是一个窗口函数;括号内为空表示将所有数据作为整体进行分析。该语句的结果如下(显示部分内容):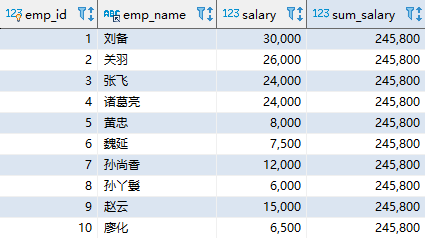
查询结果返回了所有的员工记录,并且 SUM 聚合函数为每个员工都返回了相同的汇总结果。
从上面的示例可以看出,窗口函数与其他函数的不同之处在于它包含了一个 OVER 子句;OVER 子句用于定义一个分析数据的窗口。完整的窗口函数定义如下:
window_function ( expression ) OVER ( PARTITION BY … ORDER BY … frame_clause ) 复制
其中,window_function 是窗口函数的名称;expression 是窗口函数操作的对象,可以是字段或者表达式;OVER 子句包含三个部分:分区(PARTITION BY)、排序(ORDER BY)以及窗口大小(frame_clause)。
接下来我们分别介绍这些选项的作用。
分区(PARTITION BY)
OVER 子句中的 PARTITION BY 选项用于定义分区,作用类似于 GROUP BY 分组;如果指定了分区选项,窗口函数将会分别针对每个分区单独进行分析。
以下语句按照不同的部门分别统计员工的月薪合计:
SELECT emp_name “姓名”, salary “月薪”, dept_id “部门编号”, SUM(salary) OVER ( PARTITION BY dept_id ) AS “部门月薪合计” FROM employee; 复制
其中,OVER 子句中的 PARTITION BY 选项表示按照部门进行分区;因此,SUM 函数按照部门分别统计月薪的合计值。该语句的结果如下(显示部分内容):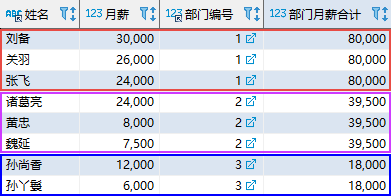
查询结果中,前 3 行数据的部门编号都为 1,因此该部门的月薪合计为 30000 + 26000 + 24000 = 80000。其他的数据也采用同样的方式进行计算。
在窗口函数中指定 PARTITION BY 选项之后,不需要 GROUP BY 子句也能获得分组统计信息。如果不指定 PARTITION BY 选项,所有的数据作为一个整体进行分析。
排序(ORDER BY)
OVER 子句中的 ORDER BY 选项用于指定分区内的排序方式,与 ORDER BY 子句的作用类似;排序选项通常用于数据的排名分析。
以下示例用于统计员工在部门内的月薪排名:
SELECT emp_name “姓名”, salary “月薪”, dept_id “部门编号”, RANK() OVER ( PARTITION BY dept_id ORDER BY salary DESC ) AS “部门排名” FROM employee; 复制
其中,OVER 子句中的 PARTITION BY 选项表示按照部门进行分区;ORDER BY 选项指定在部门内按照月薪从高到低进行排序;RANK 函数用于计算名次,该函数将会在下一篇中进行介绍。该查询的结果如下(显示部分内容):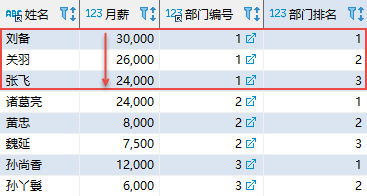
查询结果中,前 3 行数据的部门编号都为 1;“刘备”的月薪最高,在部门内排名第一;“关羽”排名第二;“张飞”排名第三。其他部门的数据采用同样的方式进行计算。
对于 Oracle 和 PostgreSQL,OVER 子句中的 ORDER BY 选项也可以使用 NULLS FIRST 指定空值排在最前,或者 NULLS LAST 指定空值排在最后。这一点与 ORDER BY 子句相同。
指定窗口大小
OVER 子句中的 frame_clause 选项用于指定一个移动的窗口。窗口总是位于分区范围之内,是分区的一个子集。指定了窗口之后,分析函数不再基于分区进行计算,而是基于窗口内的数据进行计算。窗口选项可以实现许多复杂的计算。例如,累计到当前日期为止的销量总计,每个月份及其前后各一月(3 个月)的平均销量等。
窗口大小的具体选项如下:
{ ROWS | RANGE } frame_start { ROWS | RANGE } BETWEEN frame_start AND frame_end 复制
其中,ROWS 表示以行为单位计算窗口的偏移量,RANGE 表示以数值(例如 10 天之内)为单位计算窗口的偏移量。其中,frame_start 用于定义窗口的起始位置,可以指定以下内容之一:
- UNBOUNDED PRECEDING,窗口从分区的第一行开始,默认值;
- N PRECEDING,窗口从当前行之前的第 N 行开始;
- CURRENT ROW,窗口从当前行开始。
frame_end 用于定义窗口的结束位置,可以指定以下内容之一:
- CURRENT ROW,窗口到当前行结束,默认值;
- N FOLLOWING,窗口到当前行之后的第 N 行结束。
- UNBOUNDED FOLLOWING,窗口到分区的最后一行结束;
下图演示了这些窗口选项的作用: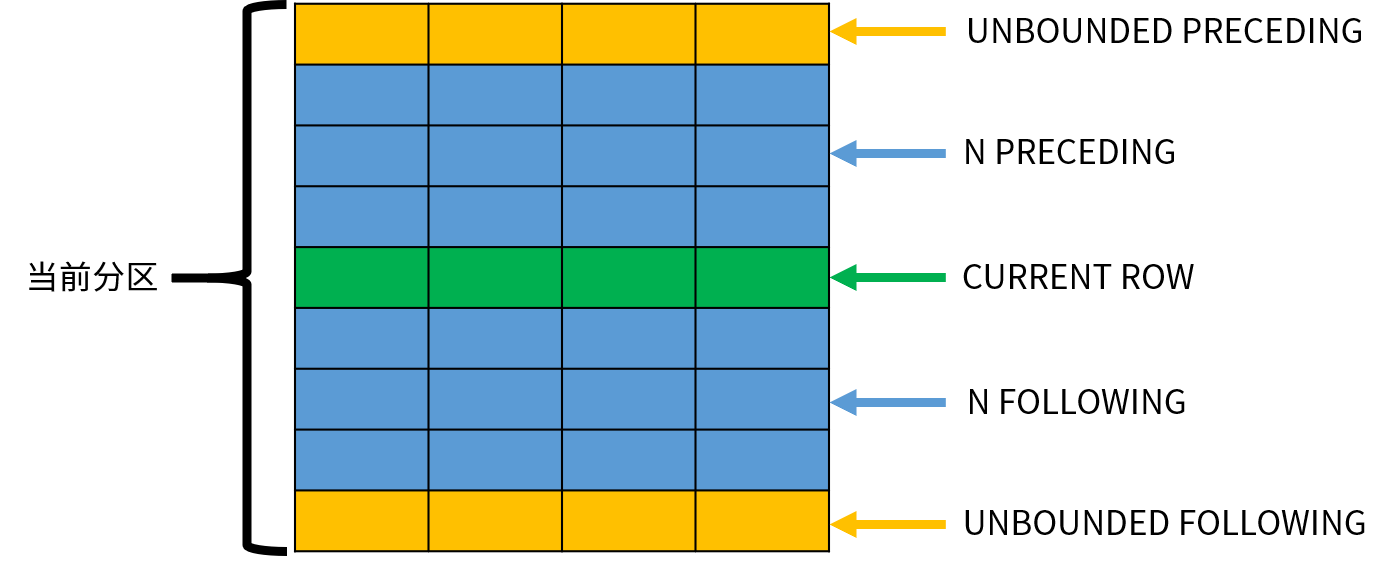
窗口函数依次处理每一行数据,CURRENT ROW 表示当前正在处理的数据;其他的行可以使用相对当前行的位置表示。需要注意的是,窗口的大小不会超出分区的范围。
窗口函数的选项比较复杂,我们通过一些常见的窗口函数示例来理解它们的作用。常见的窗口函数可以分为以下几类:聚合窗口函数、排名窗口函数以及取值窗口函数。
聚合窗口函数
许多聚合函数也可以作为窗口函数使用,包括 AVG、SUM、COUNT、MAX 以及 MIN 等。
累计求和
SUM 作为窗口函数时,可以非常方便地统计分区内的累计值。以下示例按照部门统计员工的累计月薪值:
SELECT d.dept_name “部门名称”, e.emp_name “姓名”, e.salary “月薪”, SUM(salary) OVER ( PARTITION BY e.dept_id ORDER BY e.emp_id ROWS UNBOUNDED PRECEDING ) AS “部门累计月薪” FROM employee e JOIN department d ON (e.dept_id = d.dept_id); 复制
其中,OVER 子句中的 PARTITION BY 选项表示按照部门进行分区;ORDER BY 选项表示按照工号进行排序;窗口子句 ROWS UNBOUNDED PRECEDING 指定窗口从分区的第一行开始,默认到当前行结束;因此 SUM 函数计算的是部门内累计到当前员工为止的月薪合计。该查询的结果如下(显示部分内容):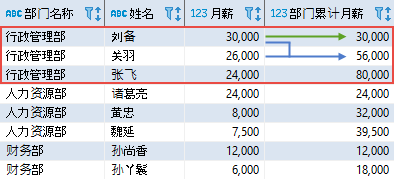
对于“行政管理部”,第一个员工的月薪为 30000,累计也是 30000;第二个员工的月薪为 26000,累计为 30000 + 26000 = 56000;依此类推,直到统计完该部门的所有员工;然后开始统计下一个部门的数据。
移动平均值
AVG 作为窗口函数时,可以用于统计分区内随着当前数据行移动的平均值。以下示例按照部门统计员工与其前后各一个员工的平均月薪值:
SELECT d.dept_name “部门名称”, e.emp_name “姓名”, e.salary “月薪”, AVG(salary) OVER ( PARTITION BY e.dept_id ORDER BY e.salary ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING ) AS “移动平均月薪” FROM employee e JOIN department d ON (e.dept_id = d.dept_id); 复制
其中,OVER 子句中的 PARTITION BY 选项表示按照部门进行分区;ORDER BY 选项表示按照月薪从低到高进行排序;窗口子句 ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING 指定窗口从当前行的前一行开始,到当前行的下一行结束;因此函数计算的是 3 名员工的月薪平均。该查询的结果如下(显示部分内容):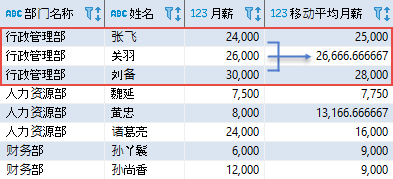
对于“行政管理部”,第一个员工的分析窗口为第 1 行和第 2行,因此平均值为 (24000 + 26000)/2 = 25000;第二个员工的分析窗口为第 1 行、第 2行以及第 3 行,因此平均值为 (24000 + 26000 + 30000)/3 = 26666;依此类推,直到统计完该部门的所有员工;然后开始统计下一个部门的数据。
小结
窗口函数是一类能够提供复杂统计报表的强大函数,这些功能通常很难使用一般的聚合函数和分组操作来实现。本篇介绍了窗口函数的定义和选项,以及如何将聚合函数作为窗口函数使用,实现数据的累计求和与移动分析。
练习题:在上一篇的练习题 2 中,销售数据表 sales 在 2019 年 1 月 2 日、5 日、7 日以及 9 日没有销量。如何统计每一天和前一天的累计销量?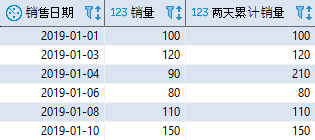

若有收获,就点个赞吧
0 人点赞
