上一篇我们介绍了数据库事务的概念和重要性、事务的 ACID 属性,以及并发事务的控制与隔离级别。
今天我们讨论与性能相关的一个重要对象:索引(Index)。你一定听说过:索引可以提高查询的性能。那么,索引的原理是什么呢?有了索引就一定可以查询的更快吗?索引只是为了优化查询速度吗?接下来我们就一一进行解答。
索引的原理
以下是一个简单的查询,查找工号为 5 的员工:
SELECT FROM employee WHERE emp_id = 5; 复制
数据库如何找到我们需要的数据呢?如果没有索引,那就只能扫描整个 employee 表,然后使用工号依次判断并返回满足条件的数据。这种方式一个最大的问题就是当数据量逐渐增加时,全表扫描的性能也就随之明显下降。
为了解决查询的性能问题,数据库引入了一个新的数据结构:*索引。索引就像书籍后面的关键字索引,按照关键字进行排序,并且提供了指向具体内容的页码。如果我们在 email 字段上创建了索引(例如 B-树索引),数据库查找的过程大概如下图所示: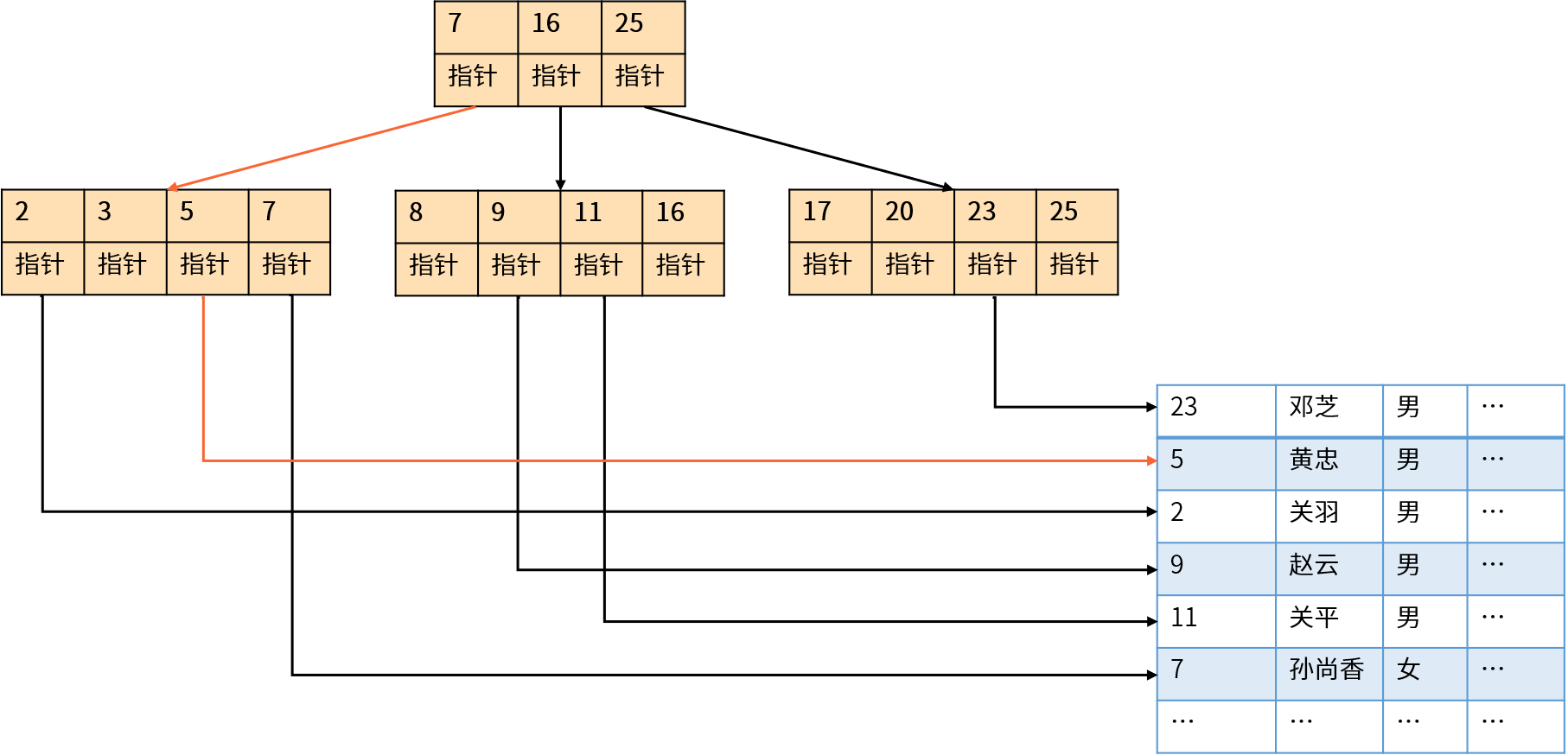
B-树(Balanced Tree)索引就像是一棵倒立的树,其中的节点按照顺序进行组织;节点左侧的数据都小于该节点的值,节点右侧的数据都大于节点的值。数据库首先通过索引查找到工号为 5 的节点,再通过该节点上的指针(通常是数据的物理地址)访问数据所在的磁盘位置。
举例来说,假设每个索引分支节点可以存储 100 个记录,100 万(100^3^)条记录只需要 3 层 B-树即可完成索引。通过索引查找数据时需要读取 3 次索引数据(每次磁盘 IO 读取整个分支节点),加上 1 次磁盘 IO 读取数据即可得到查询结果。
如果采用全表扫描,需要执行的磁盘 IO 可能高出几个数量级。当数据量增加到 1 亿时,B-树索引只需要再增加一次索引 IO 即可;而全表扫描需要再增加几个数量级的 IO。
以上只是一个简化的 B-树索引原型,实际的数据库索引还会在索引节点之间增加互相连接的指针(B+树),能够提供更好的查询性能。该网站提供了一个可视化的 B+树模拟程序,可以直观地了解索引的维护和查找过程。
索引的类型
虽然各种数据库支持的索引不完全相同,对于相同的索引也可能存在实现上的一些差异;但它们都实现了许多通用的索引类型。
B-树索引与 Hash 索引
B-树索引,使用平衡树或者扩展的平衡树(B+树、B*树)结构创建索引。这是最常见的一种索引,主流的数据库默认都采用 B-树索引。这种索引通常用于优化 =、<、<=、>、BETWEEN、IN 以及字符串的前向匹配(’abc%’)查询。
Hash 索引,使用数据的哈希值创建索引。使用哈希索引查找数据的过程如下: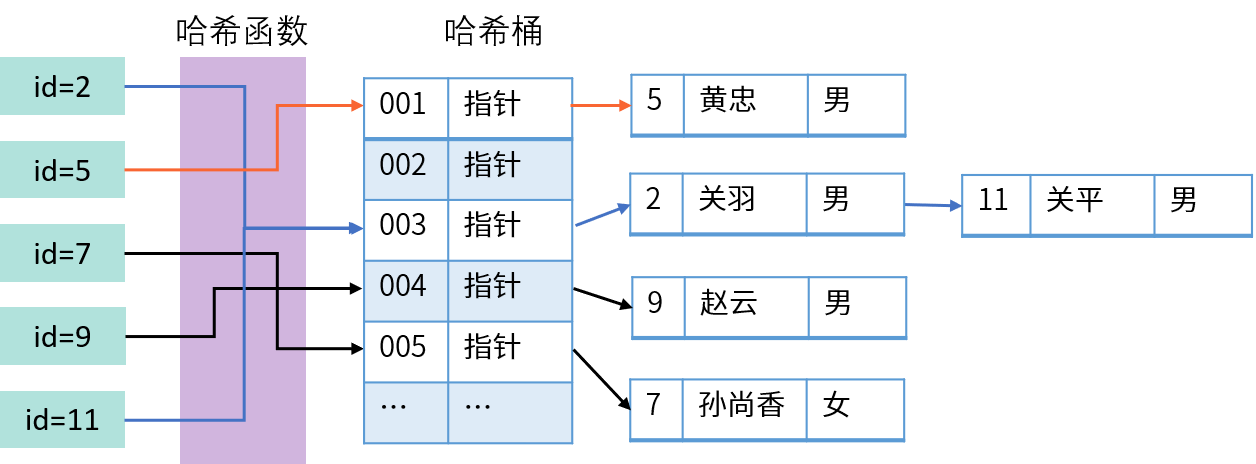
查询时通过检索条件(例如 id=5)的哈希值直接进行匹配,从而找到数据所在的位置。哈希索引主要用于等值(=)查询,速度更快;但是哈希函数的结果没有顺序,因此不适合范围查询,也不能用于优化 ORDER BY 排序。
聚集索引与非聚集索引
聚集索引(Clustered index)将表中的数据按照索引的结构(通常是主键)进行存储。也就是说,索引的叶子节点中存储了表的数据。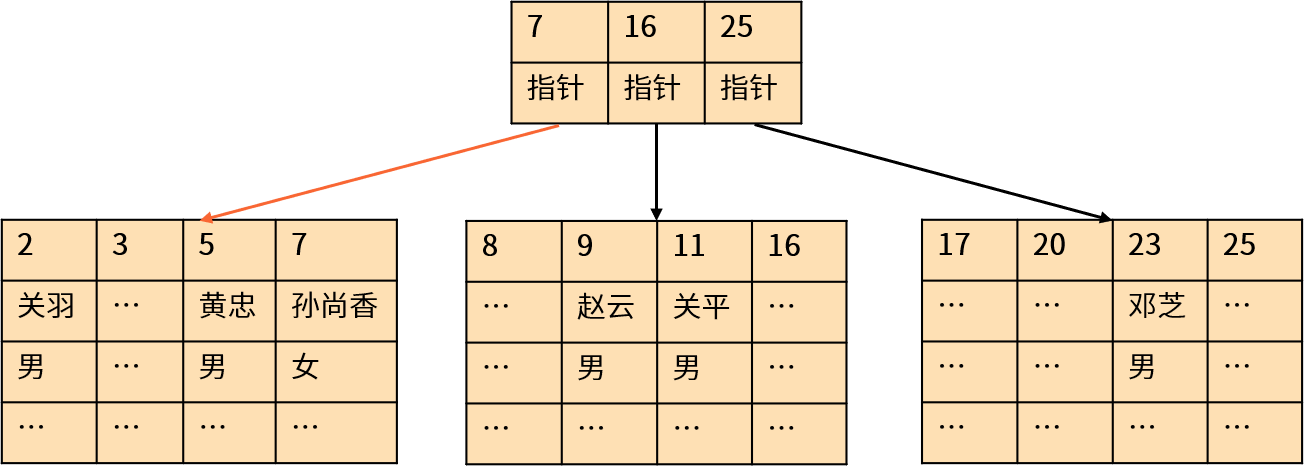
严格来说,聚集索引其实是一种特殊的表。MySQL(InnoDB 存储引擎)和 SQL Server 将这种结构的表称为聚集索引,Oracle 中称为索引组织表(IOT)。这种存储数据的方式适合使用主键进行查询的应用,类似于 key-value 系统。
非聚集索引就是普通的索引,索引的叶子节点中存储了指向数据所在磁盘位置的指针,数据在磁盘上随机分布。MySQL(InnoDB 存储引擎)称之为二级索引(Secondary index),叶子节点存储的是聚集索引的键值(通常是主键);通过二级索引查找时需要先找到相应的主键值,再通过主键索引查找数据。因此,创建聚集索引的主键字段越小,索引就越小;一般采用自增长的数字作为主键。
SQL Server 如果使用聚集索引创建表,非聚集索引的叶子节点存储的也是聚集索引的键值;否则,非聚集索引的叶子节点存储的是指向数据行的地址。
唯一索引与非唯一索引
唯一索引(UNIQUE)中的索引值必须唯一,可以确保被索引的数据不会重复,从而实现数据的唯一性约束。
非唯一索引允许被索引的字段存在重复值,仅仅用于提高查询的性能。
单列索引与多列索引
单列索引是基于单个字段创建的索引。例如,员工表的主键使用 emp_id 字段创建,就是一个单列索引。
多列索引是基于多个字段创建的索引,也叫复合索引。创建多列索引的时候需要注意字段的顺序,查询条件中最常出现的字段放在最前面,这样可以最大限度地利用索引优化查询的性能。
其他索引类型
全文索引(Full-text),用于支持全文搜索,类似于 Google 和百度这种搜索引擎。
函数索引,基于函数或者表达式的值创建的索引。例如,员工的 email 不区分大小写并且唯一,可以基于 UPPER(email) 创建一个唯一的函数索引。
有了索引的概念之后,我们来看一下如何创建和管理索引。
维护索引
创建索引
使用 CREATE INDEX 语句创建索引,默认情况下创建的是 B+ 树索引:
CREATE [UNIQUE] INDEX index_name ON table_name(col1 [ASC | DESC], …); 复制
其中,UNIQUE 表示创建唯一索引;ASC 表示索引按照升序排列,DESC 表示索引按照降序排列,默认为 ASC。以下语句为表 emp_devp 的员工姓名字段创建一个普通索引:
CREATE INDEX idx_emp_devp_name ON emp_devp(emp_name); 复制
定义主键和唯一约束时,数据库自动创建相应的索引。MySQL InnoDB 存储引擎也会自动为外键约束创建索引。
查看索引
常用的数据库管理和开发工具(例如 MySQL Workbench、DBeaver)都提供了查看索引的图形化方式。在此,我们介绍数据库提供的查看索引的命令。
MySQL 提供了 SHOW INDEXES 命令查看表的索引:
— MySQL 实现 SHOW INDEXES FROM empdevp; Table |Non_unique|Key_name |Seq_in_index|Column_name|Collation|Cardinality|Sub_part|Packed|Null|Index_type|Comment|Index_comment|Visible|Expression| ————|—————|————————-|——————|—————-|————-|—————-|————|———|——|—————|———-|——————-|———-|—————| emp_devp| 0|PRIMARY | 1|emp_id |A | 9| | | |BTREE | | |YES | | emp_devp| 1|idx_emp_devp_name| 1|emp_name |A | 9| | | |BTREE | | |YES | | 复制
以上语句返回了两条记录,其中 PRIMARY 是系统自动为主键创建的索引。
Oracle 中可以通过系统表查询索引信息:
— Oracle 实现 SELECT i.index_name, i.index_type, i.table_name, ic.column_name, i.uniqueness, i.status, i.visibility FROM user_indexes i JOIN user_ind_columns ic ON (i.index_name = ic.index_name AND i.table_name = ic.table_name) WHERE i.table_name =’EMP_DEVP’; INDEX_NAME |INDEX_TYPE|TABLE_NAME|COLUMN_NAME|UNIQUENESS|STATUS|VISIBILITY| ————————-|—————|—————|—————-|—————|———|—————| SYS_C0013258 |NORMAL |EMP_DEVP |EMP_ID |UNIQUE |VALID |VISIBLE | IDX_EMP_DEVP_NAME|NORMAL |EMP_DEVP |EMP_NAME |NONUNIQUE |VALID |VISIBLE | 复制
其中,user_indexes 存储了用户的索引信息,user_ind_columns 存储了索引的字段信息。
SQL Server 中查看表的索引最简单的方法就是使用系统存储过程 sp_helpindex:
— SQL Server 实现 EXEC sp_helpindex ‘emp_devp’; index_name |index_description |index_keys| ———————————————|————————————————————————-|—————| idx_emp_devp_name |nonclustered located on PRIMARY |emp_name | PKemp_devp1299A861CF50466E|clustered, unique, primary key located on PRIMARY|emp_id | 复制
PostgreSQL 提供了关于索引的视图 pg_indexes,用于查看表的索引:
— PostgreSQL 实现 SELECT FROM pg_indexes *WHERE tablename = ‘emp_devp’; schemaname|tablename|indexname |tablespace|indexdef | —————|————-|————————-|—————|————————————————————————————————————-|_ public |emp_devp |emp_devp_pkey | |CREATE UNIQUE INDEX emp_devp_pkey ON public.emp_devp USING btree (emp_id)| public |emp_devp |idx_emp_devp_name| |CREATE INDEX idx_emp_devp_name ON public.emp_devp USING btree (emp_name) | 复制
删除索引
DROP INDEX 语句用于删除一个索引:
— Oracle 和 PostgreSQL 实现 DROP INDEX idxemp_devp_name; 复制
对于 MySQL 和 SQL Server 而言,删除索引时需要指定表名:
— MySQL 和 SQL Server 实现_ DROP INDEX idx_emp_devp_name ON emp_devp; 复制
索引不是约束
在数据库中,索引还用于实现另一个功能:主键约束和唯一约束。因此,很多人存在一个概念上的误解,认为索引就是约束。唯一约束是指字段的值不能重复,但是可以为 NULL;例如,员工的邮箱需要创建唯一约束,确保不会重复。
理论上可以编写一个程序,在每次新增或修改邮箱时检查是否与其他数据重复,来实现唯一约束;但是这种方式的性能很差,并且无法解决并发时的冲突问题。但是,如果在该字段上增加一个唯一索引,就很方便地满足了唯一性的要求,而且能够提高以邮箱作为条件时的查询性能。
当我们使用以下语句为 email 字段增加一个唯一约束时,所有的数据库都会默认创建一个唯一索引,索引名称就是 ukemp_email。
CONSTRAINT uk_emp_email UNIQUE (email) 复制
我们使用 Oracle 数据库做一个有意思的试验,先创建一个非唯一的索引,然后基于该索引创建唯一约束:
— Oracle 实现_ CREATE TABLE t(id int, v VARCHAR(10)); CREATE INDEX idx_t_v ON t(v); ALTER TABLE t ADD CONSTRAINT uk_t_v UNIQUE (v) USING INDEX idx_t_v; INSERT INTO t VALUES (1,’a’); INSERT INTO t VALUES (2,’a’); SQL Error [1] [23000]: ORA-00001: unique constraint (TONY.UK_T_V) violated 复制
当然,实际上我们不需要这样操作;因为数据库会自动为主键和唯一约束增加一个唯一索引。但是,除了 MySQL InnoDB 存储引擎之外,外键约束通常不会自动创建索引,不要忘记手动创建相应的索引。
索引注意事项
既然索引可以优化查询的性能,那么我们是不是应该将所有字段都进行索引?显然并非如此,因为索引在提高查询速度的同时也需要付出一定的代价。
首先,索引需要占用磁盘空间。索引独立于数据而存在,过多的索引会导致占用大量的空间,甚至超过数据文件的大小。
其次,对数据进行 DML 操作时,同时也需要对索引进行维护;维护索引有时候比修改数据更加耗时。
索引是优化查询的一个有效手段,但是过渡的索引可能给系统带来负面的影响。我们将会在第 34 篇中讨论如何创建合适的索引,利用索引优化 SQL 语句,以及检查索引是否被有效利用等。
小结
SQL 语句的声明性使得我们不需要关心具体的操作实现,但同时也可能因此导致数据库的性能问题。索引可以提高数据检索的速度,也可以用于实现唯一约束;但同时索引也需要占用一定的磁盘空间,索引的维护需要付出一定的代价。

若有收获,就点个赞吧
0 人点赞
