上一篇我们介绍了如何使用动态 SQL 创建通用的查询语句以及 SQL 注入问题和预防方法。
今天是我们专栏的最后一篇文章,不知不觉我们已经坚持了 2 个多月,完成了从初级查询到高级分析功能、从增删改查到数据库设计、从性能优化到应用开发等相关知识的学习。
在考虑本篇文章的内容时,开始我是打算说一说编写专栏的感想和收获;不过最终还是决定利用这篇文章再介绍一些与 SQL 相关的重要概念和总结。其它的让我们留在评论区吧!
再谈关系
在专栏开始的第 2 篇中,我们介绍了 SQL 编程中的一个最重要思想:一切都是关系。关系在数据库中实现为二维表,由数量固定的列和任意数量的行组成;所以,关系表可以看作是一个由元素(数据行)构成的集合。而 SQL 语言本质上是为关系表提供的各种操作,我们可以将专栏的内容汇总如下: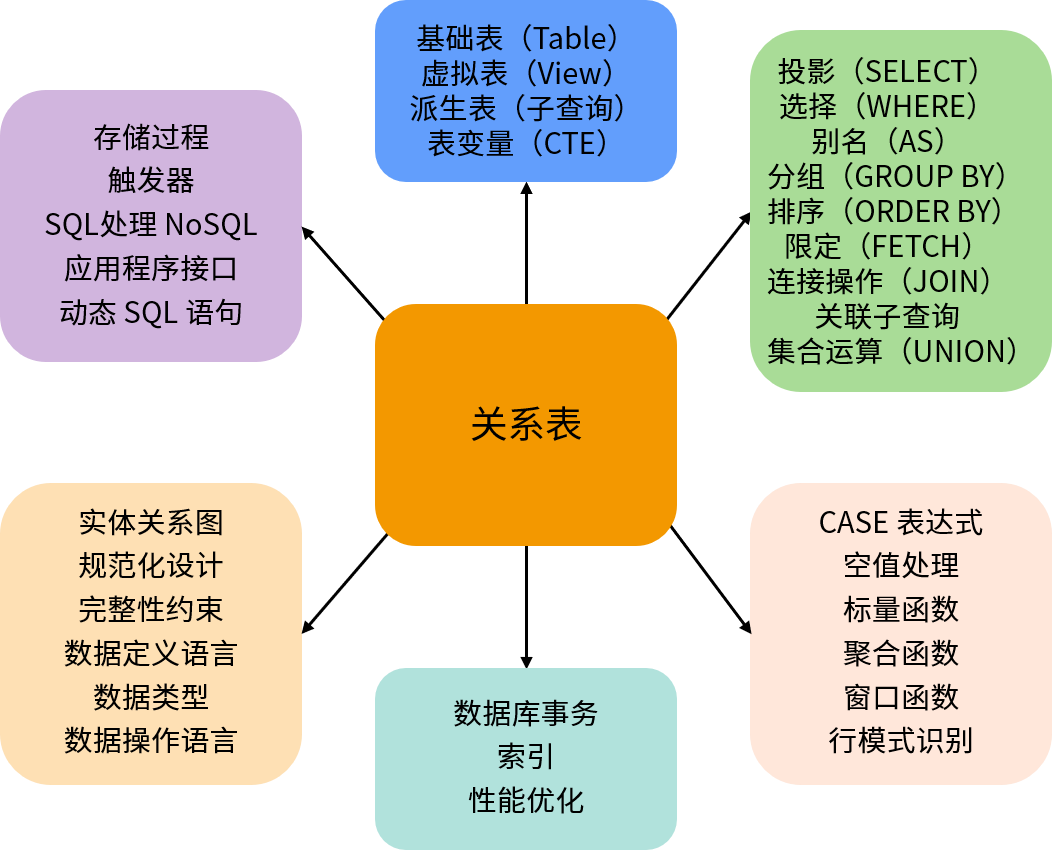
首先,关系表在数据库中存在几种不同的表现形式:
- 基础表(Table)是数据库中存储数据的主要对象;
- 视图(View)是一个命名的查询语句。视图不存储数据,但是经常当作表来使用,因此被称为虚拟表;
- 查询的结果集被称为派生表(Derived Table);
- 通用表表达式(CTE)是语句级别的临时表,也称为表变量。
数据库中还有一种表叫做临时表(temporary table)。根据定义的不同,临时表会在事务结束或者会话终止时被自动清空或者删除。
接下来就是专栏的主要内容,也就是实现了各种关系操作的 SQL 语言。SQL 是一种面向集合(关系表)的声明式语言,操作的对象和结果都是集合。我们来看一个 PostgreSQL 中的示例:
— PostgreSQL SELECT FROM *abs(-1); abs| —-| 1| 复制
学习了 SQL 之后,我们应该都知道 FROM 子句指定的是一个表;而 abs 是求绝对值的函数,所以在 PostgreSQL 中甚至函数的结果都是一个表。
伟大的设计通常都体现了简单的哲学思想,就像在 Unix/Linux 中一切皆文件一样,在 SQL 中一切皆关系。
在专栏中我们详细介绍了关系操作中的投影(SELECT)、选择(WHERE)、别名(AS)、分组(GROUP BY)、排序(ORDER BY)、限定(FETCH/LIMIT)、集合操作(UNION、INTERSECT 和 EXCEPT)、连接操作(INNER/LEFT/RIGHT/FULL JOIN、CROSS JOIN)以及子查询等。当我们使用这些操作组合成一个复杂的 SQL 语句时,需要注意它们的编写顺序和逻辑执行顺序。
SQL 执行顺序
回顾一下我们学习过的 SQL 查询语句:
(6)SELECT [DISTINCT | ALL] col1, col2, agg_func(col3) AS alias (1) FROM t1 JOIN t2 (2) ON (join_conditions) (3) WHERE where_conditions (4) GROUP BY col1, col2 (5)HAVING having_condition (7) UNION [ALL] … (8) ORDER BY col1 ASC,col2 DESC (9)OFFSET m ROWS FETCH NEXT num_rows ROWS ONLY; 复制
以上是 SQL 中各种关键字的编写顺序,前面括号内的数字代表了它们的逻辑执行顺序。也就是说,SQL 并不是按照编写顺序先执行 SELECT,然后再执行 FROM 子句。从逻辑上讲,SQL 语句的执行顺序如下:
- 首先,FROM 和 JOIN 是 SQL 语句执行的第一步。它们的逻辑结果是一个笛卡尔积,决定了接下来要操作的数据集。注意逻辑执行顺序并不代表物理执行顺序,实际上数据库在获取表中的数据之前会使用 ON 和 WHERE 过滤条件进行优化访问;
- 其次,应用 ON 条件对上一步的结果进行过滤并生成新的数据集;
- 然后,执行 WHERE 子句对上一步的数据集再次进行过滤。WHERE 和 ON 大多数情况下的效果相同,但是外连接查询有所区别,我们将会在下文给出示例;
- 接着,基于 GROUP BY 子句指定的表达式进行分组;同时,对于每个分组计算聚合函数 agg_func 的结果。经过 GROUP BY 处理之后,数据集的结构就发生了变化,只保留了分组字段和聚合函数的结果;
- 如果存在 GROUP BY 子句,可以利用 HAVING 针对分组后的结果进一步进行过滤,通常是针对聚合函数的结果进行过滤;
- 接下来,SELECT 可以指定要返回的列;如果指定了 DISTINCT 关键字,需要对结果集进行去重操作。另外还会为指定了 AS 的字段生成别名;
- 如果还有集合操作符(UNION、INTERSECT、EXCEPT)和其他的 SELECT 语句,执行该查询并且合并两个结果集。对于集合操作中的多个 SELECT 语句,数据库通常可以支持并发执行;
- 然后,应用 ORDER BY 子句对结果进行排序。如果存在 GROUP BY 子句或者 DISTINCT 关键字,只能使用分组字段和聚合函数进行排序;否则,可以使用 FROM 和 JOIN 表中的任何字段排序;
- 最后,OFFSET 和 FETCH(LIMIT、TOP)限定了最终返回的行数。
理解 SQL 的逻辑执行顺序可以帮助我们避免一些常见的错误,例如以下语句:
— 错误示例 SELECT empname AS empname FROM employee WHERE empname =’张飞’; 复制
该语句的错误在于 WHERE 条件中引用了列别名;从上面的逻辑顺序可以看出,执行 WHERE 条件时还没有执行 SELECT 子句,也就没有生成字段的别名。
另外一个需要注意的操作就是 GROUP BY,我们在第 13 篇中给出了一个常见的错误示例:
— GROUP BY 错误示例 SELECT dept_id, emp_name, AVG(salary) FROM employee GROUP BY dept_id; 复制
由于经过 GROUP BY 处理之后结果集只保留了分组字段和聚合函数的结果,示例中的 emp_name 字段已经不存在;从业务逻辑上来说,按照部门分组统计之后再显示某个员工的姓名没有意义。如果需要同时显示员工信息和所在部门的汇总,可以使用窗口函数。
如果使用了 GROUP BY 分组,之后的 SELECT、ORDER BY 等只能引用分组字段或者聚合函数;否则,可以引用 FROM 和 JOIN 表中的任何字段。
还有一些逻辑问题可能不会直接导致查询出错,但是会返回不正确的结果;例如外连接查询中的 ON 和 WHERE 条件。以下是一个左外连接查询的示例:
SELECT e.emp_name, d.dept_name FROM employee e LEFT JOIN department d ON (e.dept_id = d.dept_id) WHERE e.emp_name =’张飞’; emp_name|dept_name| ————|————-| 张飞 |行政管理部| SELECT e.emp_name, d.dept_name FROM employee e LEFT JOIN department d ON (e.dept_id = d.dept_id AND e.emp_name =’张飞’); emp_name|dept_name| ————|————-|_ 刘备 | [NULL]| 关羽 | [NULL]| 张飞 |行政管理部| 诸葛亮 | [NULL]| … 复制
第一个查询在 ON 子句中指定了连接的条件,同时通过 WHERE 子句找出了“张飞”的信息。
第二个查询将所有的过滤条件都放在 ON 子句中,结果返回了所有的员工信息。这是因为左外连接会返回左表中的全部数据,即使 ON 子句中指定了员工姓名也不会生效;而 WHERE 条件在逻辑上是对连接操作之后的结果进行过滤。
除此之外,了解 SQL 逻辑执行顺序也可以帮助我们进行 SQL 优化。例如 WHERE 子句在 HAVING 子句之前执行,因此我们应该尽量使用 WHERE 进行数据过滤,避免无谓的操作;除非业务需要针对聚合函数的结果进行过滤。
数据分析功能
SQL 作为一种数据领域的专用语言,必然支持数据分析所需的各种功能:
- CASE 表达式可以为 SQL 语句提供逻辑处理的能力,理论上来说可以实现任意复杂的处理逻辑;
- 空值(NULL)代表了缺失的数据,空值处理是数据分析中的常见问题;
- 函数通常为我们提供了某种功能, SQL 中的各种内置标量函数提高了我们处理数据的效率;
- 聚合函数与分组操作相结合可以实现数据的汇总和多维度分析报表;
- 窗口函数可以进一步完成累计分析、移动分析以及分类排名等复杂的报表需求;
行模式识别(MATCH_RECOGNIZE)可以用于分析各种数据流,例如股票行情数据分析、金融欺诈检测等。
数据库设计与应用开发
在专栏的课程中,我们还介绍了一些与关系模式设计、查询性能以及应用程序接口相关的内容。
数据库设计通常遵循一定的流程,其中 ER 图和规范化是两种常用的技术。设计关系模式时需要考虑字段类型的选择和完整性约束问题,最终我们可以使用 DDL 语句创建表和索引等对象,同时利用 DML 语句对表中的数据执行增删改合操作。
数据库事务是一组业务逻辑上的操作单元,具有 ACID 属性。隔离可以确保数据的一致性,但是会影响并发处理的能力。与数据库性能相关的一个重要对象是索引,合理利用索引和一些查询技巧通常可以优化 SQL 语句的性能,与此相关的一个重要的概念就是执行计划。
除了声明式的 SQL 语句之外,数据库还提供了服务器端的编程功能,例如存储过程和触发器。应用程序也可以通过驱动连接数据库,执行各种数据操作;为了防止动态语句可能带来的 SQL 注入问题,我们应该使用参数化或者带绑定变量的预编译语句。
另外,关系数据库对 JSON 文档的支持使得我们可以同时获得SQL 的强大功能和事务支持(ACID)以及 NoSQL 的灵活性和高性能。写在最后
恭喜你能够从专栏的开始学习到了最后,相信你在这个过程中一定会有所收获。不过专栏的内容有限,又要兼顾初学者的需求和有一定经验的同学,很难做到面面俱到。学习是一个不断进步的过程,而且最好能在实际工作中加以应用;希望我们能够保持联系,也欢迎来我的博客继续交流。
最后送给大家一句话,共勉之:
荀子曰:不闻不若闻之,闻之不若见之,见之不若知之,知之不若行之。学至于行之而止矣。
推荐资源:《SQL基础教程(第2版)》、《SQL进阶教程》以及 bilibili 上配套的视频;
- 《MySQL 8从入门到精通(视频教学版)》;
- 《高性能MySQL(第3版)》;
- 《MySQL技术内幕:InnoDB存储引擎(第2版)》;
- MySQL 官方文档;
- 《Oracle编程艺术:深入理解数据库体系结构(第3版)》
- 《Oracle Database 12c性能优化攻略》
- 《Oracle Database 12c完全参考手册(第7版)》
- 《Oracle PL/SQL程序设计(第6版)》
- Oracle 官方文档;
- 《SQL Server 从入门到项目实践(超值版)》
- 《SQL Server 2012 T-SQL基础教程》
- SQL Server 官方文档;
- 《PostgreSQL实战》
- 《PostgreSQL指南:内幕探索》
- 《PostgreSQL技术内幕:查询优化深度探索》
- PostgreSQL 官方文档。

若有收获,就点个赞吧
0 人点赞
