上一篇我们学习了如何利用 SQL 通用表表达式(CTE)简化复杂的查询语句,实现数据的遍历和递归处理。
我们在第 13 篇学习了基础的数据分组汇总操作,例如按照部门和职位统计员工的数量和平均月薪。现在,让我们讨论一些更高级的分组统计分析功能,也就是 GROUP BY 子句的扩展选项。
销售示例数据
本篇我们将会使用一个新的销售数据集(sales_data),它包含了 2019 年 1 月 1 日到 2019 年 6 月 30 日三种产品在三个渠道的销售情况。以下是该表中的部分数据: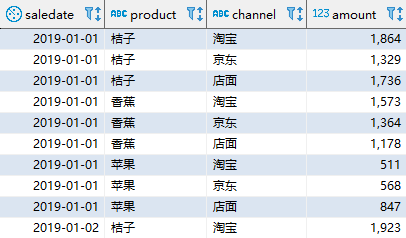
我们将创建销售表和数据初始化的脚本放在了 GitHub 上,点击链接进行下载。
现在就让我们来看看 GROUP BY 支持哪些高级分组选项。
层次化的小计和总计
首先,我们按照产品和渠道统计一下销售额度:
SELECT product AS “产品”, channel AS “渠道”, SUM(amount) AS “销售金额” FROM salesdata GROUP BY product, channel; 复制
这是一个简单的分组汇总操作。该查询的结果如下,不同数据库中的显示顺序可能不同: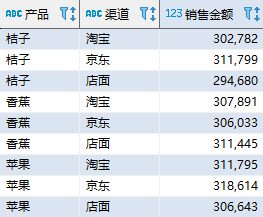
我们得到了每种产品在每个渠道的销售金额。现在我们来思考一个问题:如何知道每种产品在所有渠道的销售金额合计,以及全部产品的销售金额总计呢?
在 SQL 中可以使用 GROUP BY 子句的扩展选项:ROLLUP。ROLLUP 可以生成按照层级进行汇总的结果,类似于财务报表中的小计、合计和总计。
我们将上面的示例加上 ROLLUP 选项:
— Oracle、SQL Server 以及 PostgreSQL 实现 SELECT product AS “产品”, channel AS “渠道”, SUM(amount) AS “销售金额” FROM sales_data GROUP BY ROLLUP (product, channel); — MySQL 实现 SELECT product AS “产品”, channel AS “渠道”, SUM(amount) AS “销售金额” FROM sales_data GROUP BY product, channel WITH ROLLUP; 复制
其中,ROLLUP 选项位于 GROUP BY 之后,括号内是用于分组的字段;MySQL 中的 ROLLUP 关键字位于分组字段之后。先来看一下查询的结果: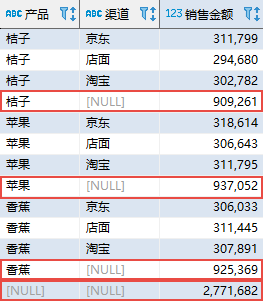
该查询的结果中多出了 4 条记录,分别表示三种产品在所有渠道的销售金额合计(渠道显示为 NULL)以及全部产品的销售金额总计(产品和渠道都显示为 NULL)。
GROUP BY 子句加上 ROLLUP 选项时,首先按照分组字段进行分组汇总;然后从右至左依次去掉一个分组字段再进行分组汇总,被去掉的字段显示为空;最后,将所有的数据进行一次汇总,所有的分组字段都显示为空。
在上面的示例中,显示为空的字段作用不太明显。我们可以利用空值函数 COALESCE 将结果显示为更易理解的形式:
— Oracle、SQL Server 以及 PostgreSQL 实现 SELECT COALESCE(product, ‘所有产品’) AS “产品”, COALESCE(channel, ‘所有渠道’) AS “渠道”, SUM(amount) AS “销售金额” FROM sales_data GROUP BY ROLLUP (product, channel); — MySQL 实现_ SELECT COALESCE(product, ‘所有产品’) AS “产品”, COALESCE(channel, ‘所有渠道’) AS “渠道”, SUM(amount) AS “销售金额” FROM sales_data GROUP BY product, channel WITH ROLLUP; 复制
其中,COALESCE 函数将 NULL 转换成更明确的文字描述。该查询的结果如下: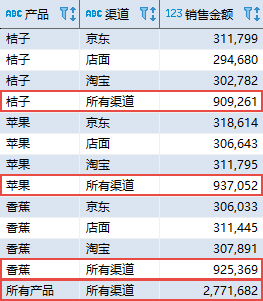
除了 ROLLUP 之外,GROUP BY 还支持 CUBE 选项。
多维度的交叉统计
CUBE 代表立方体,它用于对分组字段进行各种可能的组合,能够产生多维度的交叉统计结果。CUBE 通常用于数据仓库中的交叉报表分析。
示例数据集 salesdata 中包含了产品、日期和渠道 3 个维度,对应的数据立方体结构如下图所示:
其中,每个个小的方块表示一个产品在特定日期、特定渠道下的销售金额。
以下语句利用 CUBE 选项获得每种产品在每个渠道的销售金额小计,每种产品在所有渠道的销售金额合计,每个渠道全部产品的销售金额合计,以及全部产品在所有渠道的销售金额总计:
— Oracle、SQL Server 以及 PostgreSQL 实现_ SELECT COALESCE(product, ‘所有产品’) AS “产品”, COALESCE(channel, ‘所有渠道’) AS “渠道”, SUM(amount) AS “销售金额” FROM sales_data GROUP BY CUBE (product, channel) ORDER BY product, channel; 复制
其中,CUBE 表示按照产品和渠道分组,加上按照产品分组,加上按照渠道分组,以及所有数据进行分组统计。该语句的结果如下: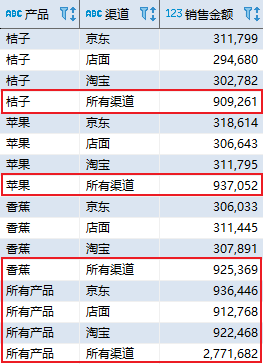
从以上结果可以看出,CUBE 返回了更多的分组数据,其中也包含了 ROLLUP 汇总的结果。随着分组字段的增加,CUBE 产生的组合将会呈指数级增长。
MySQL 目前还不支持 CUBE 选项。
ROLLUP 和 CUBE 都是按照预定义好的组合方式进行分组;GROUP BY 还支持一种更灵活的统计方式:GROUPING SETS。
自定义分组粒度
GROUPING SETS 选项可以用于指定自定义的分组集,也就是分组字段的组合方式。实际上,ROLLUP 和 CUBE 都属于特定的分组集。
就上文中的示例来说:
GROUP BY product, channel; 复制
实际上是指定了 1 个分组集,相当于:
GROUP BY GROUPING SETS ((product, channel)); 复制
(product, channel) 定义了一个分组集,也就是按照产品和渠道的组合进行分组。注意,括号内的所有字段作为一个分组集,外面再加上一个括号包含所有的分组集。
上文中的 ROLLUP 选项示例:
GROUP BY ROLLUP (product, channel); 复制
实际上指定了 N + 1 个分组集,相当于:
GROUP BY GROUPING SETS ((product, channel), (product), () ); 复制
首先,按照产品和渠道的组合进行分组;然后按照不同的产品进行分组;最后的括号( () )表示将所有的数据作为整体进行统计。
上文中的 CUBE 选项示例:
GROUP BY CUBE (product, channel); 复制
实际上是指定了 2 的 N 次方个分组集,相当于:
GROUP BY GROUPING SETS ((product, channel), (product), (channel), () ); 复制
首先,按照产品和渠道的组合进行分组;然后按照不同的产品进行分组;接着按照不同的渠道进行分组;最后将所有的数据作为一个整体。
GROUPING SETS 选项的优势在于可以指定任意的分组方式。以下示例返回不同产品的销售金额合计以及不同渠道的销售金额合计:
— Oracle、SQL Server 以及 PostgreSQL 实现 SELECT COALESCE(product, ‘所有产品’) AS “产品”, COALESCE(channel, ‘所有渠道’) AS “渠道”, SUM(amount) AS “销售金额” FROM sales_data GROUP BY GROUPING SETS ((product), (channel)); 复制
其中,(product) 和 (channel) 分别指定了一个分组集。该查询的结果如下: 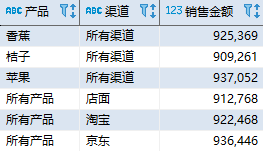 通过 GROUPING SETS 选项可以实现任意粒度(维度)的组合分析。
通过 GROUPING SETS 选项可以实现任意粒度(维度)的组合分析。
MySQL 目前还不支持 GROUPING SETS 选项。
GROUPING 函数
在进行分组统计时,如果源数据中存在 NULL 值,查询的结果会产生一些歧义。我们先插入一条模拟数据,它的渠道为空:
— 只有 Oracle 需要执行以下 alter 语句 — alter session set nls_date_format = ‘YYYY-MM-DD’; INSERT INTO salesdata VALUES (‘2019-01-01’,’桔子’, NULL, 1000.00); 复制
再次运行上文中的 ROLLUP 示例:
— Oracle、SQL Server 以及 PostgreSQL 实现 SELECT COALESCE(product, ‘所有产品’) AS “产品”, COALESCE(channel, ‘所有渠道’) AS “渠道”, SUM(amount) AS “销售金额” FROM sales_data GROUP BY ROLLUP (product, channel); 复制
在 MySQL 中相应地修改为 WITH ROLLUP 选项即可。该语句的结果如下: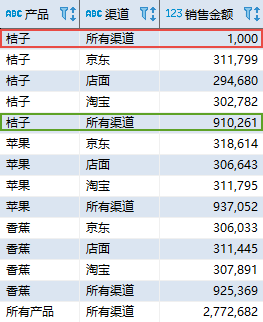
第一行的销售金额(1000)并不是“桔子”在所有渠道的销售金额合计,而是渠道为 NULL 的销售金额;第五行才是“桔子”在所有渠道的销售金额合计(910261)。问题的原因在于 GROUP BY 将空值作为了一个分组,我们(COALESCE 函数)无法区分是由汇总产生的 NULL 值还是源数据中存在的 NULL 值。
为了解决这个问题,SQL 提供了一个函数:GROUPING。以下语句演示了 GROUPING 函数的作用:
— Oracle、SQL Server 以及 PostgreSQL 实现 SELECT product AS “产品”, GROUPING(product), channel AS “渠道”, GROUPING(channel), SUM(amount) AS “销售金额” FROM sales_data GROUP BY ROLLUP (product, channel); 复制
在 MySQL 中相应地修改为 WITH ROLLUP 选项即可。该语句的结果如下: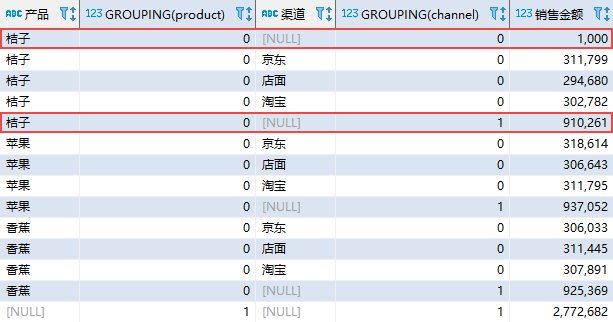
其中,GROUPING 函数返回 0 或者 1。如果当前数据是某个字段上的汇总数据,该函数返回 1;否则返回 0。例如,第 1 行数据虽然渠道显示为 NULL,但不是所有渠道的汇总,所以 GROUPING(channel) 的结果为 0;第 5 行数据的渠道同样显示为 NULL,它是“桔子”在所有渠道的销售金额汇总,所以 GROUPING(channel) 的结果为 1。
因此,我们可以利用 GROUPING 函数显示明确的信息:
— Oracle、SQL Server 以及 PostgreSQL 实现_ SELECT CASE GROUPING(product) WHEN 1 THEN ‘所有产品’ ELSE product END AS “产品”, CASE GROUPING(channel) WHEN 1 THEN ‘所有渠道’ ELSE channel END AS “渠道”, SUM(amount) AS “销售金额” FROM sales_data GROUP BY ROLLUP (product, channel); 复制
在 MySQL 中相应地修改为 WITH ROLLUP 选项即可。该语句的结果如下: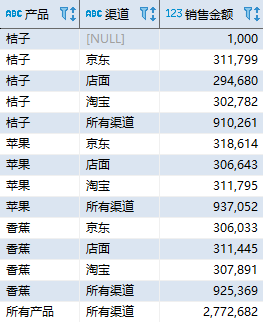
通过查询的结果可以清楚地区分出空值和汇总数据。
当然,如果源数据中不存在 NULL 值或者进行了预处理,也可以直接使用 COALESCE 函数进行显示。
小结
在 Excel 中有一个分析功能叫做数据透视表,利用 GROUP BY 的 ROLLUP、CUBE 以及 GROUPING SETS 选项可以非常容易地实现类似的效果,并且使用更加灵活。这些都是在线分析处理系统(OLAP)中的常用技术,能够提供多维度的层次统计和交叉分析功能。
练习题:编写一个查询语句,实现按照月份统计不同产品在不同渠道的销售金额小计,同时按照月份统计不同产品的销售金额合计,然后按照月份统计所有产品的销售金额合计,以及所有销售金额的总计。参考结果如下(显示部分内容):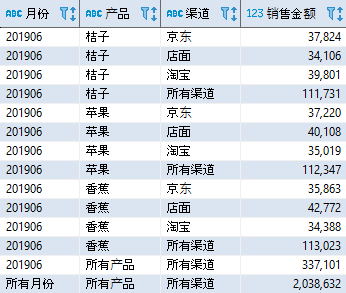

若有收获,就点个赞吧
0 人点赞
