在上一篇中,我们学习了视图的概念和作用;视图可以实现查询语句的重用,业务封装以及数据的安全访问。
今天我们来讨论另一个用于在数据库中实现业务逻辑封装的对象:存储过程(Stored Procedure)和函数(Stored Function)。
什么是存储过程?
SQL 是一种声明式的语言,关注的是结果而不是过程。但是在实际开发中为了满足业务处理的需要,编程语言(Java、C++ 等)都会提供各种功能,例如变量、控制流结构(if-else、while、for)以及异常处理等。为此,许多数据库也提供了各自的过程语言扩展(Procedural Language),同样支持在数据库服务器端实现编程的功能;这就是存储过程。
存储过程是一种存储在数据库中的程序。它可以包含多个 SQL 语句,并提供许多过程语言的功能,例如变量定义、条件控制语句、循环语句、游标以及异常处理等。在数据库中创建存储过程之后,应用程序或其他存储过程可以通过名称对其进行调用。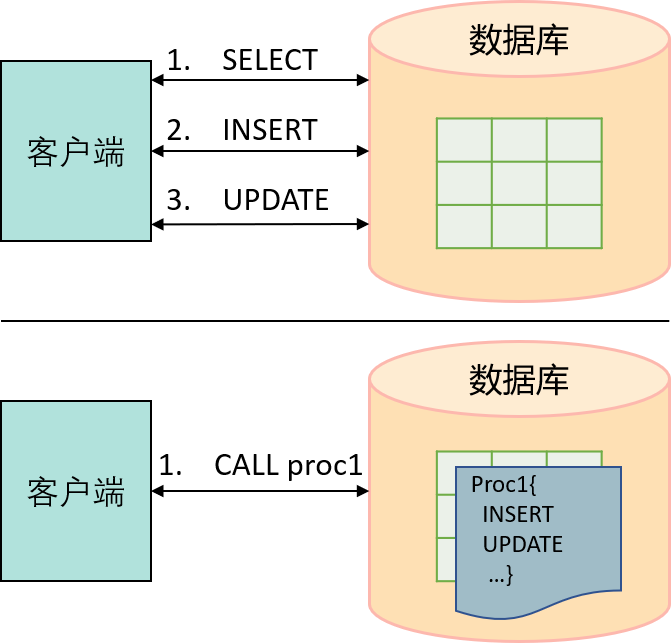
在使用存储过程的之前,我们还需要了解一下它的优缺点,以便在设计时决定是否使用存储过程。存储过程的主要优点包括:
- 实现代码的重用和管理性。存储过程创建后可以在被重复调用,不同的应用可以共享相同的存储过程;
- 实现业务的封装和隔离。应用程序通过接口访问存储过程,而不关系具体实现;当业务发生变化时,只需要修改存储过程的逻辑,但对应用程序源代码却毫无影响
- 提高应用的执行效率。存储过程经过编译之后存储在数据库中,执行时可以进行缓存,可以提高执行的速度;
- 减少了应用与数据库之间的网络流量。调用存储过程时,只需要传递参数,在一定程度上可以减轻网络负担;
- 存储过程可以提高安全性。应用程序通过存储过程进行数据访问,而不需要直接访问数据表,保证数据的安全。
另一方面,存储过程也存在一些缺点:
- 不同数据库的实现不同。Oracle 中称为 PL/SQL,MySQL 中称为 PSM,其他数据库也都有各自的语法实现;
- 存储过程需要占用数据库服务器的资源,包括 CPU、内存等,而数据库的扩展性不如应用程序;
- 存储过程的开发和维护需要专业的技能,存储过程的调试不如其他编程语言方便。
是否使用存储过程需要考虑具体的应用场景和开发人员的技术能力。对于业务快速变化的互联网应用,通常倾向于将业务逻辑放在应用层,便于扩展;而对于传统行业的应用,或者复杂的报表分析,合理使用存储过程可以提高效率。
无论如何,存储过程是数据库中一个重要的对象;接下来我们介绍如何通过存储过程实现业务逻辑的封装。
创建存储过程
虽然不同的数据库存在许多语法上的差异,但是它们都使用 CREATE PROCEDURE 命令创建存储过程,具有固定的结构并且主要的 SQL 语句都相同。
我们来创建一个用于新增员工的存储过程 insertemployee,首先是 Oracle 中的 PL/SQL 实现:
— Oracle 实现 CREATE OR REPLACE PROCEDURE insert_employee ( p_emp_name IN VARCHAR2, p_sex IN VARCHAR2, p_dept_id IN INTEGER, p_manager IN INTEGER, p_hire_date IN DATE, p_job_id IN INTEGER, p_salary IN NUMERIC, p_bonus IN NUMERIC, p_email IN VARCHAR2) AS l_emp_id INT; BEGIN — 获取下一个员工编号_ SELECT MAX(emp_id) + 1 INTO l_emp_id FROM employee; INSERT INTO employee(emp_id, emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email) VALUES (l_emp_id, p_emp_name, p_sex, p_dept_id, p_manager, p_hire_date, p_job_id, p_salary, p_bonus, p_email); END; 复制
其中:
- CREATE OR REPLACE PROCEDURE 表示如果该存储过程不存在就创建;如果已经存在就替换它的定义。
- insert_employee 是存储过程的名称;括号内是参数,IN 表示输入参数;也可以使用 OUT 指定一个输出参数,或者使用 IN OUT 指定即是输入又是输出的参数;
- AS 之后可以定义存储过程内部使用的变量,l_emp_id 是一个整数变量,用于获取下一个员工的编号;
- BEGIN 表示存储过程操作的开始;
- END 表示存储过程定义的结束。
存储过程的具体操作比较简单,就是先获取一个新的员工编号,然后利用输入参数插入一个新的记录。
接下来我们在 MySQL 中实现该存储过程:
— MySQL 实现 DELIMITER CREATE PROCEDURE insertemployee ( IN p_emp_name VARCHAR(50), IN p_sex VARCHAR(10), IN p_dept_id INTEGER, IN p_manager INTEGER, IN p_hire_date DATE, IN p_job_id INTEGER, IN p_salary NUMERIC(8,2), IN p_bonus NUMERIC(8,2), IN p_email VARCHAR(100)) BEGIN DECLARE l_emp_id INT; — 获取下一个员工编号_ SELECT MAX(emp_id) + 1 INTO l_emp_id FROM employee; INSERT INTO employee(emp_id, emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email) VALUES (l_emp_id, p_emp_name, p_sex, p_dept_id, p_manager, p_hire_date, p_job_id, p_salary, p_bonus, p_email); END DELIMITER ; 复制
MySQL 中创建存储过程的整体结构与 Oracle 类似,其中的区别在于:
- DELIMITER 不属于存储过程的内容。由于许多 MySQL 客户端将分号(;)作为 SQL 语句的终止符,而存储过程中包含多个语句;为了将存储过程的定义整体发送到服务器,需要将终止符临时修改为其他符号(例如 \$\$),最后再将其改回分号。
- IN 表示输入参数,写在参数之前;也可以使用 OUT 指定一个输出参数,或者 INOUT 指定即是输入又是输出的参数;
- DECLARE 用于定义局部变量,具体操作与 Oracle 相同。
然后是 SQL Sever 中的存储过程定义:
— SQL Sever 实现 CREATE OR ALTER PROCEDURE insertemployee ( @p_emp_name VARCHAR(50), @p_sex VARCHAR(10), @p_dept_id INTEGER, @p_manager INTEGER, @p_hire_date DATE, @p_job_id INTEGER, @p_salary NUMERIC(8,2), @p_bonus NUMERIC(8,2), @p_email VARCHAR(100)) AS BEGIN DECLARE @l_emp_id INT — 获取下一个员工编号_ SELECT @l_emp_id = MAX(emp_id) + 1 FROM employee INSERT INTO employee(emp_id, emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email) VALUES (@l_emp_id, @p_emp_name, @p_sex, @p_dept_id, @p_manager, @p_hire_date, @p_job_id, @p_salary, @p_bonus, @p_email) END 复制
其中的不同之处在于:
- CREATE OR ALTER PROCEDURE 表示创建或者修改存储过程;
- SQL Server 中的参数和变量必须以 @ 符号开头;默认为输入参数,输出参数需要在数据类型后面加上 OUT;
- DECLARE 用于定义局部变量,变量的赋值使用等号(=)而不是 INTO;
- 存储过程中的语句不需要使用分号终止符。
最后是 PostgreSQL 中的存储过程定义:
— PostgreSQL 实现 CREATE OR REPLACE PROCEDURE insertemployee ( p_emp_name IN VARCHAR, p_sex IN VARCHAR, p_dept_id IN INTEGER, p_manager IN INTEGER, p_hire_date IN DATE, p_job_id IN INTEGER, p_salary IN NUMERIC, p_bonus IN NUMERIC, p_email IN VARCHAR) LANGUAGE plpgsql AS DECLARE l_emp_id INT; BEGIN — 获取下一个员工编号_ SELECT MAX(emp_id) + 1 INTO l_emp_id FROM employee; INSERT INTO employee(emp_id, emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email) VALUES (l_emp_id, p_emp_name, p_sex, p_dept_id, p_manager, p_hire_date, p_job_id, p_salary, p_bonus, p_email); END; 复制
其中:
- LANGUAGE 指定了使用 PL/pgSQL 语言,它与 Oracle 中的 PL/SQL 非常类似;PostgreSQL 还支持其他语言实现的存储过程,包括 PL/pgSQL、C、Perl、Python 等;
- $$ 符号的作用是为了将存储过程的定义作为一个整体字符串,也可以使用其他符号。
- 其他内容与 Oracle 相同。
通过以上示例可以看出,虽然这些数据库的语法格式存在一些差异,但是整体结构类似,并且核心的 SQL 语句都相同。
调用存储过程
定义后的存储过程可以被应用程序或者其他存储过程/函数调用。SQL 使用 CALL 命令调用存储过程,大部分数据库遵循该标准。以下示例调用存储过程 insertemployee 为员工表增加一个员工:
— Oracle、MySQL 以及 PostgreSQL 实现 — 只有 Oracle 需要执行以下 alter 语句 — alter session set nlsdate_format = ‘YYYY-MM-DD’; CALL insertemployee(‘李四’, ‘男’, 5, 18, ‘2019-12-31’, 10, 6000, NULL, ‘lisi@shuguo.com’); SELECT emp_name, sex, hire_date from employee WHERE emp_name = ‘李四’; emp_name|sex|hire_date | ————|—-|—————| 李四 |男 |2019-12-31| 复制
从查询的结果可以看出,我们可以通过存储过程提供的接口操作表中的数据。SQL Server 使用 EXEC 或者 EXECUTE 命令调用存储过程:
— SQL Server 实现_ EXEC insert_employee ‘李四’, ‘男’, 5, 18, ‘2019-12-31’, 10, 6000, NULL, ‘lisi@shuguo.com’; 复制
数据库系统为我们提供了大量预定义的存储过程,具体内容可以参考数据库相关的文档。
删除存储过程
使用 DROP PROCEDURE 语句可以从数据库中删除存储过程。我们使用以下语句删除存储过程 insertemployee:
DROP PROCEDURE insert_employee; 复制
MySQL 和 PostgreSQL 支持扩展的 IF EXISTS 选项,可以避免存储过程不存在时产生错误信息:
— MySQL 和 PostgreSQL 实现_ DROP PROCEDURE IF EXISTS insert_employee; 复制
除了存储过程之外,数据库还提供了另一个类似的对象:存储函数,也称为自定义函数(User Defined Function)。
存储函数
我们已经使用过许多系统内置的各种函数,例如 ABS、UPPER、SUM 等。除此之外,我们也可以创建自己的函数,实现自定义的数据处理功能。存储函数和存储过程的创建和管理非常类似;不过,它们之间也存在一些区别:
- 存储函数通常接收输入参数并且返回一个结果(RETURN),存储过程需要通过输出参数返回数据;
- 存储函数可以在 SQL 语句中直接调用,与内置函数相同;存储过程使用 CALL 或者 EXEC 命令进行调用;
- 存储函数一般用于执行数据的计算,不会修改数据库;存储过程通常用于实现业务逻辑,常常会修改数据。
我们来创建一个函数 getDeptTotalSalary,输入参数为部门编号,返回值为该部门的总月薪。以下是 Oracle 中的语法实现:
— Oracle 实现 CREATE OR REPLACE FUNCTION getDeptTotalSalary (pndept_id INTEGER) RETURN NUMERIC AS ln_total_salary NUMERIC; BEGIN SELECT SUM(salary) INTO ln_total_salary FROM employee WHERE dept_id = pn_dept_id; RETURN ln_total_salary; END; 复制
其中,CREATE OR REPLACE FUNCTION 表示创建或者重建函数;pn_dept_id 为输入参数,代表部门编号;RETURN NUMERIC 表示返回一个数字;该函数通过一个查询语句返回了指定部门的月薪总和。
为了不占用过多篇幅,我们将该函数在其他数据库中的实现放在了 GitHub 上,可以点击链接下载。
函数可以在查询语句中直接使用,我们执行以下语句获取每个部门的总月薪值:
SELECT dept_name, getDeptTotalSalary(dept_id) FROM department; DEPT_NAME|GETDEPTTOTALSALARY(DEPT_ID)| ————-|—————————————-|_ 行政管理部 | 80000| 人力资源部 | 39500| 财务部 | 18000| 研发部 | 68200| 销售部 | 40100| 保卫部 | | 复制
小结
存储过程和函数是数据库提供的编程语言,可以在数据库中实现业务逻辑的处理。我们只是介绍了几个简单的示例,存储过程和函数支持的功能还包括条件判断(IF、CASE WHEN)、循环处理(FOR、WHILE)、游标(CURSOR)、异常处理(EXCEPTION)、动态 SQL 语句等。
参考资料
练习题:创建 2 个存储过程,分别用于修改员工信息(update_employee_byid)以及按照工号删除员工信息(delete_employee_byid)。

若有收获,就点个赞吧
0 人点赞
