上一篇我们介绍了触发器的概念和作用,演示了如何使用触发器实现自动的数据审计。到目前为止,我们已经学习了许多 SQL 基础查询、高级分析以及数据库设计和开发的实用技能。
今天我们开始扩展篇的学习。首先,让我们深入到数据库服务器的内部,探索一下 SQL 查询的执行过程。
SQL 查询执行过程
不同数据库对于 SQL 语句的执行过程采用了各自的实现方式;我们虽然不能通过一篇文章涵盖这些实现细节,但是可以尝试概括其中的关键过程和差异之处。简单来说,一个 SQL 查询语句从客户端的提交开始直到服务器返回最终的结果,整个过程大致如下图所示: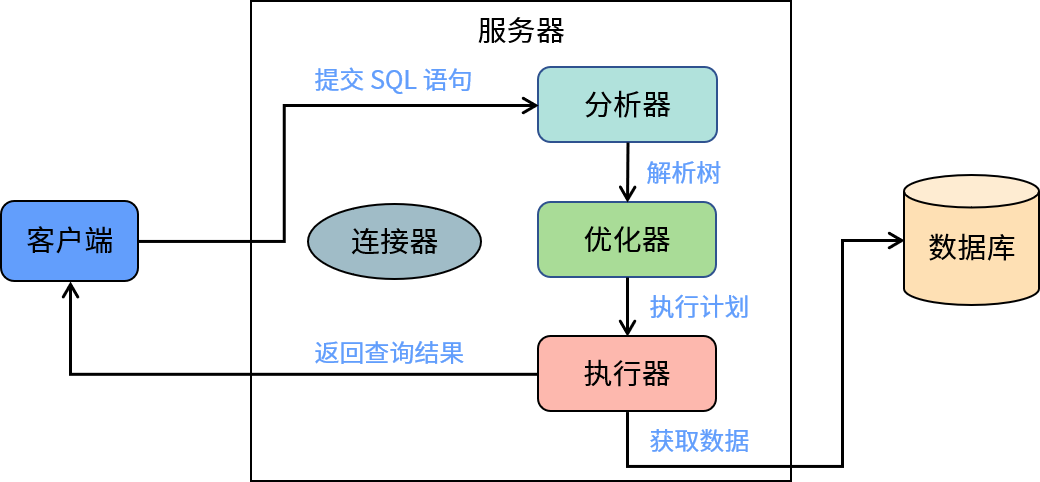
第一步:客户端提交 SQL 语句。当然,在此之前客户端必须连接到数据库服务器。在上图中的连接器就是负责建立和管理客户端的连接。
第二步:分析器/解析器。分析器首先解析 SQL 语句,识别出各个组成部分;然后进行语法分析,检查 SQL 语句的语法是否符合规范。例如,以下语句中的 FROM 写成了 FORM:
SELECT FORM employee WHERE empid = 1; — Oracle SQL Error [923] [42000]: ORA-00923: FROM keyword not found where expected — MySQL SQL Error [1064] [42000]: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ‘FORM employee WHERE emp_id = 1’ at line 2 — SQL Server SQL Error [102] [S0001]: Incorrect syntax near ‘FORM’. — PostgreSQL_ SQL Error [42601]: ERROR: syntax error at or near “FORM” Position: 13 复制
数据库返回了一个语法错误。
接下来是语义检查,确认查询中的表或者字段等对象是否存在,用户是否拥有访问权限等。例如,以下语句写错了表名:
SELECT FROM employe WHERE empid = 1; — Oracle SQL Error [942] [42000]: ORA-00942: table or view does not exist — MySQL SQL Error [1146] [42S02]: Table ‘hrdb.employe’ doesn’t exist — SQL Server SQL Error [208] [S0002]: Invalid object name ‘employe’. — PostgreSQL_ SQL Error [42P01]: ERROR: relation “employe” does not exist Position: 18 复制
数据库显示对象不存在或者无效。这一步还包括处理语句中的表达式,视图转换等。
第三步:优化器。利用数据库收集到的统计信息决定 SQL 语句的最佳执行方式。例如,使用索引还是全表扫描的方式访问单个表,使用什么顺序连接多个表。优化器是决定查询性能的关键组件,而数据库的统计信息是优化器判断的基础。
第四步:执行器。根据优化之后的执行计划,调用相应的执行模块获取数据,并返回给客户端。对于 MySQL 而言,会根据表的存储引擎调用不同的接口获取数据。PostgreSQL 12 版本开始引入类似的插件存储引擎功能。
以上流程在各种数据库中大体相同,但还有一些重要的组件就是缓存:
查询缓存。MySQL 5.7 之前的版本有一个查询缓存模块,以 key-value 的形式缓存了执行过的查询语句和结果集。但是查询缓存的失效频率非常高;因为只要有任何更新,表上所有的查询缓存都会被清空。因此,MySQL 8.0 版本删除了查询缓存的模块。- 查询计划缓存。对于完全相同的 SQL 语句,利用已经缓存的执行计划,从而跳过解析和生成执行计划的过程。Oracle 和 SQL Server 都提供了查询计划缓存;MySQL 和 PostgreSQL 的查询计划在使用预编译语句(Prepared Statement )时被缓存,但只在当前会话中有效。
- 数据缓存。对于已经访问过的磁盘数据(表和索引),在缓冲区中进行缓存;下次访问时可以直接读取内存中的数据。数据缓存可以明显提高数据访问的速度,已经成为了各种数据库的标配。
从以上流程可以看出,执行计划是决定查询性能的关键;因此学会查看执行计划是进行 SQL 语句优化的基础。
查看执行计划
执行计划是数据库执行 SQL 语句的各个步骤的组合,主要包括:
- 访问表的方式,通过索引访问还是全表扫描获取表中的数据等;
- 多表连接的方式,使用嵌套循环、排序合并还是哈希连接;包括多表连接的先后顺序;
- 分组聚合以及排序操作的实现方式等。
查看 SQL 语句执行计划的方式有许多种,包括各种图形化的管理工具。下图是使用 DBeaver 工具查看 MySQL 数据库执行计划的结果。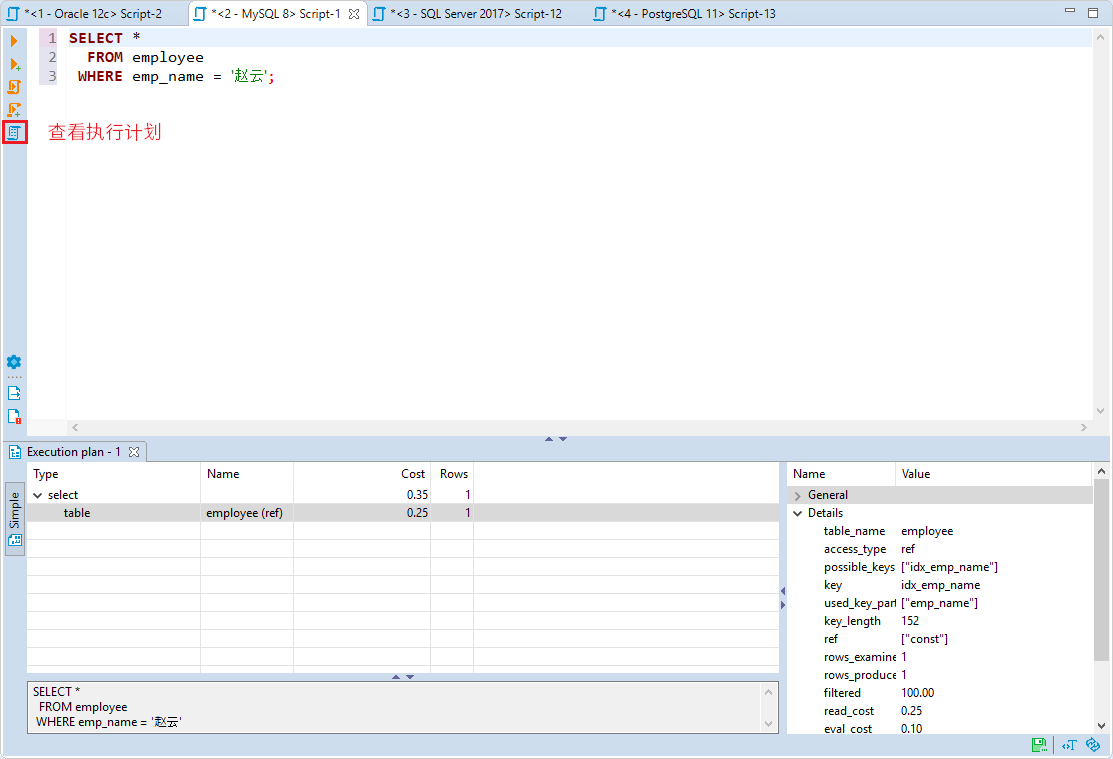
执行计划一般按照层次进行缩进,缩进最大的最先执行;缩进相同时,从上往下执行。我们将在下文介绍如何阅读和理解执行计划。
有时候我们无法使用图形工具连接数据库。因此,我们介绍一个更加通用的方法,使用命令查看执行计划。大部分数据库都支持使用 EXPLAIN 命令查看执行计划:
— MySQL 和 PostgreSQL 查看执行计划 EXPLAIN SELECT FROM employee WHERE empname = ‘赵云’; 复制
以上命令在 MySQL 和 PostgreSQL 中运行的结果分别如下:
— MySQL 执行计划结果 id|select_type|table |partitions|type|possible_keys|key |key_len|ref |rows|filtered|Extra| —|—————-|————|—————|——|——————-|——————|———-|——-|——|————|——-| 1|SIMPLE |employee| |ref |idx_emp_name |idx_emp_name|152 |const| 1| 100| | — PostgreSQL 执行计划结果 QUERY PLAN | ——————————————————————————————————————-| Index Scan using idx_emp_name on employee (cost=0.14..8.16 rows=1 width=422)| Index Cond: ((emp_name)::text = ‘赵云’::text) | 复制
简单来说,以上查询计划使用了索引 idx_emp_name 扫描进行数据查找。
Oracle 中同样可以使用 EXPLAIN 命令生成执行计划,不过需要执行两条命令:
— Oracle 查看执行计划_ EXPLAIN PLAN FOR SELECT FROM employee WHERE empname = ‘赵云’; SELECT FROM *TABLE(dbms_xplan.display); PLAN_TABLE_OUTPUT | ——————————————————————————————————————————————————| Plan hash value: 813175178 | | ——————————————————————————————————————————————————| | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time || ——————————————————————————————————————————————————| | 0 | SELECT STATEMENT | | 1 | 56 | 2 (0)| 00:00:01 || | 1 | TABLE ACCESS BY INDEX ROWID BATCHED| EMPLOYEE | 1 | 56 | 2 (0)| 00:00:01 || | 2 | INDEX RANGE *SCAN | IDX_EMP_NAME | 1 | | 1 (0)| 00:00:01 || ——————————————————————————————————————————————————| | Predicate Information (identified by operation id): | —————————————————————————- | | 2 - access(“EMP_NAME”=’赵云’) | 复制
首先,使用 EXPLAIN PLAN FOR 命令生成执行计划并存储到系统表 PLAN_TABLE 中;然后,通过一个查询语句显示查询计划;dbms_xplan.display 是一个 Oracle 系统函数。结果显示该语句在 Oracle 中同样是通过 IDX_EMP_NAME 索引范围扫描进行数据访问。
SQL Server 中查看执行计划的命令不太相同:
— SQL Server 查看执行计划 SET STATISTICS PROFILE ON SELECT FROM employee *WHERE emp_name = ‘赵云’; emp_id|emp_name|sex|dept_id|manager|hire_date |job_id|salary |bonus |email | ———|————|—-|———-|———-|—————|———|————|———-|—————————| 9|赵云 |男 | 4| 1|2005-12-19| 7|15000.00|6000.00|zhaoyun@shuguo.com| Rows|Executes|StmtText |StmtId|NodeId|Parent|PhysicalOp |LogicalOp |Argument |DefinedValues |EstimateRows|EstimateIO |EstimateCPU |AvgRowSize|TotalSubtreeCost |OutputList |Warnings|Type |Parallel|EstimateExecutions| ——|————|——————————————————————————————————————————————————————————————————————-|———|———|———|——————————|——————————|—————————————————————————————————————————————————————————|———————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————-|——————|——————————-|——————————-|—————|——————————-|———————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————-|————|————|————|—————————| 1| 1|SELECT FROM [employee] WHERE [emp_name]=@1 | 1| 1| 0| | | | | 1| | | |0.0033094999380409718| | |*SELECT | 0| | 1| 1| |—Clustered Index Scan(OBJECT:([hrdb].[dbo].[employee].[PKemployee1299A8619C254354]), WHERE:([hrdb].[dbo].[employee].[empname]=’赵云’))| 1| 2| 1|Clustered Index Scan|Clustered Index Scan|OBJECT:([hrdb].[dbo].[employee].[PKemployee1299A8619C254354]), WHERE:([hrdb].[dbo].[employee].[emp_name]=’赵云’)|[hrdb].[dbo].[employee].[emp_id], [hrdb].[dbo].[employee].[emp_name], [hrdb].[dbo].[employee].[sex], [hrdb].[dbo].[employee].[dept_id], [hrdb].[dbo].[employee].[manager], [hrdb].[dbo].[employee].[hire_date], [hrdb].[dbo].[employee].[job_id], [hrdb].[dbo].| 1|0.0031250000465661287|1.8449999333824962E-4| 104|0.0033094999380409718|[hrdb].[dbo].[employee].[emp_id], [hrdb].[dbo].[employee].[emp_name], [hrdb].[dbo].[employee].[sex], [hrdb].[dbo].[employee].[dept_id], [hrdb].[dbo].[employee].[manager], [hrdb].[dbo].[employee].[hire_date], [hrdb].[dbo].[employee].[job_id], [hrdb].[dbo].| |PLAN_ROW| 0| 1| SET STATISTICS PROFILE OFF 复制
首先,使用 SET STATISTICS PROFILE ON 打开 SQL 语句执行统计;然后执行 SQL 语句,除了产生查询结果之外,还输出了关于该语句的执行计划;最后,关闭统计分析。该语句在 SQL Server 中使用了基于主键(聚集索引)的索引扫描访问数据。
接下来我们需要理解执行计划中每个步骤的含义,从而分析 SQL 语句的性能问题并提出优化方法。
理解执行计划
虽然各个数据库使用的术语不同,但是查询计划包含的内容大同小异。我们以 MySQL 为例,介绍执行计划中常见的一些信息和含义。首先,我们来看一下语句的执行计划:
— MySQL EXPLAIN SELECT FROM department d JOIN employee e ON (d.dept_id = e.dept_id) JOIN job j ON (j.job_id = e.job_id) WHERE d.dept_name = ‘研发部’ ORDER BY e.salary *DESC; id|selecttype|table|partitions|type |possible_keys |key |key_len|ref |rows|filtered|Extra | —|—————-|——-|—————|———|————————————|——————|———-|———————|——|————|——————————————————————|_ 1|SIMPLE |d | |ALL |PRIMARY | | | | 6| 16.67|Using where; Using temporary; Using filesort| 1|SIMPLE |e | |ref |idx_emp_dept,idx_emp_job|idx_emp_dept|4 |hrdb.d.dept_id| 5| 100| | 1|SIMPLE |j | |eq_ref|PRIMARY |PRIMARY |4 |hrdb.e.job_id | 1| 100| | 复制
MySQL 中的查询计划包含了 12 项信息:
- id,一个数字序列,表示该查询中各个子查询的执行顺序。id 越大的子查询越先执行,id 相同的子查询从上至下执行;id 为 NULL 表示临时结果集,例如 UNION 操作的结果集。以上示例中只有一个 SELECT 子句,所以序列号为 1。
- select_type,每个子查询的类型。常见的类型包括:
- SIMPLE,不包含子查询或 UNION 操作的简单查询;以上示例就是一个简单的查询;
- PRIMARY,包含子查询的最外层查询;
- UNION,UNION 中的第二个或后面的 SELECT 语句;
- DEPENDENT UNION,依赖于外查询的 UNION 中的第二个或后面的 SELECT 语句;
- UNION RESULT,UNION 操作的结果集;
- SUBQUERY,子查询中的第一个 SELECT 语句;
- DEPENDENT SUBQUERY,关联子查询中的第一个 SELECT 语句;
- DERIVED,FROM 子句中的子查询,也就是派生表;
- DEPENDENT DERIVED,依赖于另一个表的派生表;
- MATERIALIZED,物化子查询;
- UNCACHEABLE SUBQUERY,无法缓存结果的关联子查询,对于外查询中的每一行都需要重新计算;
- UNCACHEABLE UNION,UNION 中的第二个或后面的 SELECT 语句是一个 UNCACHEABLE SUBQUERY;
- table,数据行对应的来源表;有可能是基础表、派生表(
)、UNION 操作的结果( ),M 和 N 分别对应执行计划中的 id。 - partitions,如果数据行来自于表的分区,则显示相应的分区;以上示例没有使用分区表,显示为 NULL。
- type,表的访问和连接方式。按照性能从好到坏依次为:
- system,表中只有一行数据,相当于系统表;
- const,最多返回一条记录,通常表示使用主键或者唯一索引查找单个值;
- eq_ref,对于前面的每行数据,从该表中读取一行。这是除了system 和 const 类型之外最好的连接方式,意味着在连接查询中使用了 PRIMARY KEY 或者 UNIQUE NOT NULL 索引进行关联。以上示例中的 job 就是利用主键进行关联。
- ref,对于前面的每行数据,使用该表中的非唯一索引查找数据。以上示例中,employee 表通过索引 idx_emp_dept 进行关联。
- fulltext,使用全文索引进行连接查询;
- ref_or_null,类似于 ref,但是包含了额外的 NULL 值查找;
- index_merge,表示使用了索引合并优化的方式查找数据;
- uniquesubquery_,在以下形式的 IN 子查询中代替 eq_ref:value IN (SELECT primary_key FROM single_table WHERE some_expr);
- indexsubquery_,类似于 unique_subquery,但是针对子查询返回非唯一索引的情况:value IN (SELECT key_column FROM single_table WHERE some_expr) ;
- range,通过索引检索指定范围内的数据行;
- index,与下面的 ALL 相同,只是通过索引扫描进行查找。index 通常比 ALL 更快快,因为索引文件通常比数据文件更小。
- ALL,对于前面的每行数据,对该表进行全表扫描。通常来说这是一个非常差的查找方式,一般可以通过增加索引的方式进行优化。
- possible_keys,可能使用的索引,但实际不一定使用。当该列显示为 NULL 时就要考虑是否需要通过索引进行优化了。
- key,显示实际使用的索引。如果该字段显示为NULL,意味着没有使用索引。 示例中的 department 没有使用索引,因为 dept_name 没有索引。
- key_len,显示使用的 key 的长度。可以用于判断使用了多列索引中的哪些列。
- ref,显示使用哪个列或常量与 key 中的索引进行比较,从而返回表中的数据行。
- rows,执行查询时必须检查的行数,是一个估计值。示例中的 department 表需要扫描全部的 6 条记录。
- filtered, 通过条件过滤得到的行数的百分比,也是一个估计值。 示例中的 department 表通过 dept_name 预计得到 1 条记录,也就是 1/6(16.67%)。
- Extra,包含更多的详细信息。常见的信息包括:
- Using where,使用 WHERE 子句限定传递给下一个表或者发送给客户端的数据行;以上示例使用了 dept_name 进行过滤;
- Using filesort,表示需要执行一次额外的遍历,从而按照排序顺序返回数据行。以上示例使用 salary 字段进行排序;
- Using temporary,表示需要创建一个临时表来处理结果。以上示例使用 salary 字段进行排序时需要创建临时表;
- Using index,直接通过索引返回数据,不需要访问表中的数据。
其他数据库的执行计划也可以通过上文介绍的方法查看。关于执行计划的详细信息,可以参考以下文档:
- MySQL 官方文档。
- Oracle 官方文档。
- SQL Server 官方文档。
- PostgreSQL 官方文档。
小结
一个查询语句大概需要经过分析器、优化器、执行器的处理并返回最终结果,同时还可能利用各种缓存功能提高查询的性能。决定查询性能的主要因素就是执行计划,大多数数据库可以通过 EXPLAIN 命令查看执行计划。理解执行计划是进行查询优化的关键。
练习题:查看并解读以下查询语句的执行计划:
SELECT d.dept_name AS “部门名称”, (SELECT AVG(salary) AS avg_salary FROM employee WHERE dept_id = d.dept_id) AS “平均月薪” FROM department d ORDER BY d.dept_id;

若有收获,就点个赞吧
0 人点赞
