上一篇我们介绍了如何在 SQL 语句中使用连接查询(JOIN)获取多个表中的关联数据,具体讨论了内连接、左/右/全外连接、交叉连接、自然连接以及自连接的原理和使用方法。
除了连接查询,SQL 还提供了另一种同时查询多个表的方法:子查询(Subquery)。本篇我们就来了解一下各种类型的子查询和相关的运算符。
什么是子查询?
我们先来考虑一个问题,哪些员工的月薪大于所有员工的平均月薪?可以先使用 AVG 函数获取所有员工的平均月薪:
SELECT AVG(salary) FROM employee; AVG(salary)| —————-| 9832.000000| 复制
然后将该查询的结果作为下面语句的查询条件,返回月薪大于 9832 的员工:
SELECT emp_name, salary FROM employee WHERE salary > 9832; 复制
该语句的结果如下: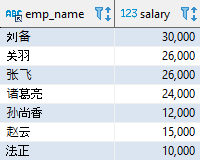
我们使用了两个查询来解决这个简单的问题,然而实际应用中的需求往往更加复杂;显然我们需要更加高级的查询功能。
SQL 提供了一种查询方式叫做子查询,可以非常容易地解决这个问题:
SELECT emp_name, salary FROM employee WHERE salary > ( SELECT AVG(salary) FROM employee ); 复制
该示例中包含两个查询语句(SELECT);括号内部的查询称为子查询,用于获得员工的平均月薪;包含子查询的查询称为外部查询,用于返回月薪大于平均月薪的员工的信息。该查询的最终结果与上面的示例相同。
简单来说,子查询是指嵌套在其他语句(SELECT、INSERT、UPDATE、DELETE 等)中的 SELECT 语句;子查询也称为内查询(inner query)或者嵌套查询(nested query);子查询必须位于括号之中。
SQL 中的子查询可以分为以下三种类型:
- 标量子查询(Scalar Subquery):返回单个值(一行一列)的子查询。上面的示例就是一个标量子查询。
- 行子查询(Row Subquery):返回单行结果(一行多列)的子查询,标量子查询是行子查询的一个特例。
- 表子查询(Table Subquery):返回一个虚拟表(多行多列)的子查询,行子查询是表子查询的一个特例。
标量子查询
标量子查询的结果就像一个常量一样,可以用于 SELECT、WHERE、GROUP BY、HAVING 以及 ORDER BY 等子句中。以下示例在 SELECT 列表中使用标量子查询计算员工的月薪与平均月薪的差值:
SELECT emp_name, salary, salary - (SELECT AVG(salary) FROM employee) AS salary_diff FROM employee WHERE emp_id <= 6; 复制
该语句执行的结果如下: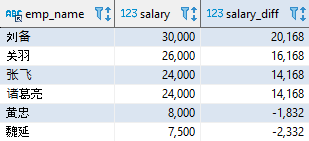
salary_diff 的结果代表了员工月薪与平均月薪的差距。行子查询
行子查询可以当作一个一行多列的临时表使用。以下语句查找所有与“孙乾”在同一个部门并且职位相同的员工:
— Oracle、MySQL 以及 PostgreSQL 实现 SELECT emp_name, dept_id, job_id FROM employee WHERE (dept_id, job_id) = (SELECT dept_id, job_id FROM employee WHERE emp_name = ‘孙乾’) AND emp_name != ‘孙乾’; 复制
子查询返回了“孙乾”所在的部门编号和职位编号,这两个值构成了一行数据;然后外部查询的 WHERE 条件使用该数据进行过滤,AND 操作符用于排除“孙乾”自己。该语句执行的结果如下: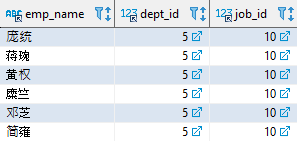
行子查询的实际使用较少,SQL Server 中不支持行子查询。表子查询
当子查询返回的结果包含多行数据时,称为表子查询。表子查询通常用于查询条件或者 FROM 子句中。查询条件中的子查询
对于 WHERE 中的子查询,需要注意外部查询的条件中不能使用比较运算符。以下是一个错误的示例:
— 错误示例 SELECT empname FROM employee WHERE job_id = (SELECT job_id FROM employee WHERE dept_id = 3); 复制
该语句执行时将会返回一个错误信息:单行子查询返回了多行数据。因为财务部(编号为 3)中包含多个不同的职位,单个值(外部查询条件中的 job_id)与多个值(子查询结果中的多个 job_id 值)不能使用比较运算符(=、!=、<、<=、>、>=)进行判断。
对于这种可能返回多行数据的表子查询,可以使用 IN 和 NOT IN 运算符进行判断。以上示例可以使用 IN 运算符改写如下:
SELECT emp_name FROM employee WHERE job_id IN (SELECT job_id FROM employee WHERE dept_id = 3); emp_name| ————|_ 孙尚香 | 孙丫鬟 | 复制
IN 运算符用于判断查询条件中的字段取值是否位于子查询返回的列表之中。该语句实际上是返回了财务部门所有的员工。
除了 IN 运算符之外,ALL、ANY/SOME 运算符与比较运算符的结合也可以用于判断子查询的结果。ALL、ANY/SOME 运算符
ALL 运算符与比较运算符(=、!=、<、<=、>、>=)结合表示等于、不等于、小于、小于等于、大于或者大于等于子查询结果中的所有值。以下示例查找入职日期晚于研发部所有员工的员工信息:
SELECT emp_name, hire_date FROM employee WHERE hire_date > ALL (SELECT e.hire_date FROM employee e JOIN department d ON (d.dept_id = e.dept_id) WHERE d.dept_name = ‘研发部’); 复制
其中,子查询返回了研发部所有员工的入职日期;“> ALL”表示比结果中的所有值都大,也就是大于结果中的最大值。该查询的结果如下: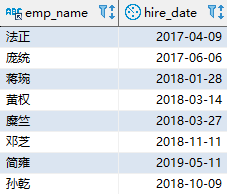
研发部最晚入职的是“马岱”,入职日期为 2014 年 9 月 16 日;所以该查询返回的是这个日期之后入职的员工。
ANY/SOME 运算符与比较运算符(=、!=、<、<=、>、>=)结合表示等于、不等于、小于、小于等于、大于或者大于等于子查询结果中的任意值。上一节中的 IN 运算符示例可以使用 ANY/SOME 运算符改写如下:
SELECT emp_name FROM employee WHERE job_id = ANY (SELECT job_id FROM employee WHERE dept_id = 3); 复制
该查询同样返回了财务部门所有的员工。FROM 中的子查询
在 FROM 中的子查询相当于一个临时表。以下语句查找各个部门的名称和平均月薪:
SELECT d.dept_name AS “部门名称”, ds.avg_salary AS “平均月薪” FROM department d LEFT JOIN (SELECT dept_id, AVG(salary) AS avg_salary FROM employee GROUP BY dept_id) ds ON (d.dept_id = ds.dept_id); 复制
其中,JOIN 后面的子查询创建了一个临时表(表名为 ds),它包含了各个部门的编号和平均月薪;然后将表 department 与 ds 进行左外连接查询。该查询最终返回了每个部门的名称和平均月薪: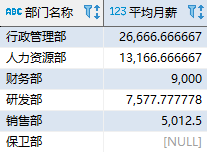
左外连接确保了不会丢失“保卫部”的信息,即使它目前还没有任何员工。
各种数据库对于 FROM 中的子查询叫法不同。例如,MySQL 中称为派生表(derived table),Oracle 中称为内联视图(inline view)。
除了按照返回的结果分类之外,子查询还可以按照另一种方式进行分类:关联子查询(Correlated Subquery)和非关联子查询(Non-correlated Subquery)。关联子查询会引用外部查询中的列,从而与外部查询产生关联;非关联子查询与外部查询没有关联。上面的示例都属于非关联子查询。关联子查询
以下语句在 SELECT 列表中通过一个关联子查询获得各个部门的平均月薪:
SELECT d.dept_name AS “部门名称”, (SELECT AVG(salary) AS avg_salary FROM employee WHERE dept_id = d.dept_id) AS “平均月薪” FROM department d ORDER BY d.dept_id; 复制
其中,子查询的 WHERE 条件中使用了外查询的部门编号字段(d.dept_id),因而与外查询产生关联。该语句执行时,外查询先检索出所有的部门数据,针对每条记录再将 d.dept_id 传递给子查询;子查询返回每个部门的平均月薪。该查询的结果与上一节示例相同。
关联子查询对于外查询中的每行数据都会运行一次(数据库可能会对此进行优化),而非关联子查询只会执行一次。
在 WHERE 子句中也可以使用关联子查询。以下语句查找每个部门中最早入职的员工:
SELECT d.dept_name, o.emp_name, o.hire_date FROM employee o JOIN department d ON (d.dept_id = o.dept_id) WHERE o.hire_date = (SELECT MIN(i.hire_date) FROM employee i WHERE i.dept_id = o.dept_id); 复制
该语句执行时,先找到外查询中的每个员工;依次将 o.dept_id 传递给子查询,获取当前部门第一个员工的入职日期;再回到外查询进行判断,如果当前员工的入职日期满足条件就返回该记录。该查询的结果如下: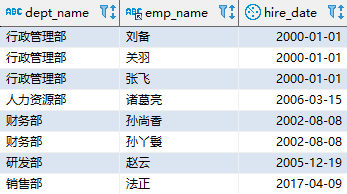
最后我们介绍一个与子查询相关的操作符:EXISTS。EXISTS 操作符
EXISTS 操作符用于判断子查询结果的存在性。如果子查询存在任何结果,EXISTS 返回真;否则,返回假。
以下语句查找存在女性员工的部门:
SELECT d.deptname FROM department d WHERE EXISTS ( SELECT 1 FROM employee e WHERE e.sex = ‘女’ AND e.dept_id = d.dept_id) ORDER BY dept_name; dept_name| ————-| 研发部 | 财务部 | 复制
EXISTS 之后是一个关联子查询,先执行外查询找到 d.dept_id;然后依次将 d.dept_id 传递给子查询,判断该部门是否存在女性员工;子查询一旦找到任何数据立即返回结果。EXISTS 只判断结果的存在性,因此子查询的 SELECT 列表中的内容无所谓,通常使用一个常量值。该查询的结果表明“研发部”和“财务部”存在女性员工。
EXISTS 只要找到任何数据,立即终止子查询的执行,因此可以提高查询的性能。
另外,NOT EXISTS 执行相反的操作。如果想要查找不存在女性员工的部门,可以将上例中的 EXISTS 替换成 NOT EXISTS。
现在,我们知道 [NOT] EXISTS 和 [NOT] IN 都可以用于判断子查询返回的结果。但是它们之间存在一个重要的区别:[NOT] EXISTS 只检查存在性,[NOT] IN 需要比较实际的值是否相等。因此,当子查询的结果包含 NULL 值时,EXISTS 仍然返回结果,NOT EXISTS 不返回结果;但是此时 IN 和 NOT IN 都不会返回结果,因为 (X = NULL) 和 NOT (X = NULL) 的结果都是未知。
以下示例用于查找没有员工的部门,演示了这两者之间的区别:
SELECT d.dept_name FROM department d WHERE NOT EXISTS ( SELECT NULL FROM employee e WHERE e.dept_id = d.dept_id) ORDER BY dept_name; dept_name| ————-| 保卫部 | SELECT d.dept_name FROM department d WHERE d.dept_id NOT IN ( SELECT NULL FROM employee e) ORDER BY dept_name; dept_name| ————-|_ 复制
第一个查询使用了 NOT EXISTS,子查询中除了“保卫部”之外的部门都有返回结果(NULL 也是结果),所以外查询只返回“保卫部”。第二个查询使用了 NOT IN,子查询中返回的都是 NULL 值;d.dept_id = NULL 的结果是未知,加上 NOT 之后仍然未知,所以查询没有返回任何结果。
通常来说,[NOT] EXISTS 的性能比 [NOT] IN 更好,尽量使用 [NOT] EXISTS。
我们还可以在子查询中包含其他的子查询,实现嵌套子查询。小结
子查询语句为我们提供了在一个查询中访问多个表的另一种方式,很多时候可以实现与连接查询相同的效果。本篇我们讨论了各种形式的子查询,包括相关的操作符和注意事项。
练习题:上一篇的练习题中,我们使用连接查询找出 2019 年 1 月份的员工缺勤记录。对于同样的问题,如何使用子查询解决?

若有收获,就点个赞吧
0 人点赞
