上一篇我们讨论了如何使用 LIKE 运算符和正则表达式函数进行文本数据的模糊查找。当你在运行前面几篇文章中的示例时,得到的结果可能与文章中不完全一致,主要是数据的显示顺序可能不同。这是因为 SQL 在查询时不保证返回结果的顺序。
如果想要查询的结果按照某种规则进行排序,例如按照工资从高到低排序,可以使用 SQL 中的 ORDER BY 子句。
单列排序
按照单个字段或者表达式的值进行排序称为单列排序。单列排序的语法如下:
SELECT col1, col2, ...FROM tORDER BY col1 [ASC | DESC];
其中,ORDER BY 用于指定排序的字段;ASC 表示升序排序(Ascending),DESC 表示降序排序(Descending),默认值为升序排序。以下是排序操作的示意图:
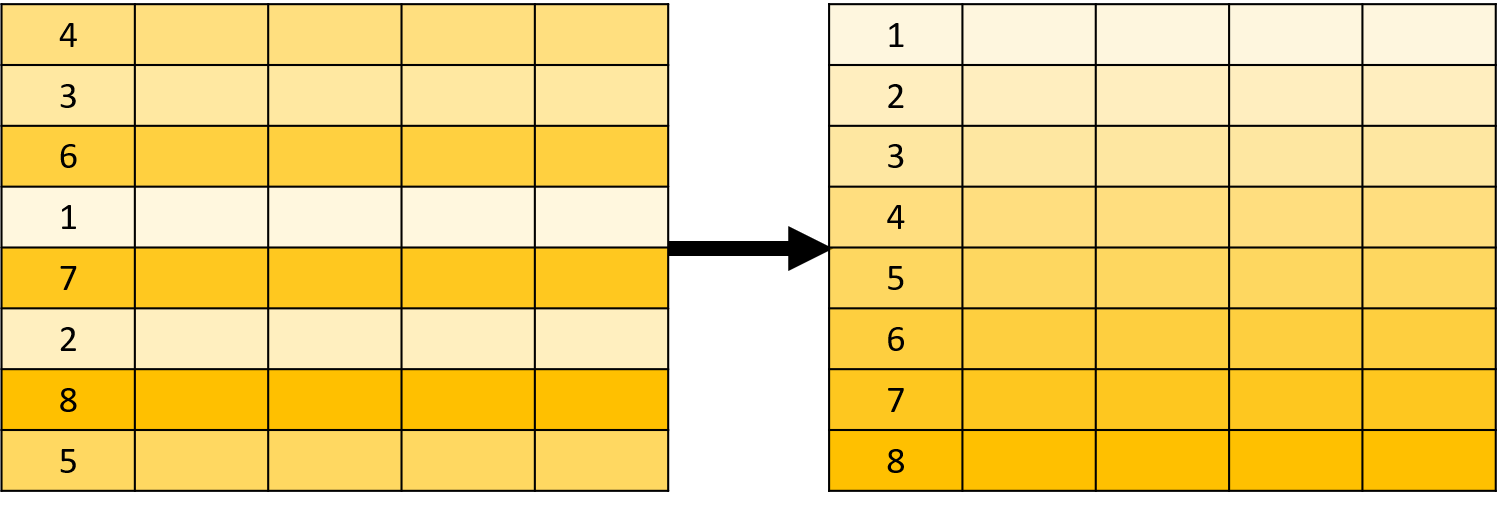
以下示例查询研发部门(dept_id = 4)的员工信息,并且按照月薪从高到低排序显示:
SELECT emp_name, salary, hire_dateFROM employeeWHERE dept_id = 4ORDER BY salary DESC;
该查询中使用了 WHERE 过滤条件,此时 ORDER BY 子句位于 WHERE 之后。该语句执行的结果如下:
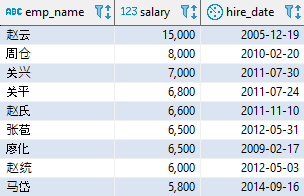
对于升序排序,数字按照从小到大的顺序排列,字符按照编码的顺序排列,日期时间按照从早到晚的顺序排列;降序排序正好相反。
在上面的查询结果中,“张苞”和“廖化”的月薪都是 6500。那么他们俩谁排在前面,谁排在后面呢?答案是不确定。如果要解决这个问题,需要使用多列排序。
多列排序
多列排序是指基于多个字段或表达式的排序,使用逗号进行分隔。多列排序的语法如下:
SELECT col1, col2, ...FROM tORDER BY col1 ASC, col2 DESC, ...;
首先基于第一个字段进行排序;对于第一个字段排序相同的数据,再基于第二个字段进行排序;依此类推。
以下语句查询研发部门(dept_id = 4)的员工信息,并且按照月薪从高到低排序,月薪相同时再按照入职先后进行排序:
SELECT emp_name, salary, hire_dateFROM employeeWHERE dept_id = 4ORDER BY salary DESC, hire_date;
该查询的结果如下: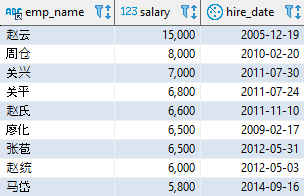
“廖化”排在了“张苞”之前,因为他的入职日期更早。
在指定排序字段时,除了使用字段名或者表达式之外,也可以使用这些字段在 SELECT 列表中出现的顺序表示。上面的示例可以改写如下:
SELECT emp_name, salary, hire_dateFROM employeeWHERE dept_id = 4ORDER BY 2 DESC, 3;
在 SELECT 列表中,salary 是第 2 个字段,hire_date 是第 3 个字段。因此该语句也是先按照月薪从高到低排序,月薪相同时再按照入职先后进行排序。
接下来我们讨论一类特殊的排序问题:中文排序。
中文排序
在创建数据库或者表时,我们会指定一个字符集(Charset)和排序规则(Collation)。
字符集决定了数据库能够存储哪些字符,比如 ASCII 字符集只能存储简单的英文、数字和一些控制字符;GB2312 字符集可以存储中文;Unicode 字符集能够支持世界上的各种语言。
排序规则定义了字符集中字符的排序顺序,包括是否区分大小写,是否区分重音等。对于中文而言,排序方式与英文有所不同;中文通常需要按照拼音、偏旁部首或者笔画进行排序。
如果想要支持中文排序,最简单的方式就是使用支持中文排序的排序规则;但是常见的 Unicode 字符集默认不支持中文排序。所以我们需要解决这种情况下的中文排序问题。
首先是 Oracle,使用 AL32UTF8 字符编码时不支持中文排序规则,可以通过一个转换函数实现该功能。以下示例按照员工姓名的拼音进行排序:
-- Oracle 实现中文拼音排序SELECT emp_nameFROM employeeWHERE dept_id = 4ORDER BY NLSSORT(emp_name,'NLS_SORT = SCHINESE_PINYIN_M');
NLSSORT 是一个函数,返回了按照某种排序规则得到的字符序列;SCHINESE_PINYIN_M 表示中文的拼音排序规则。该查询的结果如下: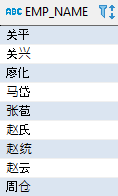
Oracle 还支持按偏旁部首进行排序:SCHINESERADICALM,以及按笔画进行排序:SCHINESESTROKEM。
再来看一下 MySQL 的中文排序。MySQL 8.0 默认使用 utf8mb4 字符编码,不支持中文排序规则。以下语句按照员工姓名的拼音进行排序:
-- MySQL 实现中文拼音排序SELECT emp_nameFROM employeeWHERE dept_id = 4ORDER BY CONVERT(emp_name USING GBK);
CONVERT 是一个函数,用于转换数据的字符集编码;这里是中文 GBK 字符集,默认使用拼音排序。该语句的结果和上面的 Oracle 示例一样。
对于 SQL Server,字符集和排序规则是同一个概念。如果需要存储中文,需要使用相应的排序规则,例如 Chinese_PRC_CS_AI_WS。以下查询按照员工姓名的拼音进行排序:
-- SQL Server 实现中文拼音排序SELECT emp_nameFROM employeeWHERE dept_id = 4ORDER BY emp_name COLLATE Chinese_PRC_CI_AI_WS;
COLLATE 表示按照某种排序规则进行排序;如果数据库使用的是 Chinese_PRC_CI_AI_WS 排序规则,可以省略 COLLATE 选项。该语句的结果和上面的 Oracle 示例一样。
SQL Server 还支持按笔画进行排序:ChinesePRCStrokeCIAI_WS。
最后,PostgreSQL 默认使用 UTF8 编码字符集,不支持中文排序规则。以下示例按照员工姓名的拼音进行排序:
-- PostgreSQL 实现中文拼音排序SELECT emp_nameFROM employeeWHERE dept_id = 4ORDER BY emp_name COLLATE "zh_CN";
COLLATE 指定了中文排序规则 zh_CN,该语句的结果和上面的 Oracle 示例一样。
对于排序操作,还需要注意空值的排序问题。
空值排序
空值(NULL)在 SQL 中表示未知或者缺失的值。如果排序的字段中存在空值时,应该如何处理呢?以下语句按照奖金从低到高进行排序:
SELECT emp_name, bonusFROM employeeWHERE dept_id = 2ORDER by bonus;
在 MySQL 和 SQL Server 中空值排在了最前,查询的结果如下: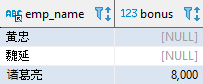
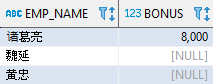
对于 Oracle 和 PostgreSQL 而言,也可以使用 NULLS FIRST 将空值排在最前,或者 NULLS LAST 将空值排在最后。以下语句返回的结果与 MySQL 和 SQL Server 一致:
-- Oracle 和 PostgreSQL 实现SELECT emp_name, bonusFROM employeeWHERE dept_id = 2ORDER by bonus NULLS FIRST;
总而言之:
- MySQL 和 SQL Server 认为空值最小,升序时空值排在最前,降序时空值排在最后;
- Oracle 和 PostgreSQL 认为空值最大,升序时空值排在最后,降序时空值排在最前;同时支持使用 NULLS FIRST 和 NULLS LAST 指定空值的顺序。
解决空值的排序问题还有一个更通用的方法,就是利用 COALESCE 函数将空值转换为一个指定的值。例如,将奖金为空的数据转换为 0,这样升序排序时一定在最前:
SELECT emp_name, COALESCE(bonus, 0) AS bonusFROM employeeWHERE dept_id = 2ORDER BY COALESCE(bonus, 0);
该语句的执行结果如下:
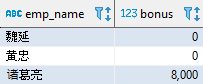
COALESCE 函数用于将 bonus 为空的数据转换为 0,关于空值处理的函数将会在第 15 篇中进行介绍。
小结
ORDER BY 子句可以将查询的结果按照某种规则进行排序。排序方式分为升序和降序;可以基于单列或表达式排序,也可以基于多列或多个表达式排序。中文排序需要字符集和排序规则的支持,不同数据库的实现各不相同。另外,还需要注意空值的排序问题。
练习题:查询所有的员工信息,按照员工的总收入(年薪加奖金)从高到低进行排序,总收入相同再按照姓名的拼音顺序排序。

若有收获,就点个赞吧
0 人点赞
