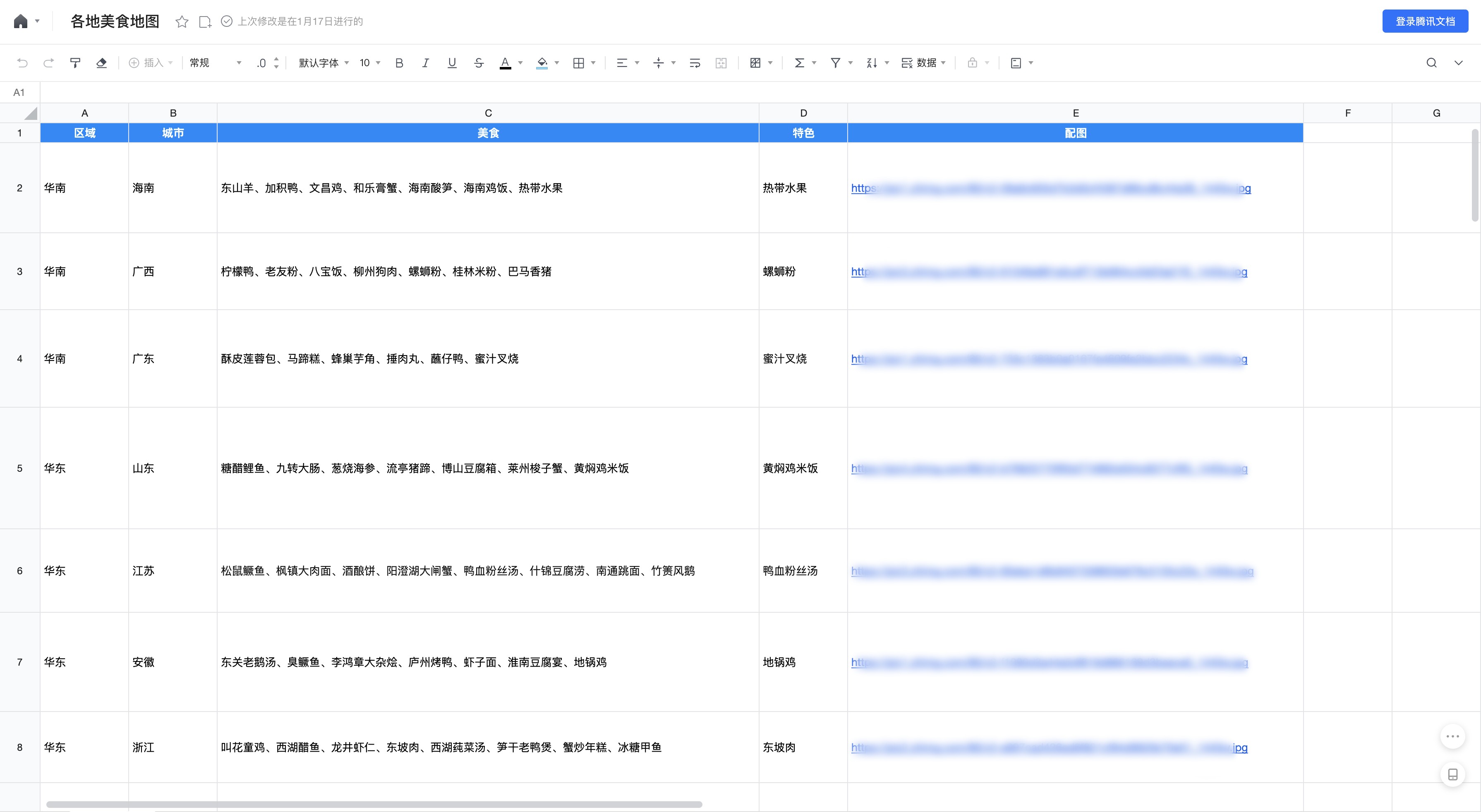
本文主要介绍如何使用自定义连接器实现将数据从腾讯在线文档同步至数据模型。例如,有一个美食地图的文档需要同步至微搭数据模型:
准备工作
步骤1:创建数据模型
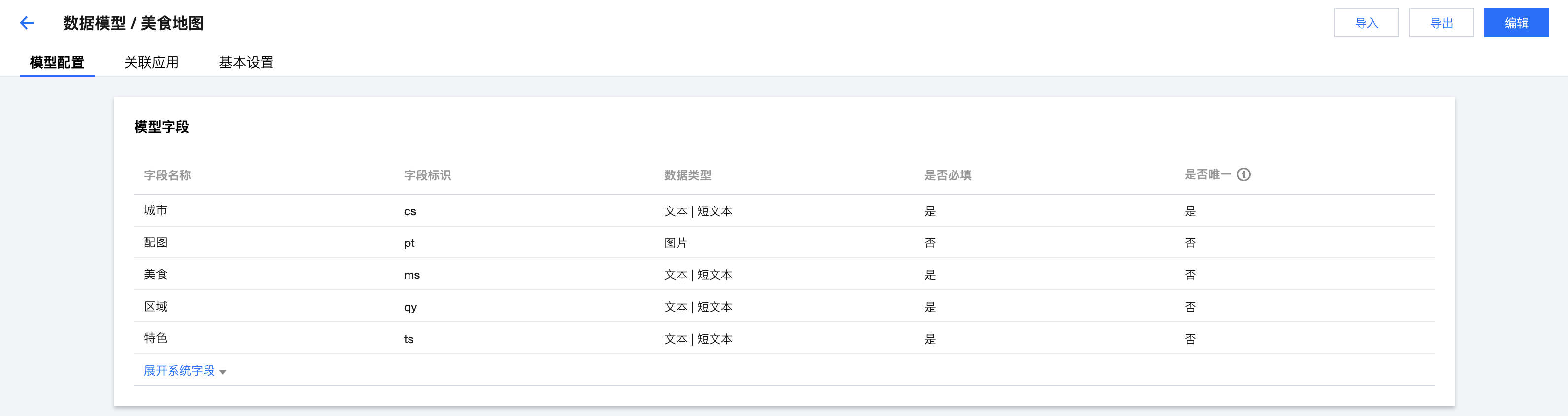
我们先 创建 一个名为美食地图的数据模型,该模型的字段分别对应在线表格的列。
步骤2:创建腾讯文档连接器
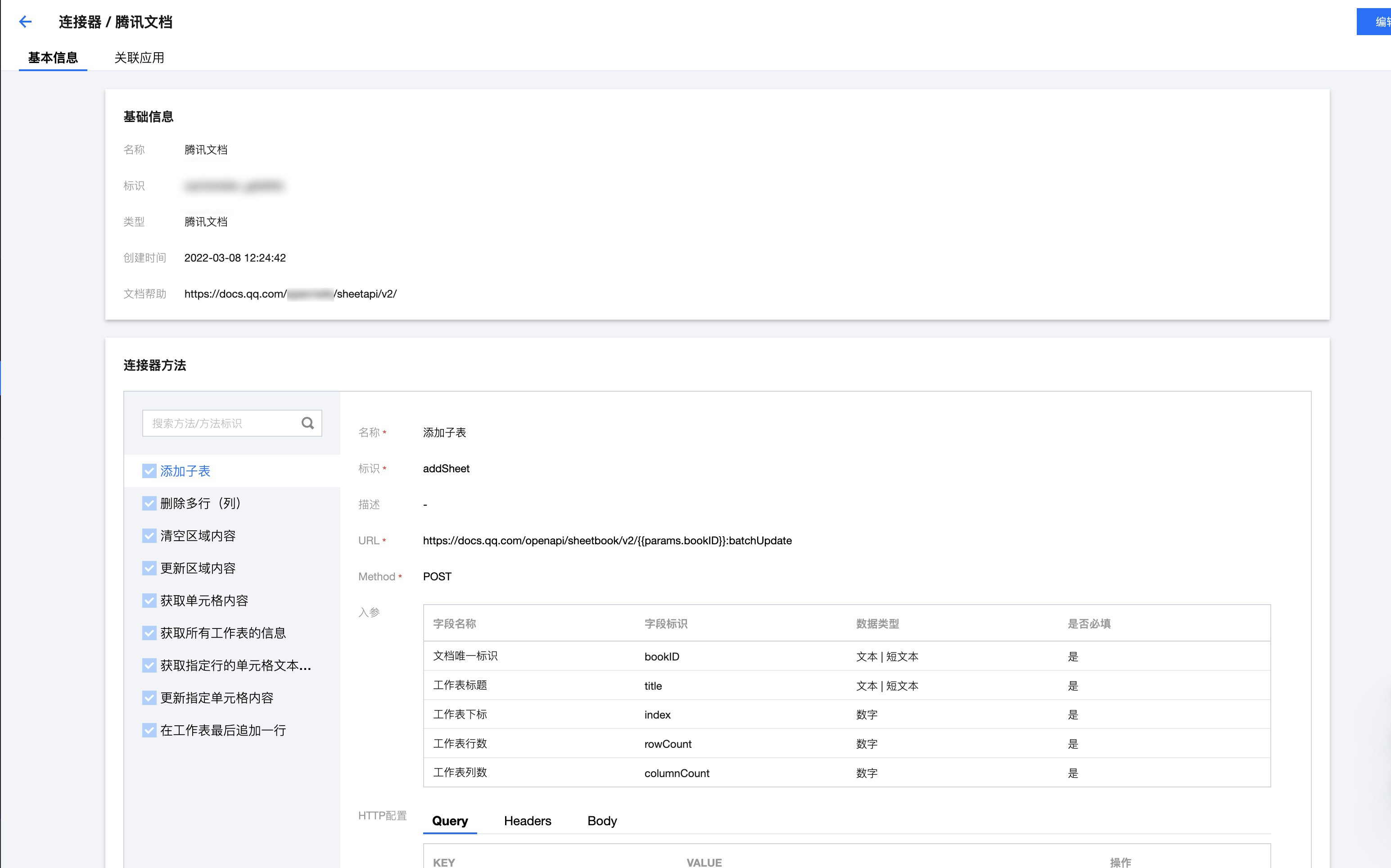
接下来我们需要 创建 一个腾讯文档连接器,这个连接器授权的账号为上述在线文档的所有者账号。
步骤3:创建自定义连接器
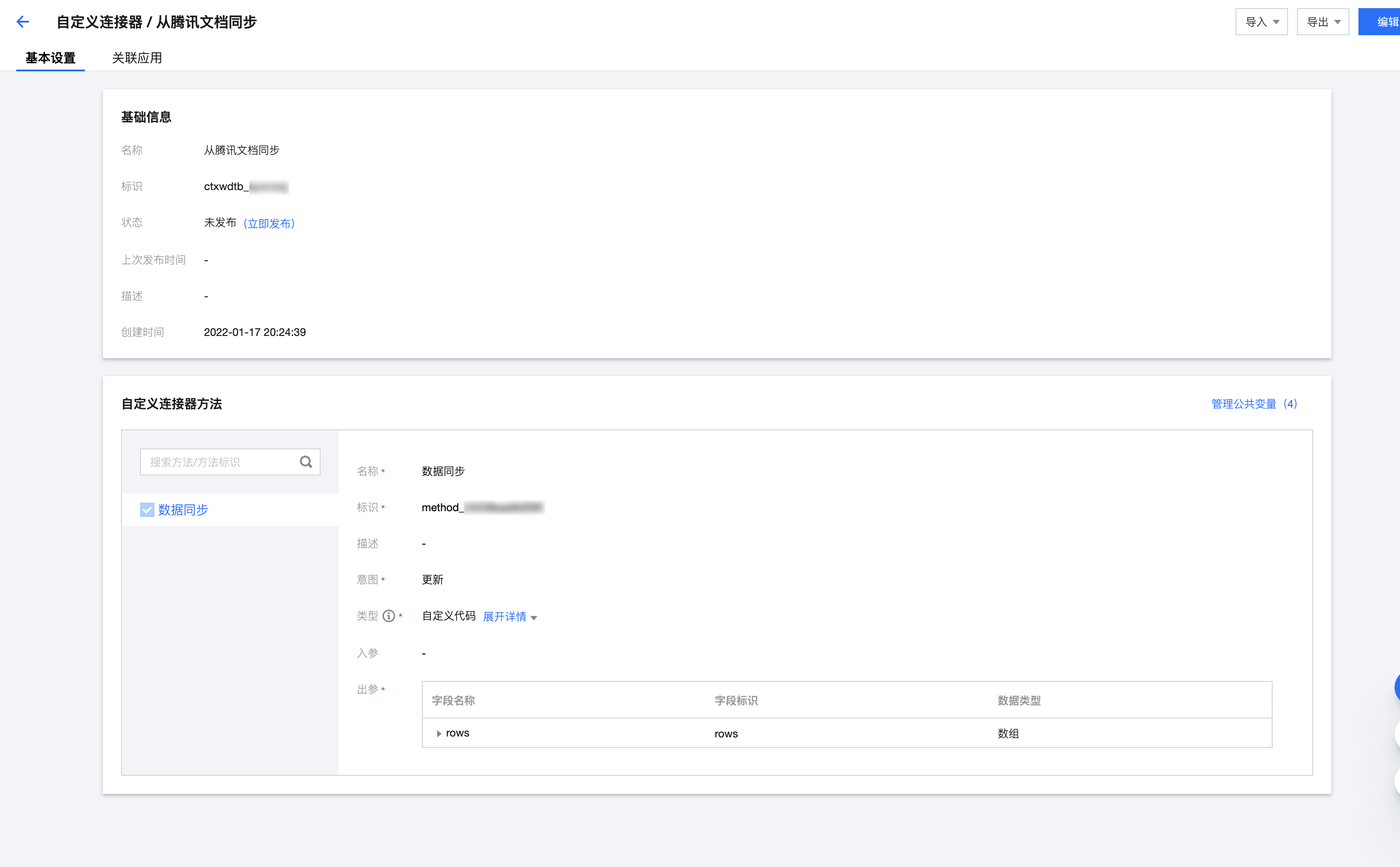
最后我们 创建 一个自定义连接器,该连接器用来编写同步数据逻辑。
自定义连接器方法
我们在自定义连接器中,创建一个数据同步的方法,该方法会处理以下两个事件:
从腾讯文档读取数据。
将数据写入数据模型。
::: js
module.exports = async function(params, context) {
const bookID = “DQ0tixxxxxxxlRbE1k”; // bookID 和 sheetID 可以从文档 URL 中获取 例如 https://docs.qq.com/sheet/DQ0tixxxxxxxlRbE1k?tab=BB08J2
const sheetID = “BB08J2”;
const { sheetData } = await context.callConnector({
name: ‘txwd_o6j7pzt’, // 腾讯文档连接器标识
methodName: ‘getSheets’, // 腾讯文档连接器方法标识
params: {
bookID,
},
});
const { rowCount } = sheetData[0];
const { rows } = await context.callConnector({
name: ‘txwd_o6j7pzt’, // 腾讯文档连接器标识
methodName: ‘getRows’, // 腾讯文档连接器方法标识
params: {
bookID,
sheetID,
rows:2-${rowCount}// 行范围,代表要读取的行。 以本示例举例,数据是从第二行开始。
},
});
const newRecords = [];
const columns = “qy|cs|ms|ts|pt”; // 这里代表在线文档的每一列按顺序和数据模型字段该如何映射,例如第一列映射为 qy(区域) 字段
// 下面将读取到的每一行数据做一个映射关系转化
for(let r = 0; r < rowCount - 1; r++) {
const { textValues } = rows[r];
const inputParams = {};
const cols = columns.split(‘|’);
cols.forEach((c, i) => {
inputParams[c] = textValues[i];
});
newRecords.push(inputParams);
}
// 新数据数组通过数据模型「新增多条」方法批量新增
await context.callModel({
dataSourceName: ‘msdt_ekpfb61’, // 数据模型标识
methodName: ‘wedaBatchCreate’, // 新增多条的方法标识
params: {
records: newRecords,
},
});
return {
rows,
};
}
:::
在应用中使用自定义连接器
我们可以通过多种方法在应用中 使用自定义连接器,以下我们将以 模型应用 来做举例说明。
- 在模型应用中,我们选中表格组件,并在右侧的属性栏配置里找到顶部按钮配置,新增一个按钮,选择按钮动作为自定义:
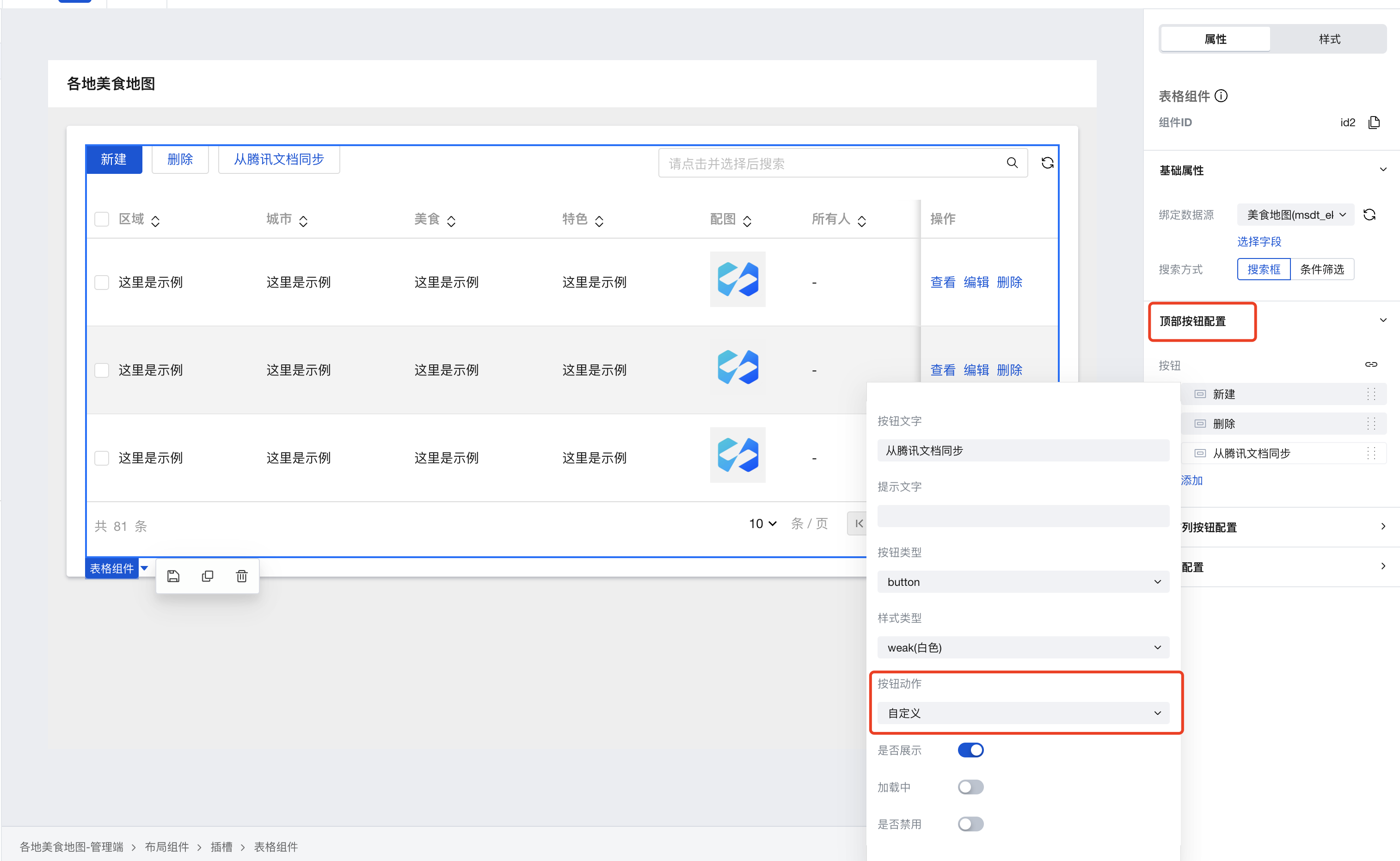
- 选择新增的按钮,并在右侧行为属性配置点击时行为:
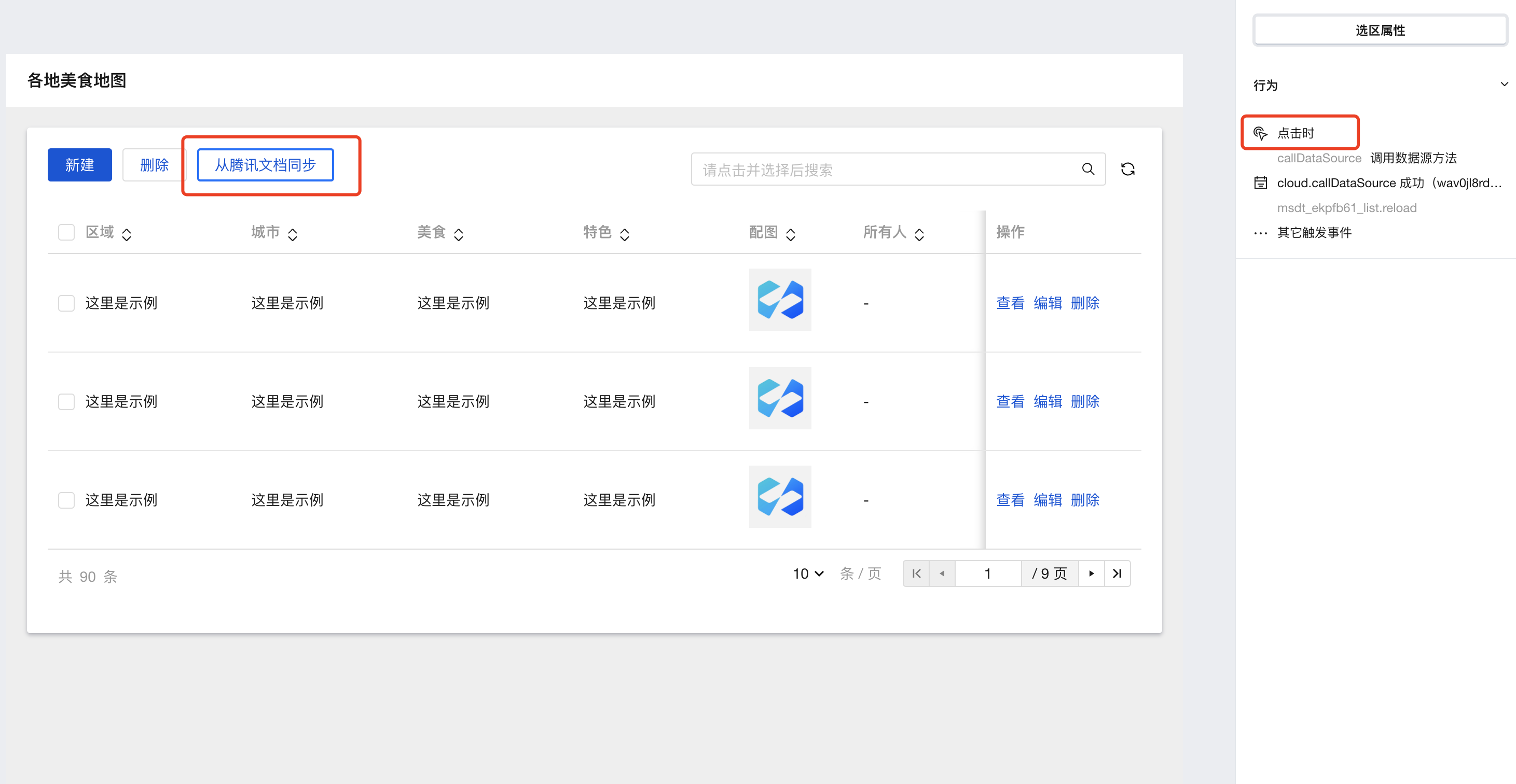
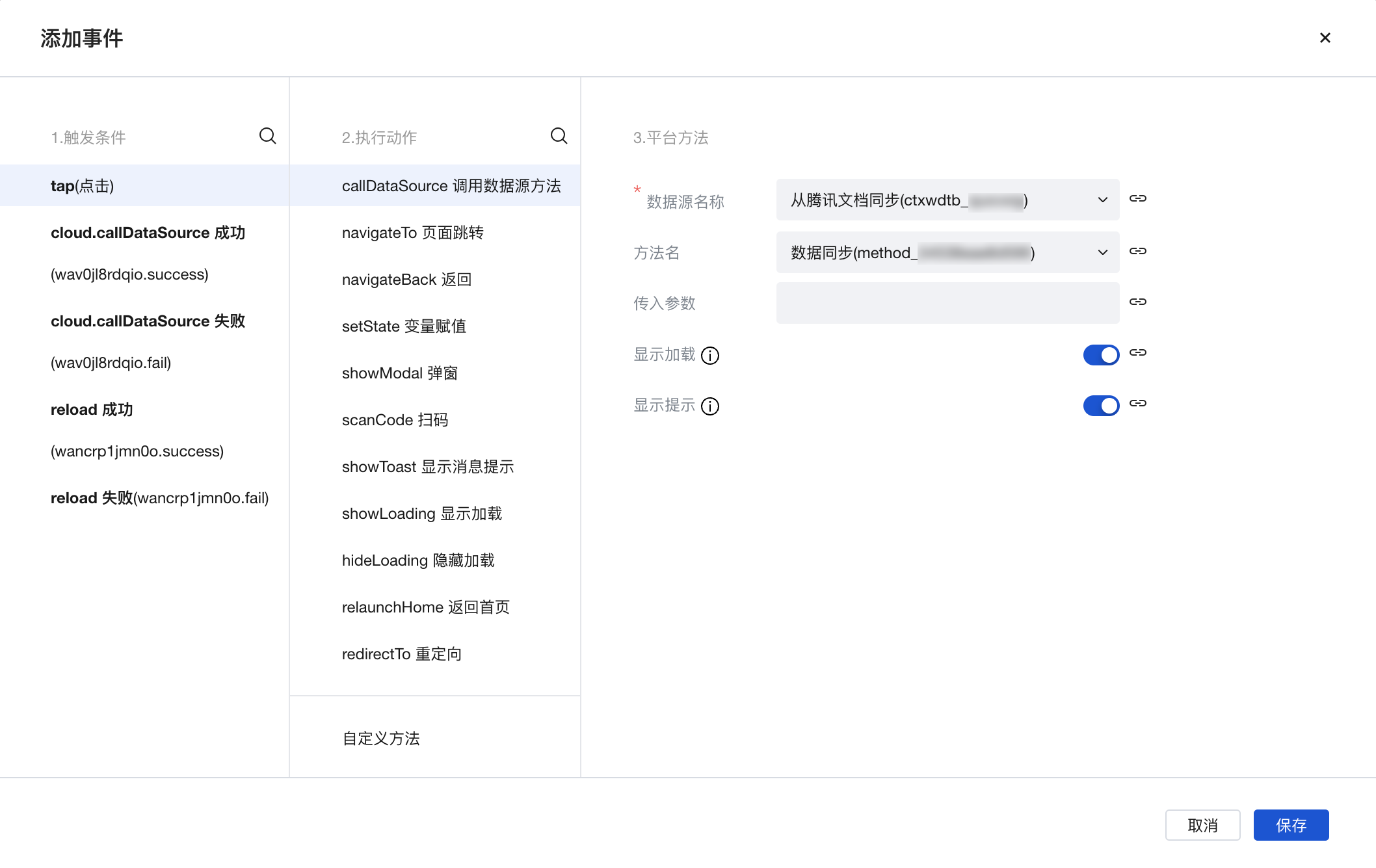
- 选择调用数据源方法并选择自定义连接器及其方法单击保存即可:

若有收获,就点个赞吧
0 人点赞
