tips: 可以使用单独的 \ 在命令行的末尾,使用换行的操作。
第一个简单的脚本
利用管道的特性,我们可以非常方便的设计我们脚本的功能。
比如,一个获取-提取-修改功能的脚本,借助于 grep 与 sed ,可以实现将文本文件中的ID 信息转换为URL 中对应的网页端ID 访问内容。
脚本的开头
在编写脚本之前,我们需要为脚本写一个组织行,shebang line,目的是告诉linux 使用何种shell或编程软件来编译这段内容。(当然一般操作系统的shell脚本都会默认读取 #!/bin/bash ,也就是说脚本中可以略去这段)
通过 #! + bash 绝对路径 ,完成shebang line 的编写。
ps:一般计算机(linux类型)编译软件都存在默认的路径下。
#!/bin/bash'''BASH'''#!/usr/bin/perl'''PERL'''
脚本的执行
当执行脚本时,需要使用 ./xxx.sh 的命令,而非 xxx.sh ,即告诉shell,需要在具体的某个(当前)目录下,执行shell 文件xxx。
脚本中的变量
可以参考
https://www.yuque.com/mugpeng/linux/pkntl1
引入外部参数
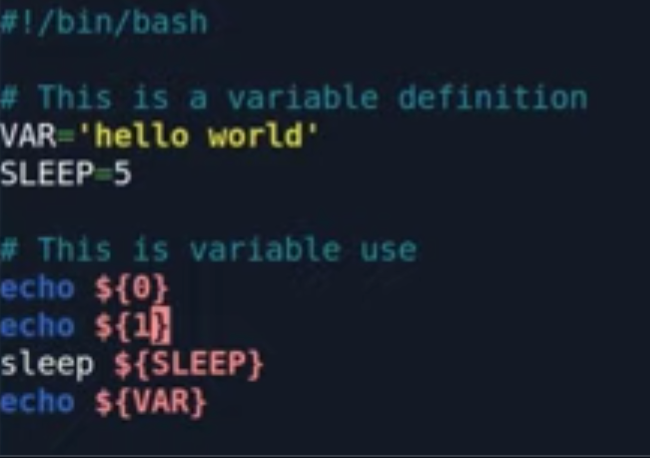
可以在脚本中通过数字,设置一个形参,接着可以通过外部参数,按照顺序传入脚本。
特殊字符变量
循环
如果学会其他编程语言,便可以轻松掌握bash 的循环脚本。
FOR 循环
需要注意的是,bash 通过占位符体现层级关系(注意空格!!),通过do 与done 包含循环的主语法,表示for循环开始与结束。
第一个简单循环脚本
比如一个编辑的ID 文本,包含了部分uniprot 中的蛋白编码。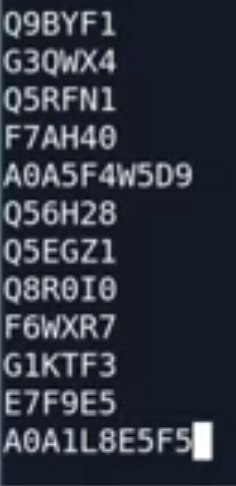
做一个小脚本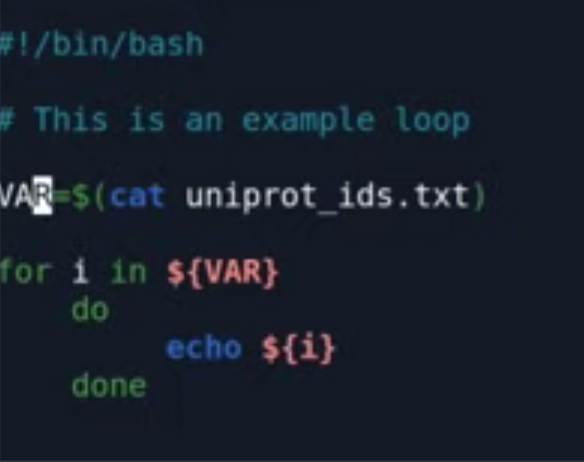
批量读取id信息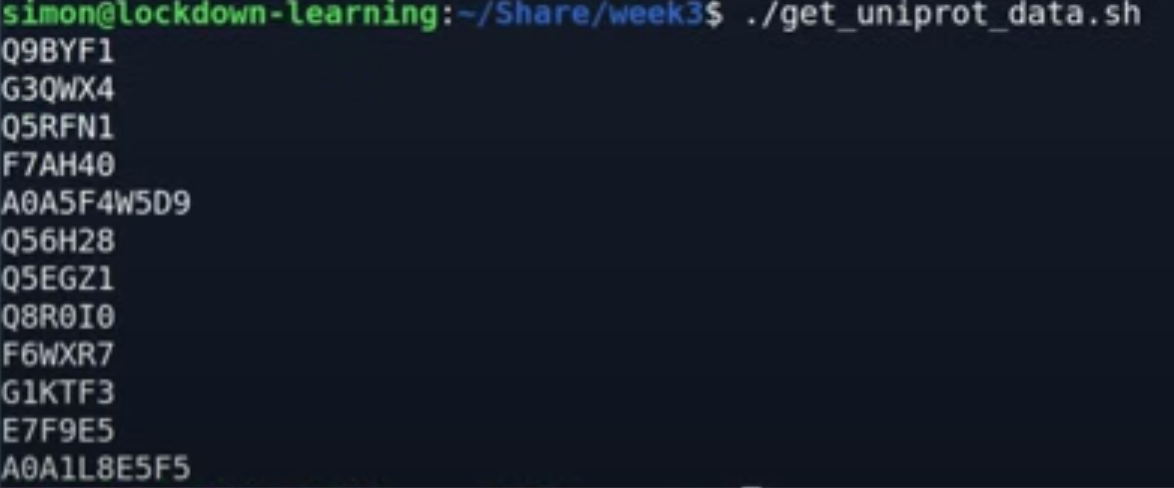
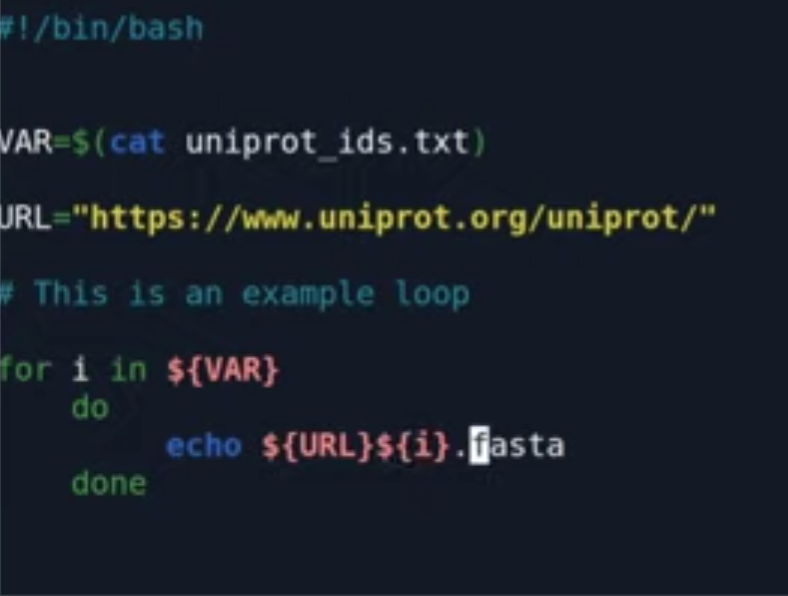
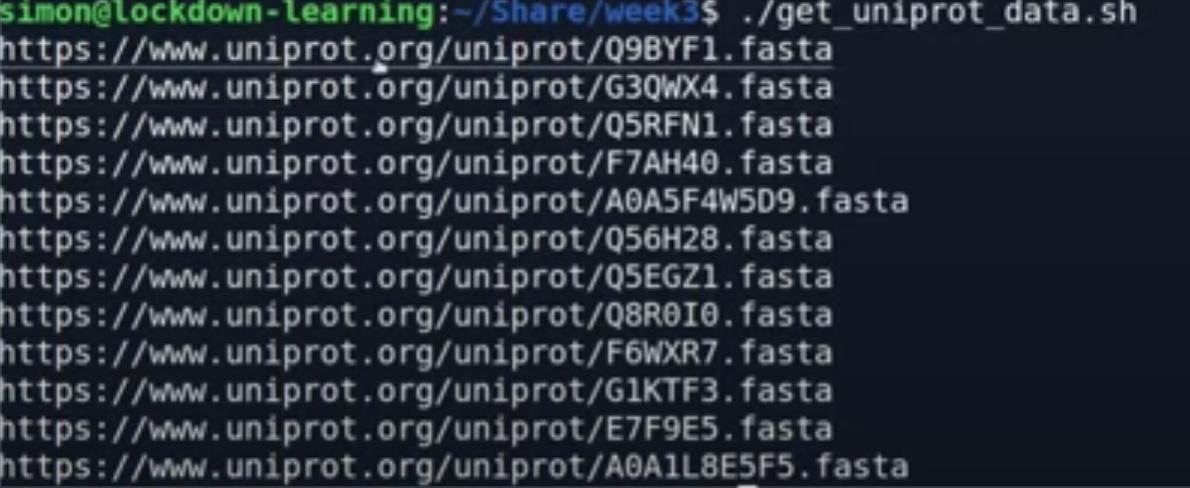
从uniprot 中批量下载序列
利用wget 便可轻松下载。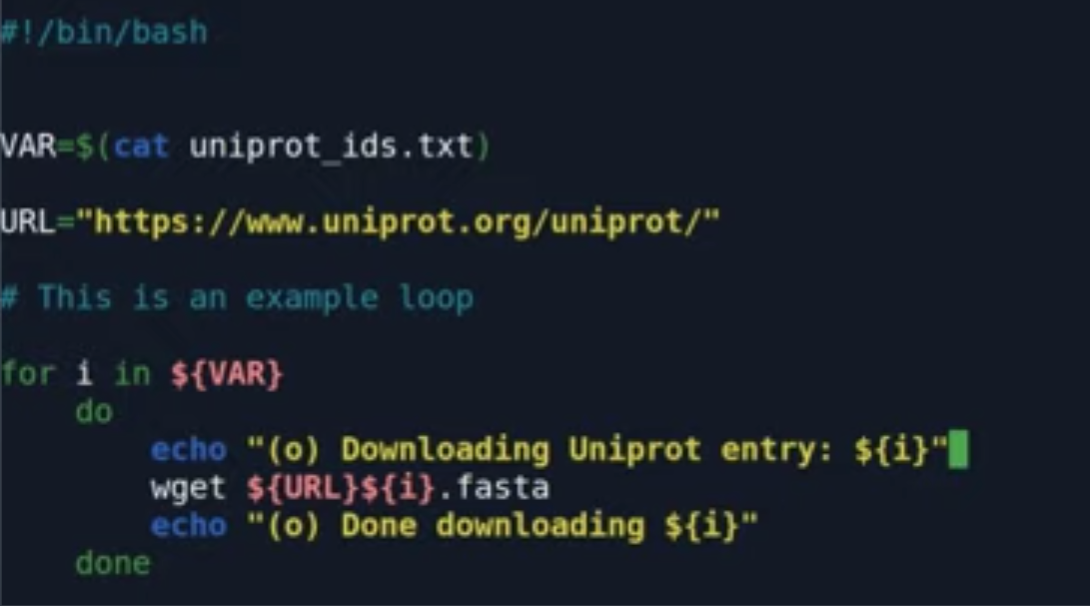
这时候如果用某个变量替代 uniprot_ids.txt ,便可以引入外部参数,实现反复调用该脚本下载不同的id数据。

若有收获,就点个赞吧
0 人点赞
