工作管理
每个终端只能管理当前终端中的job。
当进程在前台时,可以通过 ctrl + c 来终止它。
而也可以在命令的后面加上 & ,将其放入后台执行。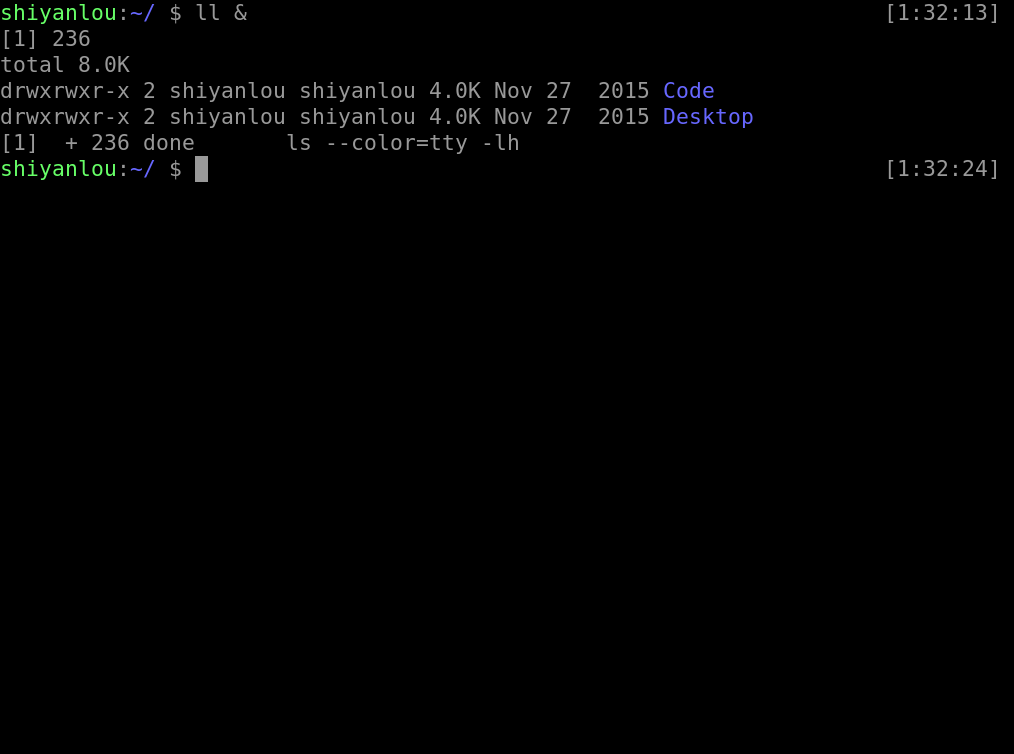
图中所显示的 [1] 236分别是该 job 的 job number 与该进程的 PID,而最后一行的 Done 表示该命令已经在后台执行完毕。
我们还可以通过 ctrl + z 使我们的当前工作停止并丢到后台中去。
查看后台工作
我们可以通过 jobs 查看。
其中需要注意有两个符号: + , - 。
其中第一列显示的为被放置后台 job 的编号,而第二列的 + 表示最近(刚刚、最后)被放置后台的 job,同时也表示预设的工作,也就是若是有什么针对后台 job 的操作,首先对预设的 job,- 表示倒数第二(也就是在预设之前的一个)被放置后台的工作,倒数第三个(再之前的)以后都不会有这样的符号修饰,第三列表示它们的状态,而最后一列表示该进程执行的命令。
转移后台工作
我们还以将后台的工作拿到前台来(输入的是jobs 号而非PID):
# 后面不加参数提取预设工作,加参数提取指定工作的编号# ubuntu 在 zsh 中需要 %,在 bash 中不需要 %fg [%jobnumber]
启动后台工作
当使用快捷键 ctrl + z 将前台工作停止放置在后台后,我们可以使用命令再让其继续在后台运行:
#与fg类似,加参则指定,不加参则取预设
bg [%jobnumber]
删除后台工作
# kill的使用格式如下
kill -signal %jobnumber
# signal从1-64个信号值可以选择,可以这样查看
kill -l
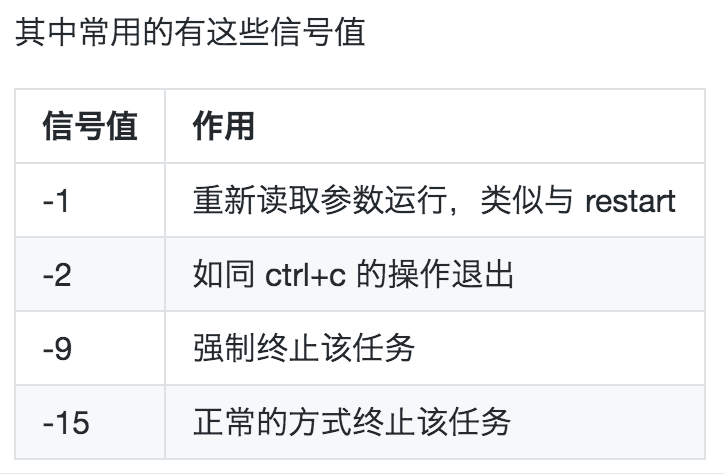
使用 kill -l 可以获取全部信号值信息:
进程管理工具
free
直接查看服务器内存使用情况:
$ free -h
total used free shared buff/cache available
Mem: 503Gi 75Gi 34Gi 4.0Mi 393Gi 424Gi
Swap: 2.0Gi 363Mi 1.6Gi
top
top 工具是我们常用的一个查看工具,能实时的查看我们系统的一些关键信息的变化(页面实际是动态变化的):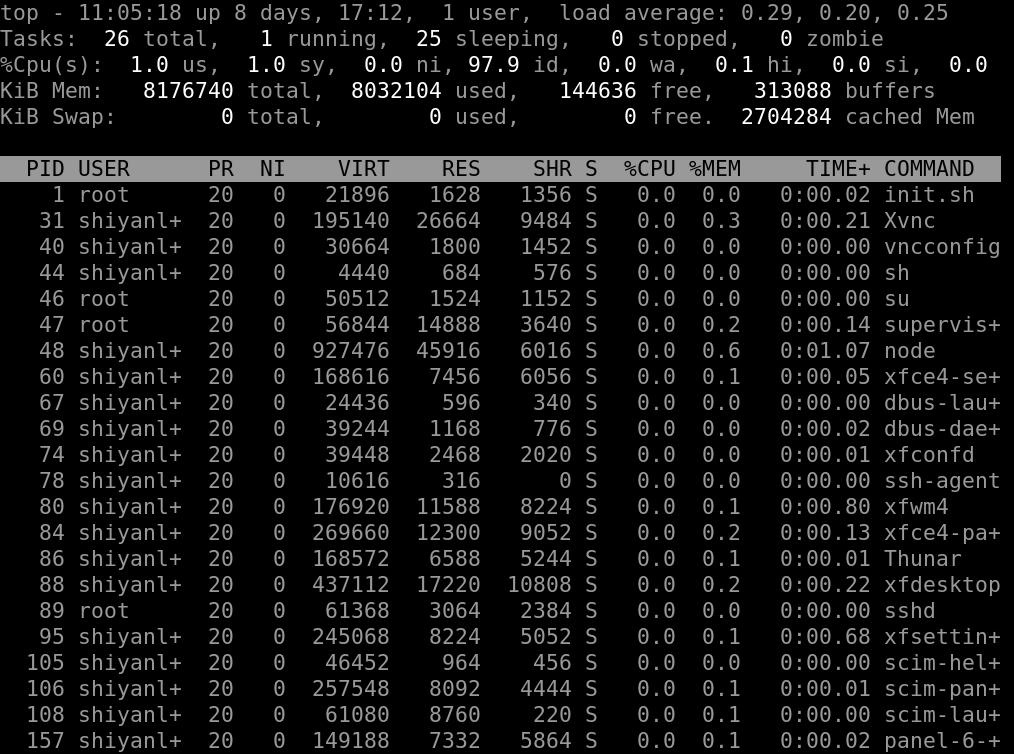
第一排信息
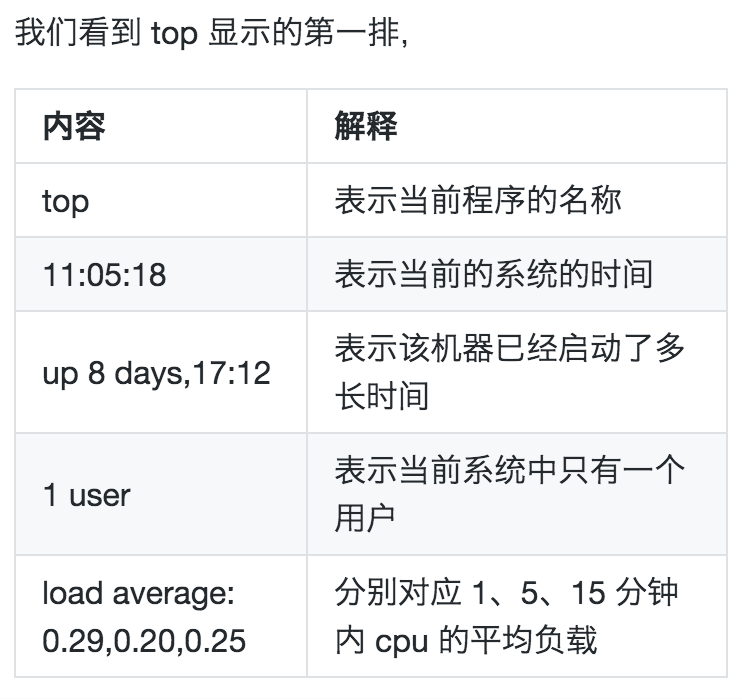
load average 在 wikipedia 中的解释是 the system load is a measure of the amount of work that a computer system is doing 也就是对当前 CPU 工作量的度量,具体来说也就是指运行队列的平均长度,也就是等待 CPU 的平均进程数相关的一个计算值。
load值
如何理解load average?
假设我们的系统是单 CPU、单内核的,把它比喻成是一条单向的桥,把 CPU 任务比作汽车。
那么可以作如下类比:
而实际中,由于现在的计算机发展,已经很少有单cpu 或单核进行任务了,我们需要将得到的这个值除以我们的核数来看。
一般也会将load 临界设定为 0.7 :
查看 busybox 的代码可以知道,数据是每 5 秒钟就检查一次活跃的进程数,然后计算出该值,然后 load 从 /proc/loadavg 中读取的。而这个 load 的值是如何计算的呢,这是 load 的计算的源码:
#define FSHIFT 11 /* nr of bits of precision */
#define FIXED_1 (1<<FSHIFT) /* 1.0 as fixed-point(定点) */
#define LOAD_FREQ (5*HZ) /* 5 sec intervals,每隔5秒计算一次平均负载值 */
#define CALC_LOAD(load, exp, n) \
load *= exp; \
load += n*(FIXED_1 - exp); \
load >>= FSHIFT;
unsigned long avenrun[3];
EXPORT_SYMBOL(avenrun);
/*
* calc_load - given tick count, update the avenrun load estimates.
* This is called while holding a write_lock on xtime_lock.
*/
static inline void calc_load(unsigned long ticks)
{
unsigned long active_tasks; /* fixed-point */
static int count = LOAD_FREQ;
count -= ticks;
if (count < 0) {
count += LOAD_FREQ;
active_tasks = count_active_tasks();
CALC_LOAD(avenrun[0], EXP_1, active_tasks);
CALC_LOAD(avenrun[1], EXP_5, active_tasks);
CALC_LOAD(avenrun[2], EXP_15, active_tasks);
}
}
cpu信息查看
#查看物理 CPU 的个数
cat /proc/cpuinfo | grep "physical id" | sort | uniq |wc -l
#每个 cpu 的核心数
cat /proc/cpuinfo | grep "physical id" | grep "0" | wc -l
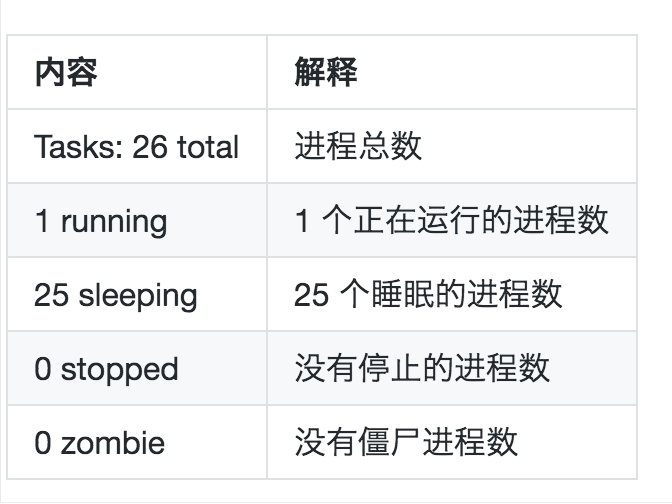
第二排信息
第三排信息
主要是cpu使用情况的统计: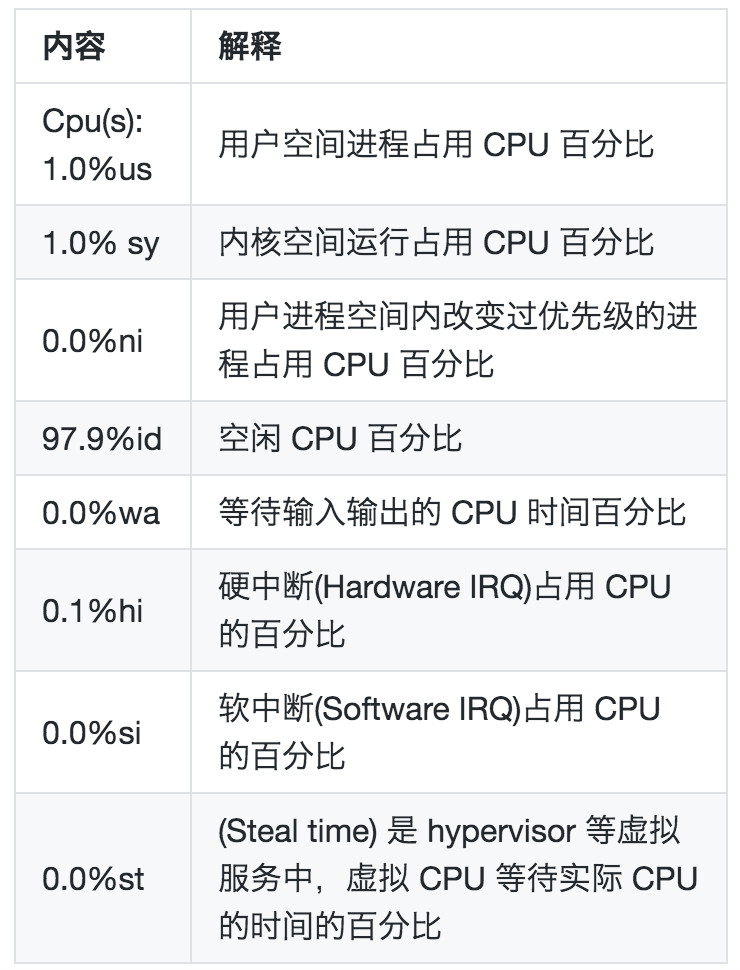
需要注意的是,CPU利用率不同于之前的load average。
CPU 利用率是对一个时间段内 CPU 使用状况的统计,通过这个指标可以看出在某一个时间段内 CPU 被占用的情况,而 Load Average 是 CPU 的 Load,它所包含的信息不是 CPU 的使用率状况,而是在一段时间内 CPU 正在处理以及等待 CPU 处理的进程数情况统计信息,这两个指标并不一样。
第四行信息
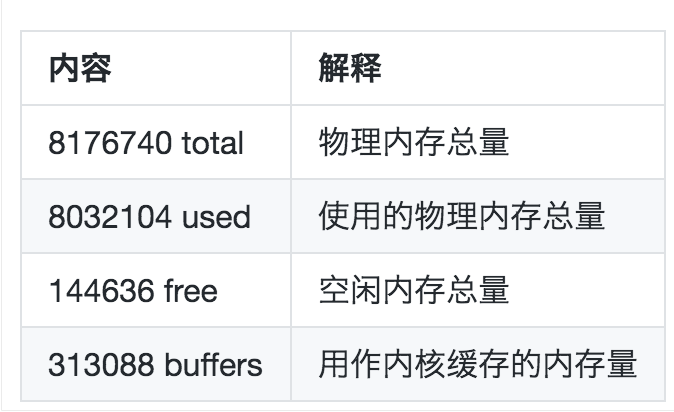
主要是内存的使用情况。
系统中可用的物理内存最大值并不是 free 这个单一的值,而是 free + buffers + swap 中的 cached 的和。
第五行信息

进程信息
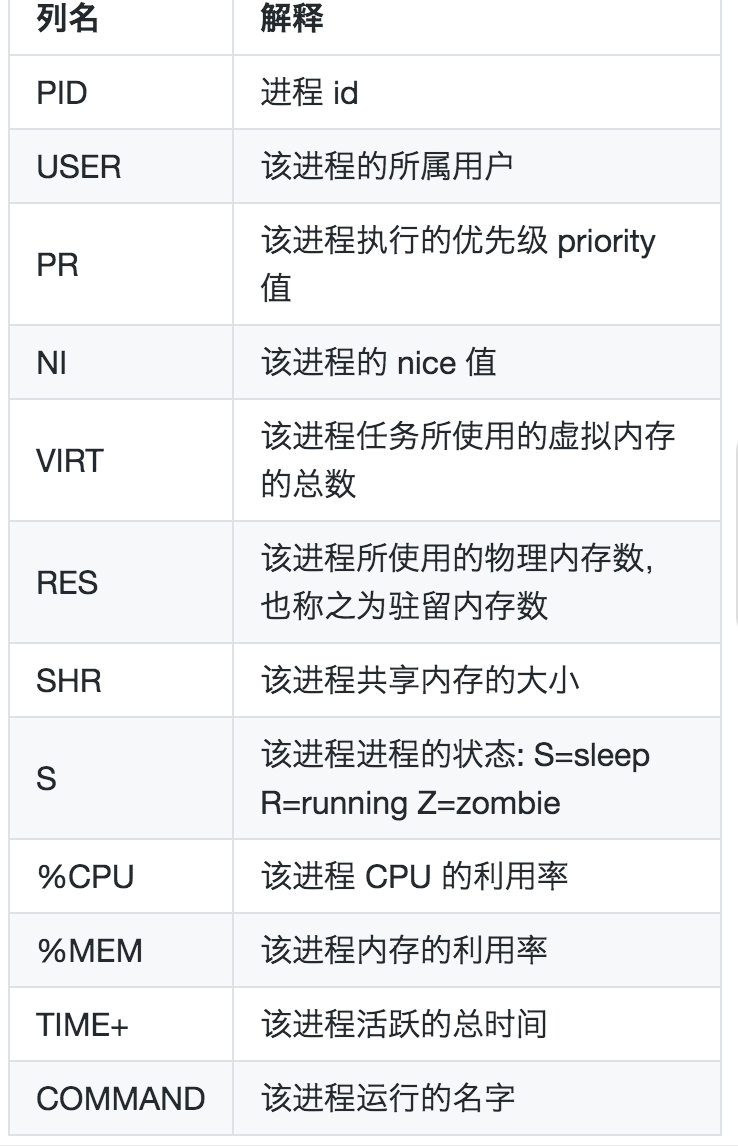
其中:
NICE 值叫做静态优先级,是用户空间的一个优先级值,其取值范围是-20 至 19。这个值越小,表示进程”优先级”越高,而值越大“优先级”越低。nice 值中的 -20 到 19,中 -20 优先级最高, 0 是默认的值,而 19 优先级最低。
PR 值表示 Priority 值叫动态优先级,是进程在内核中实际的优先级值,进程优先级的取值范围是通过一个宏定义的,这个宏的名称是 MAX_PRIO,它的值为 140。Linux 实际上实现了 140 个优先级范围,取值范围是从 0-139,这个值越小,优先级越高。而这其中的 0-99 是实时进程的值,而 100-139 是给用户的。
其中 PR 中的 100 to 139 值部分有这么一个对应 PR = 20 + (-20 to +19),这里的 -20 to +19 便是 nice 值,所以说两个虽然都是优先级,而且有千丝万缕的关系,但是他们的值,他们的作用范围并不相同。
VIRT 任务所使用的虚拟内存的总数,其中包含所有的代码,数据,共享库和被换出 swap 空间的页面等所占据空间的总数。
交互命令
ps
不同于top,ps 是一个静态查看进程信息的工具。
进程信息解释
| 内容 | 解释 |
|---|---|
| F | 进程的标志(process flags),当 flags 值为 1 则表示此子程序只是 fork 但没有执行 exec,为 4 表示此程序使用超级管理员 root 权限 |
| USER | 进程的拥有用户 |
| PID | 进程的 ID |
| PPID | 其父进程的 PID |
| SID | session 的 ID |
| TPGID | 前台进程组的 ID |
| %CPU | 进程占用的 CPU 百分比 |
| %MEM | 占用内存的百分比 |
| NI | 进程的 NICE 值 |
| VSZ | 进程使用虚拟内存大小 |
| RSS | 驻留内存中页的大小 |
| TTY | 终端 ID |
| S or STAT | 进程状态 |
| WCHAN | 正在等待的进程资源 |
| START | 启动进程的时间 |
| TIME | 进程消耗 CPU 的时间 |
| COMMAND | 命令的名称和参数 |
**
TPGID栏写着-1 的都是没有控制终端的进程,也就是守护进程。
STAT表示进程的状态,而进程的状态有很多,如下表所示:
| 状态 | 解释 |
|---|---|
| R | Running.运行中 |
| S | Interruptible Sleep.等待调用 |
| D | Uninterruptible Sleep.不可中断睡眠 |
| T | Stoped.暂停或者跟踪状态 |
| X | Dead.即将被撤销 |
| Z | Zombie.僵尸进程 |
| W | Paging.内存交换 |
| N | 优先级低的进程 |
| < | 优先级高的进程 |
| s | 进程的领导者 |
| L | 锁定状态 |
| l | 多线程状态 |
| + | 前台进程 |
其中的 D 是不能被中断睡眠的状态,处在这种状态的进程不接受外来的任何 signal,所以无法使用 kill 命令杀掉处于 D 状态的进程,无论是
kill,kill -9还是kill -15,一般处于这种状态可能是进程 I/O 的时候出问题了。
常用选项
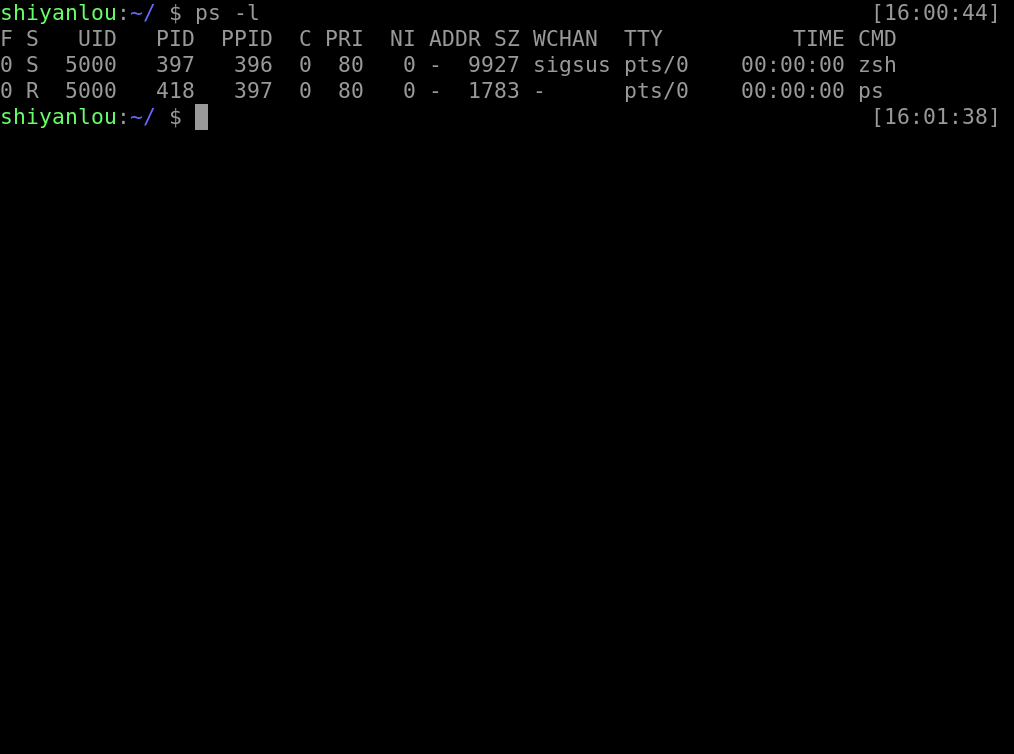
l 参数可以显示自己这次登录的 bash 相关的进程信息罗列出来。
ps -l
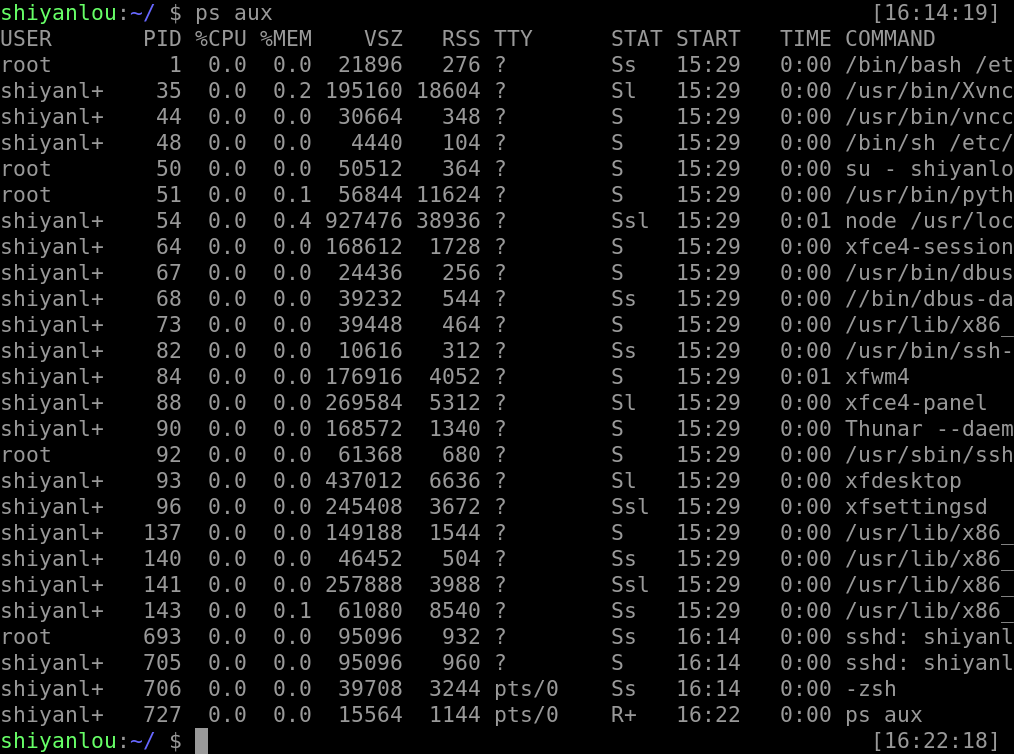
还可以罗列所有进程的信息:
ps aux
通过结合grep 可以精确查找某个使用中的进程信息: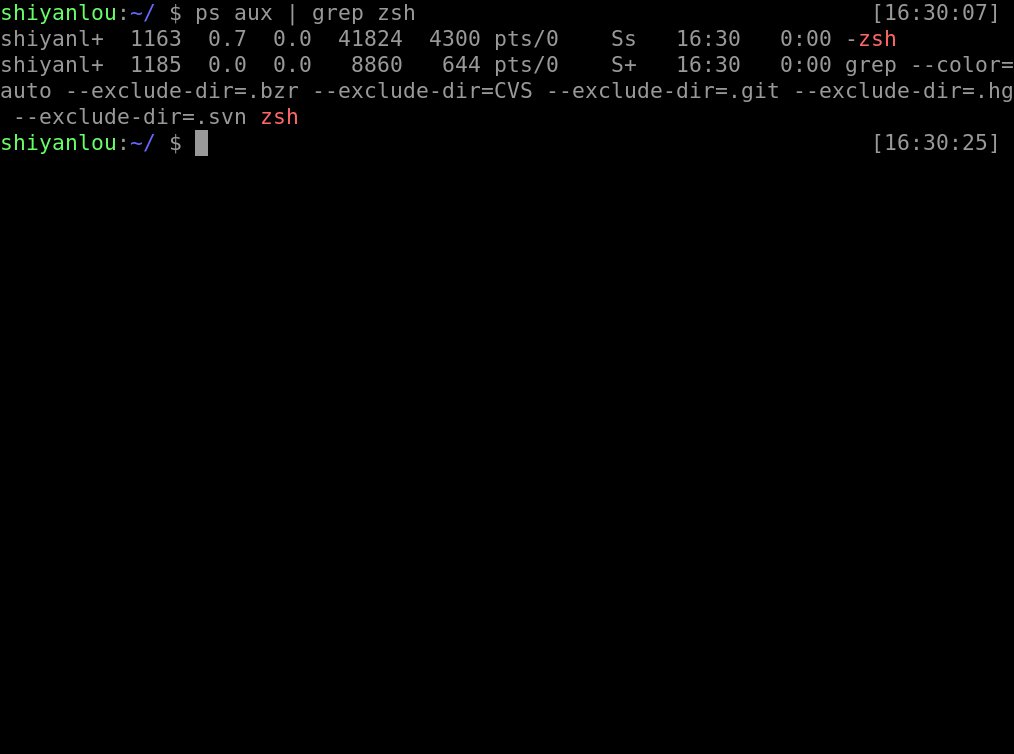
还可以树状显示进程信息:
ps axjf
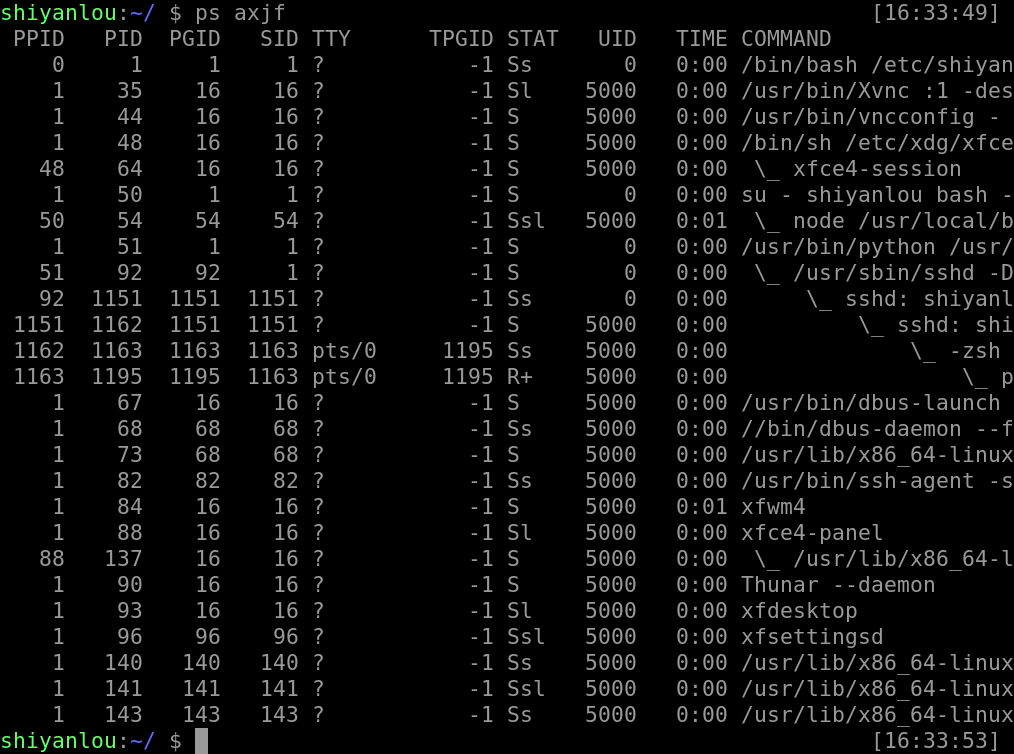
以及指定所需要显示的信息:
ps -afxo user,ppid,pid,pgid,command
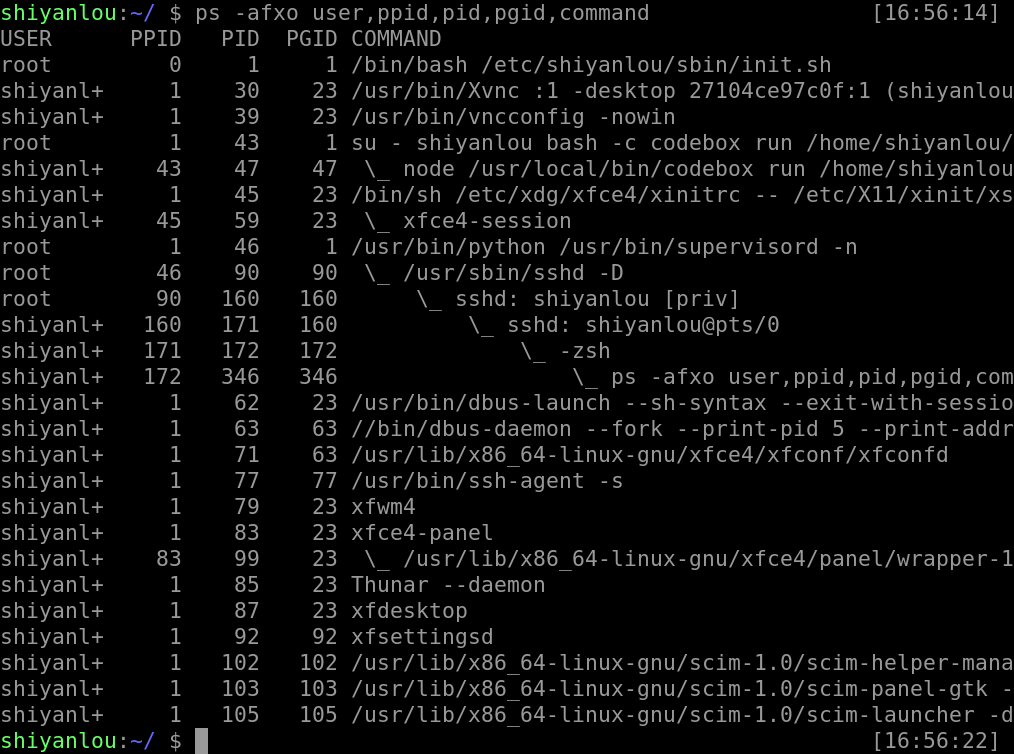
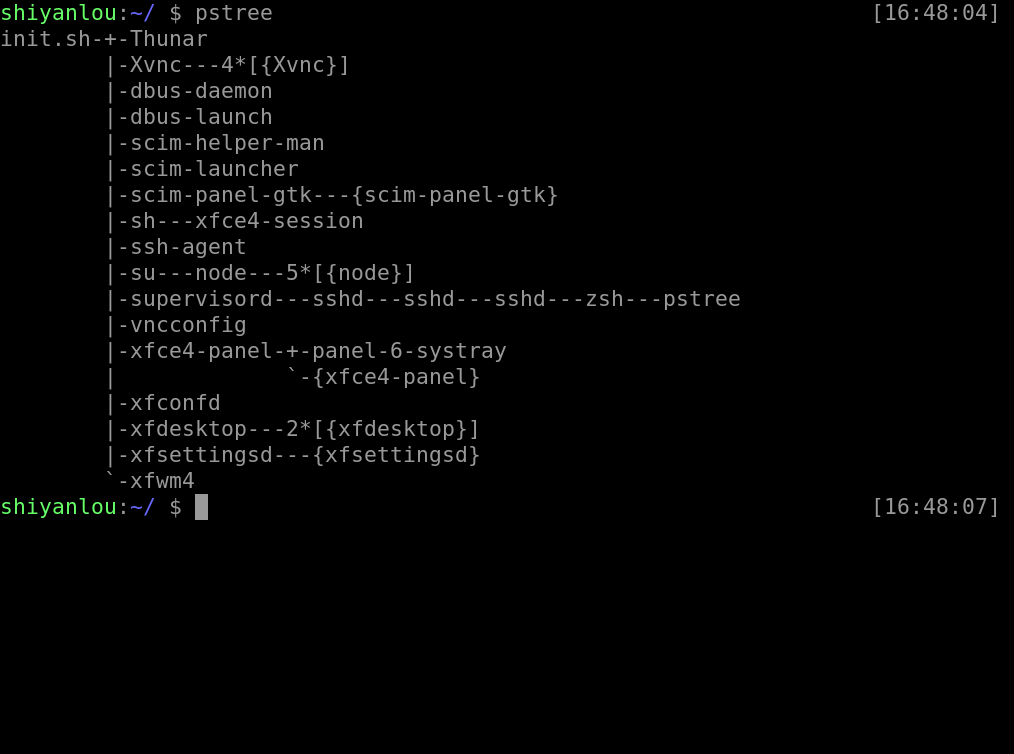
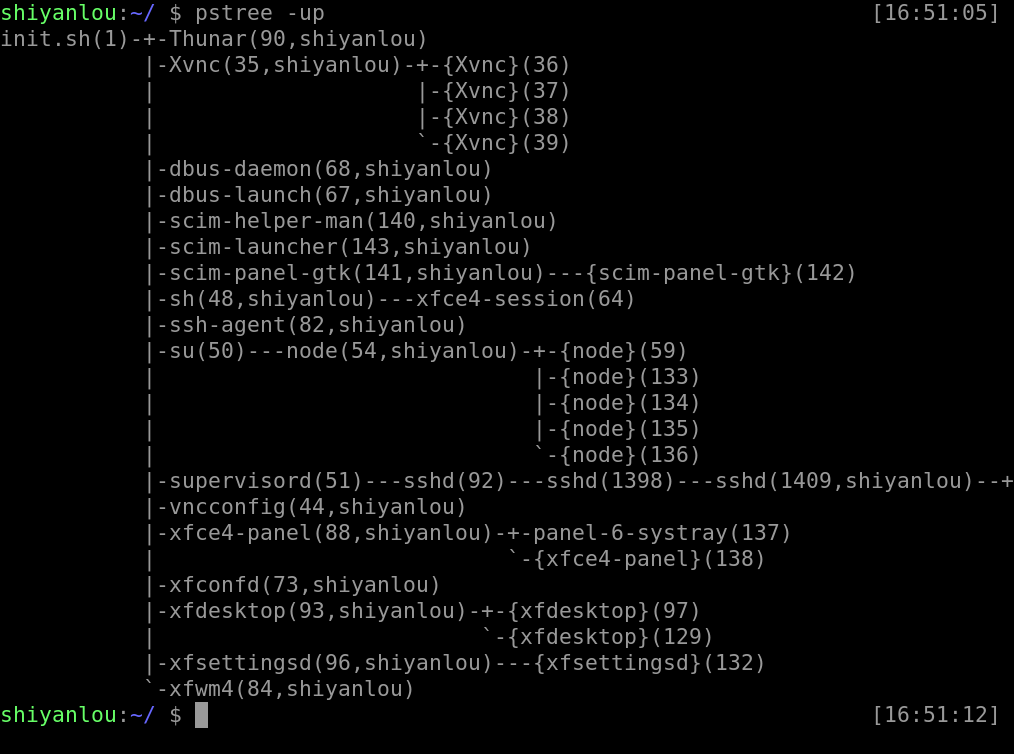
pstree
通过 pstree 可以很直接的看到相同的进程数量,最主要的还是我们可以看到所有进程之间的相关性。
常用参数

kill
除了之前说的通过 %n 结束一些job 进程,kill 也可以直接对PID 下手:
# 首先我们使用图形界面打开了 gedit、gvim,用 ps 可以查看到
ps aux
# 使用 9 这个信号强制结束 gedit 进程
kill -9 1608
# 我们再查找这个进程的时候就找不到了
ps aux | grep gedit
修改执行顺序
计算机靠该进程的优先级值来判定进程调度的优先级,而优先级的值就是通过 PR 与 nice 来控制与体现。
而 nice 的值我们是可以通过 nice 命令来修改的,而需要注意的是 nice 值可以调整的范围是 -20 ~ 19,其中 root 有着至高无上的权力,既可以调整自己的进程也可以调整其他用户的程序,并且是所有的值都可以用,而普通用户只可以调制属于自己的进程,并且其使用的范围只能是 0 ~ 19,因为系统为了避免一般用户抢占系统资源而设置的一个限制。
# 这个实验在环境中无法做,因为权限不够,可以自己在本地尝试
# 打开一个程序放在后台,或者用图形界面打开
nice -n -5 vim &
# 用 ps 查看其优先级
ps -afxo user,ppid,pid,stat,pri,ni,time,command | grep vim
还可以通过 renice 重新设定任务优先级:
renice -5 pid

若有收获,就点个赞吧
0 人点赞
