grep
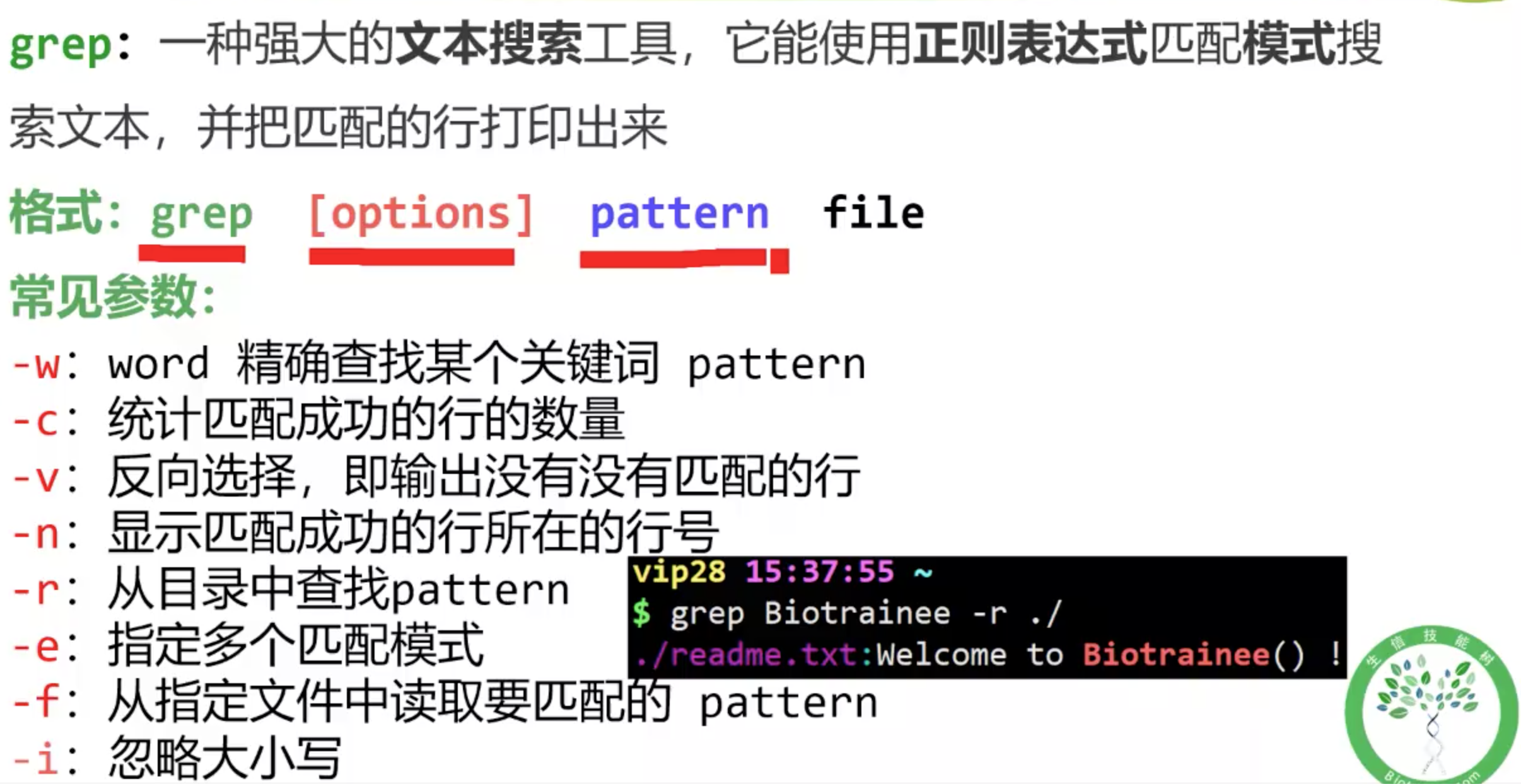
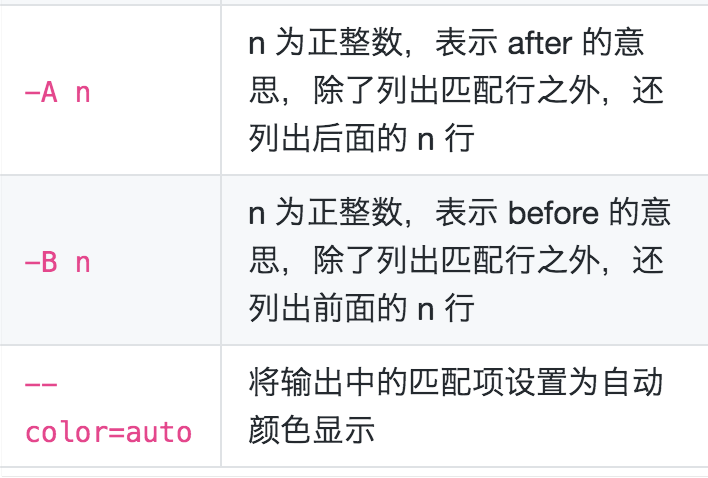
其中-f 参数非常方便,可以在需要指定多个匹配模式时总是使用-e 选项。
正则表达式

需要强调的是,正则表达式的字符范围包括大小写字母,罗马数字,以及部分符号。. 表示任何单个字符(换行符外)[] 对单个字符给出取值范围;[abc]表示a或b或c,[a-f]表a-f中的任意一个字符串。[^ ],与[]相反,指取值范围以外字符;[^abc]表示非a非b非c。*,前一个字符0或无限延伸;abc*表示,ab,abc,abcc...+,前一个字符1或无限延伸;abc+表示,abc,abcc,abccc...?,前一个字符0或1次延伸;abc?表示,ab,abc。|,左右表达式任意一个;ab|cd表示,ab或cd。{m},扩展前一个字符串m次;ab{2}c,表示abbc。{m,n},扩展前一个字符串m 到n次;ab{1,2}c,表示abc,abbc。^,表示字符串开头部分;^abc,匹配abc 开头的字符串。$,匹配字符串结尾;abc$,匹配abc 结尾的字符串。(),分组标记,内部只可以用|;(abc)表示abc,(abc|def)表示abc, def。\d 数字,等价于[0-9]\D 非数字。\w 单词字符,等价于[A-Z], [a-z], [0-9] 及 -。\W 非单词字符。\t 制表符。\n 空行。\s 空格型内容,如\t, \n等。\S 非空格。
此外,对于大部分的标志使用时都需要使用 \ 进行转义,以作为正则表达式的通配符。比如
{}, +, ?
正则表达式引擎
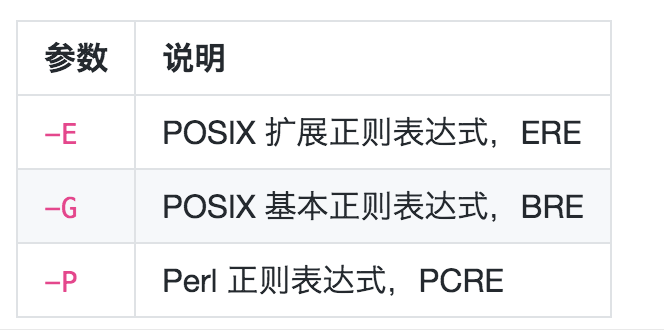
特殊符号
| 特殊符号 | 说明 |
|---|---|
[:alnum:] |
代表英文大小写字母及数字,亦即 0-9, A-Z, a-z |
[:alpha:] |
代表任何英文大小写字母,亦即 A-Z, a-z |
[:blank:] |
代表空白键与 [Tab] 按键两者 |
[:cntrl:] |
代表键盘上面的控制按键,亦即包括 CR, LF, Tab, Del.. 等等 |
[:digit:] |
代表数字而已,亦即 0-9 |
[:graph:] |
除了空白字节 (空白键与 [Tab] 按键) 外的其他所有按键 |
[:lower:] |
代表小写字母,亦即 a-z |
[:print:] |
代表任何可以被列印出来的字符 |
[:punct:] |
代表标点符号 (punctuation symbol),亦即:” ‘ ? ! ; : # $… |
[:upper:] |
代表大写字母,亦即 A-Z |
[:space:] |
任何会产生空白的字符,包括空白键, [Tab], CR 等等 |
[:xdigit:] |
代表 16 进位的数字类型,因此包括: 0-9, A-F, a-f 的数字与字节 |
示例
# grep默认是区分大小写的,这里将匹配所有的小写字母
$ echo '1234\nabcd' | grep '[a-z]'
# 将匹配所有的数字
$ echo '1234\nabcd' | grep '[0-9]'
# 将匹配所有的数字
$ echo '1234\nabcd' | grep '[[:digit:]]'
# 将匹配所有的小写字母
$ echo '1234\nabcd' | grep '[[:lower:]]'
# 将匹配所有的大写字母
$ echo '1234\nabcd' | grep '[[:upper:]]'
# 将匹配所有的字母和数字,包括0-9,a-z,A-Z
$ echo '1234\nabcd' | grep '[[:alnum:]]'
# 将匹配所有的字母
$ echo '1234\nabcd' | grep '[[:alpha:]]'
sed

sed 自身就是一门编程语言,可以对文本进行强大的修改(增删改查)。

script 有专门的相关的语句模式。

相关命令如上。
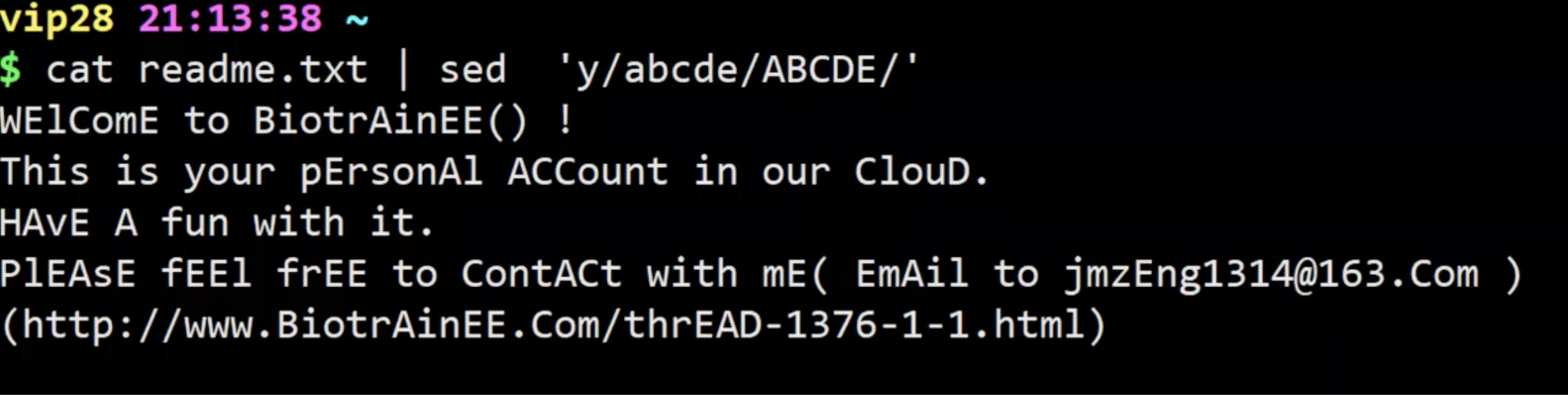
需要注意的是,y 命令是一一转换,因此指定的字符需要长度相等。
示例
sed 的script 内容用引号选中,
$ cat readme.txt | sed '1a Welcome to Biotrainee() !'
Welcome to Biotrainee() !
Welcome to Biotrainee() !
This is your personal account in our Cloud.
Have a fun with it.
Please feel free to contact with me( email to jmzeng1314@163.com )
(http://www.biotrainee.com/thread-1376-1-1.html)
进阶
删除空白行
$ sed '/^$/d' readme.txt
Welcome to Biotrainee() !
This is your personal account in our Cloud.
Have a fun with it.
Please feel free to contact with me( email to jmzeng1314@163.com )
(http://www.biotrainee.com/thread-1376-1-1.html)
替换
后面的flag 表示匹配到的行的第几处,默认只替换第一处,使用 g 可以设定替换所有处。
这里养成习惯,使用替换时先输入 s/// 。
$ cat readme.txt | sed 's/is/IS/g'
Welcome to Biotrainee() !
ThIS IS your personal account in our Cloud.
Have a fun with it.
Please feel free to contact with me( email to jmzeng1314@163.com )
(http://www.biotrainee.com/thread-1376-1-1.html)
匹配打印
一般是-n 参数与 script 中的p 结合。
类似grep 的功能。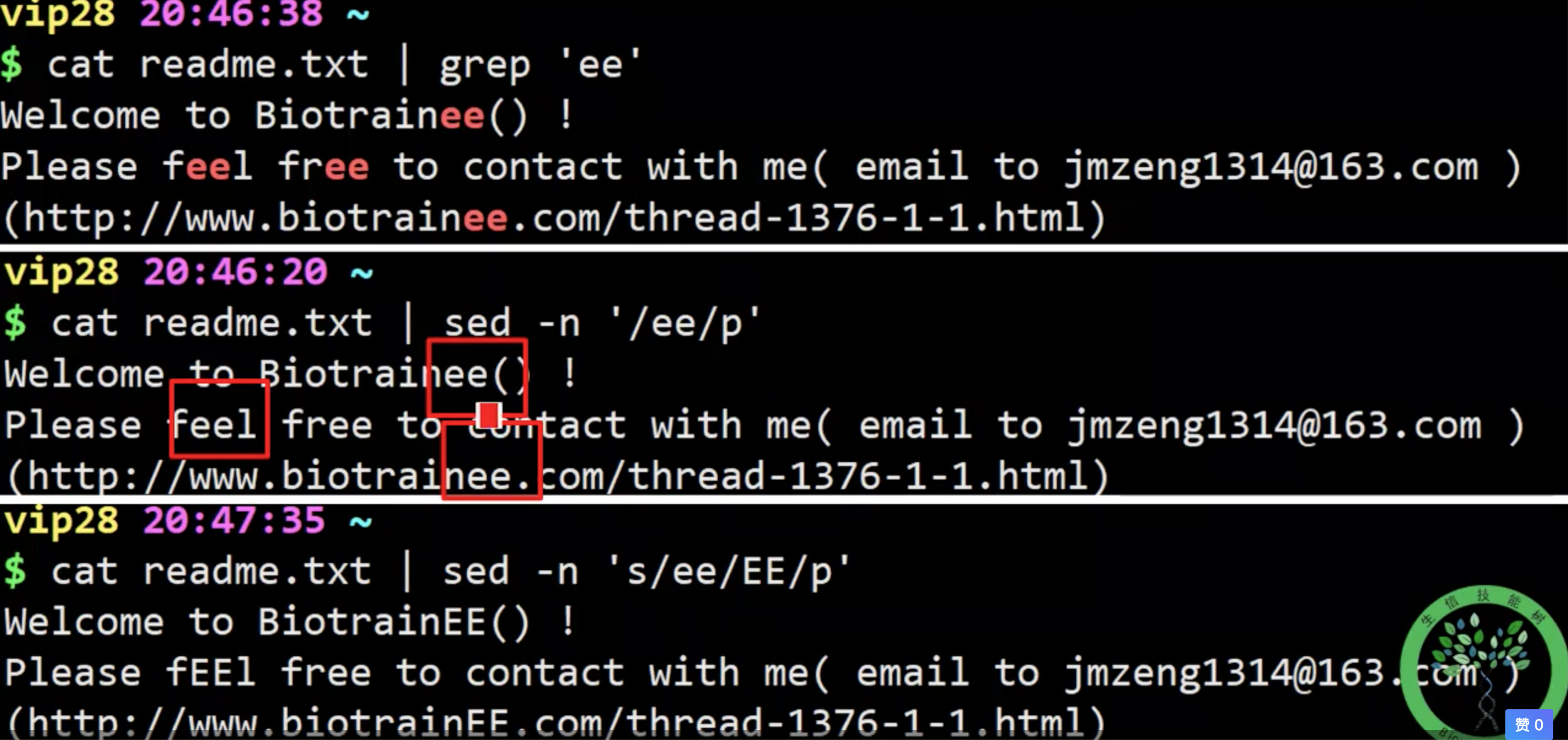
转换
awk
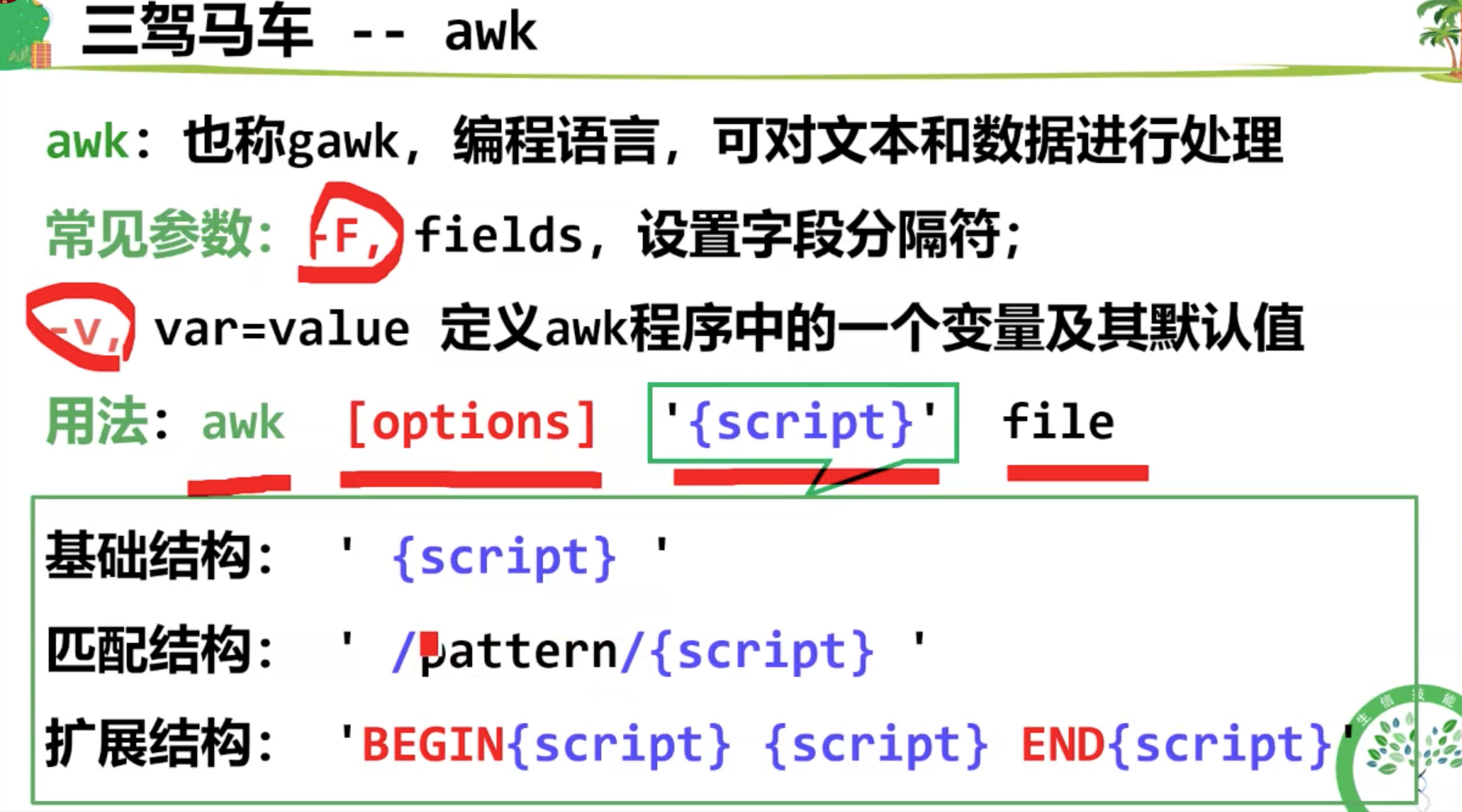
awk 在读取文本时,会将预定义的 字段分隔符 划分给每个数据字段,并分配一个变量。awk 默认的字段分隔符为任意空白字符(空格或制表符),可以用 -F 参数定义字段分隔符。
$0 代表整个文本行
$1 代表文本中第一个数据字段
...
$NF 代表文本行中的最后一个数据字段
需要注意的是⚠️:当awk 的外部使用双引号时,内部需要使用单引号,以进行区分。一般来说是外单内双。
我们可以利用cat 的函数将内容传递给 awk ,再使用变量$0读取整段内容,或者直接 awk '{print}' xxx.test 。
匹配结构
cat example.gtf | awk -F '\t' '/UTR/ {print $1}' | less -NS
通过以上代码,可以获得以制表符分隔字符串,匹配到UTR 字符的行的第一列信息。
拓展结构
会在中间的 /UTR/ {print $1} 匹配的段落前后,加上需要使用BEGIN 与END 后面的语句。begin 与end 相当于是对awk 的处理进行了先后设定,只有对BEGIN 中的语法对整个文件处理完成后,才会进行下一步。
$ head example.gtf | awk -F '\t' 'BEGIN{print "find UTR"} /UTR/ {print $1} END{print "finished"}'
find UTR
chr1
chr1
finished
awk 内置变量

相当于对于 0-9 数字变量的补充。
FS
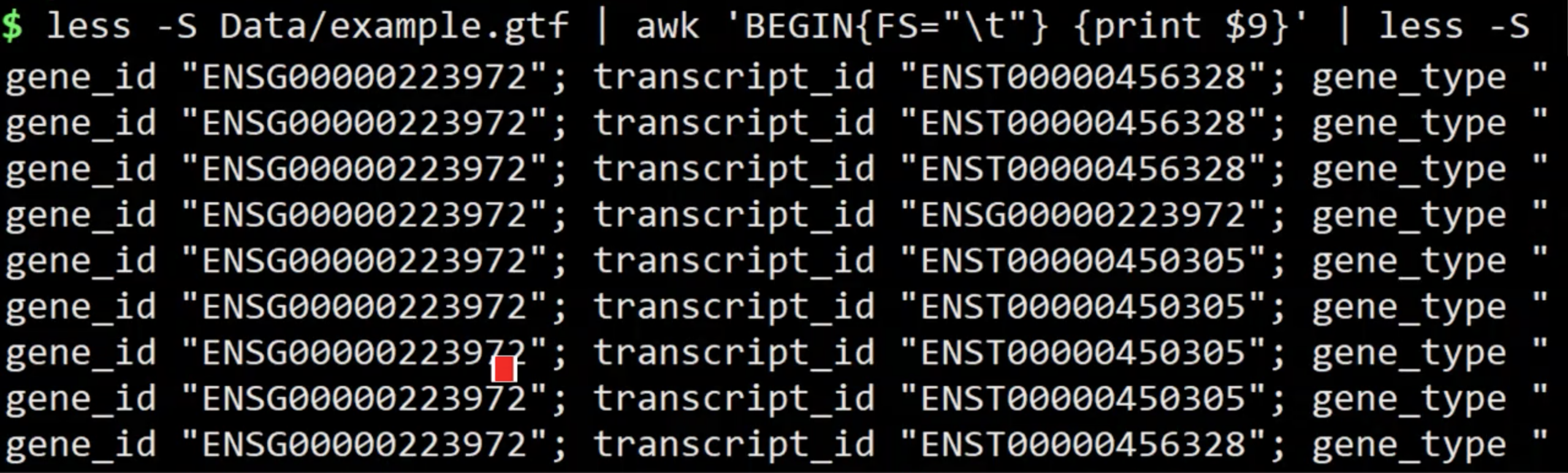
可以达到类似awk 参数-F 的效果。
NR

可以打印出行号。需要注意的是,它和 less -N 还是存在区别, NR 打印出来的行号为对应行在整个文件中的原行数,因此它不像前者那样会直接按照顺序列出。(其实内容是一样的,只是记录数字不一样罢了)
- NR
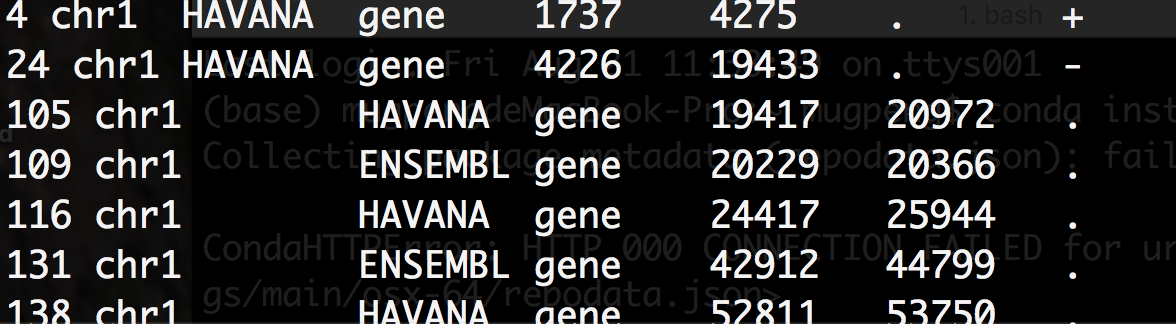
- less -N
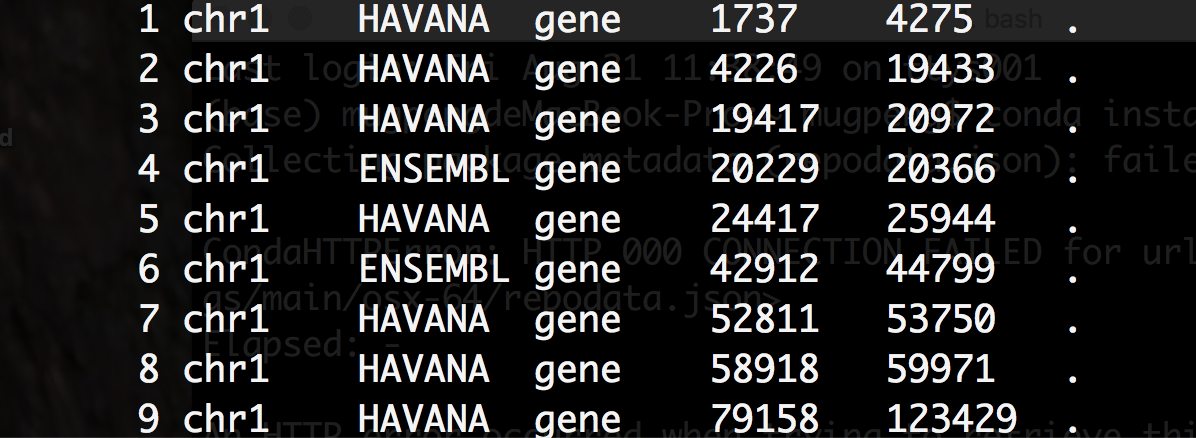
OFS
可以改变输出的字段分隔符。比如本身输出应该是空格,通过设置 OFS 可以修改为制表符。
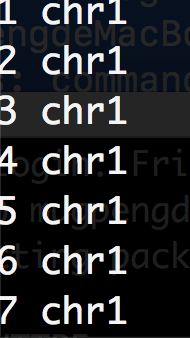
$ cat example.gtf | awk 'BEGIN{FS="\t"} {print NR,$1} END{print "finished"}' | less -S
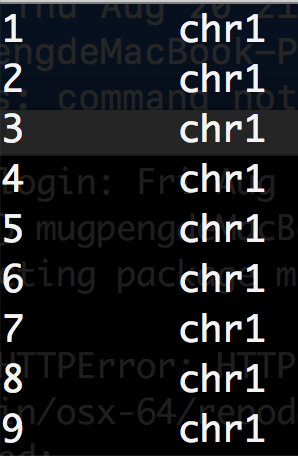
$ cat example.gtf | awk 'BEGIN{FS="\t";OFS="\t"} {print NR,$1} END{print "finished"}' | less -S
awk 条件与循环
if
awk '{if (condition) {yes} else {no}}' 。
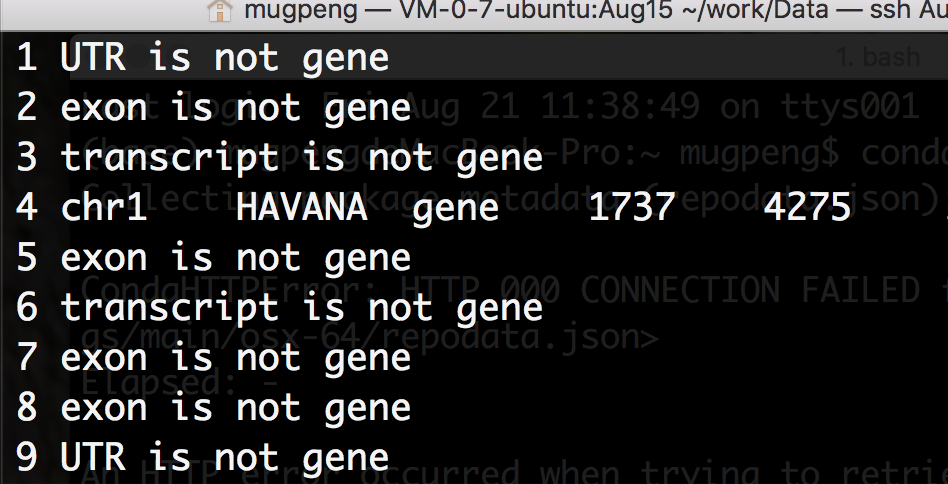
$ cat example.gtf | awk '{if($3=="gene") {print $0} else {print $3 " is not gene"}}' | less -NS
for
awk '{for (condition) {statement} }' 。
如果想要将因为for 循环输出的每行的 $1-$3 信息放在同一行,可以使用
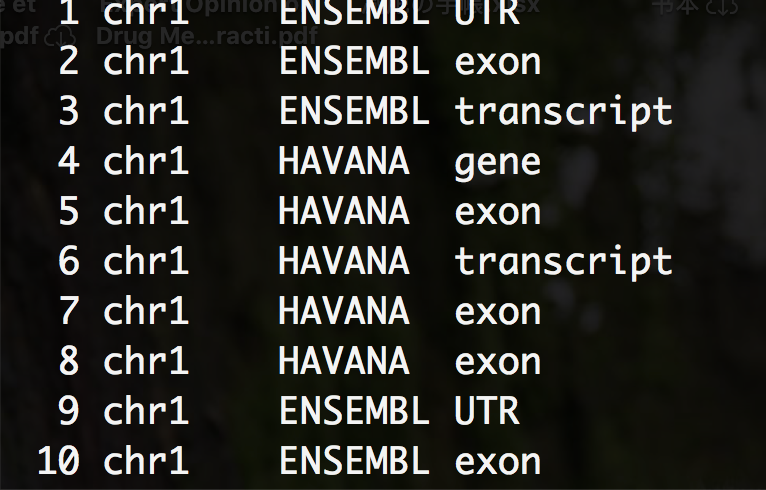
$ cat example.gtf | awk '{for(i=1;i<4;i++) {print $i}}' | less -NS | paste - - -
另外,原来for 循环打印结果,是由于print 会默认打印完内容后打印一个换行符。 也可以通过改变print 的打印方式,来结合awk 语法(ORS)进行修改。
awk 的数学运算

比如需要对外显子的这两列进行计算。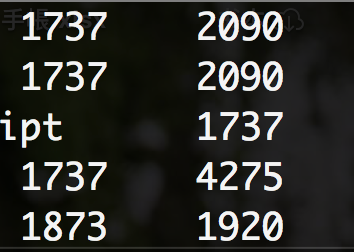
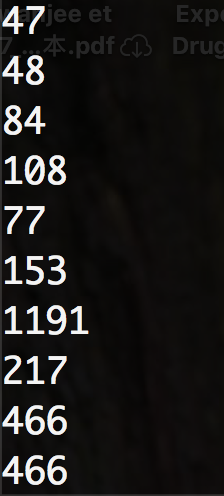
$ cat example.gtf | awk '/exon/ {print $5-$4}' | less -S
练习
练习1

练习2

练习3

练习4

$ head example.gtf | awk 'BEGIN{FS="\t"} {print $9}' | awk '{print $2,$4,$6}' | tr ';' ' ' | sed 's/"//g'
练习5


若有收获,就点个赞吧
0 人点赞
