统计学习的方法
统计学习方法可以概括如下: 从给定的、有限的、用于学习的训练数据集合出发,假设数据是独立同分布产生的;并且假设要学习的模型属于某个函数的集合,称为假设空间;应用某个评价准则,从假设空间中选取一个最优模型,使它对已知的训练数据及未知的测试数据在给定的评价准则下有最优的预测。最优模型的选取由算法实现。
这其中包含了模型的假设空间(模型),模型选择的准则(策略),模型学习的算法(算法),称之为统计学习的三要素。
统计学习的分类

基本分类
监督学习
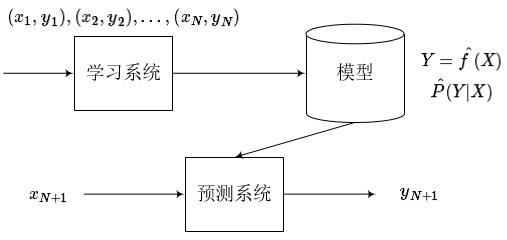
监督学习是指从标注数据中学习预测模型的机器学习方法。标注数据表示输入输出的对应关系,预测模型对给定的输入产生相应的输出。监督学习的本质是学习输入到输出的统计规律。
监督学习分为学习和预测两个过程,由学习系统与预测系统完成。在学习过程中,学习系统利用给定的训练数据集,通过学习(或训练)得到一个模型,表示为条件概率分布 或决策函数
或决策函数  描述输入与输出随机变量之间的映射关系。在预测过程中,预测系统对于给定的测试样本集中的输入X,由模型
描述输入与输出随机变量之间的映射关系。在预测过程中,预测系统对于给定的测试样本集中的输入X,由模型 或
或 给出响应的输出。
给出响应的输出。
在监督学习中,我们假设训练数据与测试数据是依联合概率分布P(X, Y)独立同分布产生的。学习系统试图通过训练集中的样本带来的信息学习模型。通过最小化预测输出和真实标签的误差,同时兼顾对未知数据的泛化,选择出最好的模型。
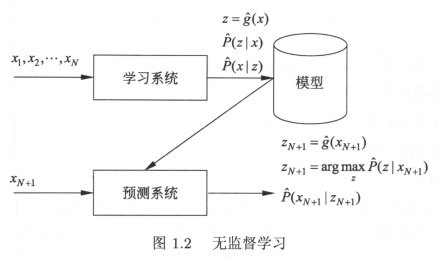
无监督学习
无监督学习是指从无标注数据中学习预测模型的机器学习问题。无标注数据是自然得到的数据。预测模型表示数据的类别,转换或概率。无监督学习的本质是学习数据中的统计规律或潜在结构。
无监督学习的每一个输出可以是对输入分类的一个类别,或者是对输入的一种转换,或者是对概率的一种估计。无监督学习可以实现对数据的聚类,降维或概率估计。用数学的语言来描述的话,无监督学习到的模型可以表示为 (进行分类)或者
(进行分类)或者 进行降维,或者由模型
进行降维,或者由模型 给出输入的概率
给出输入的概率 ,进行概率估计。
,进行概率估计。
强化学习
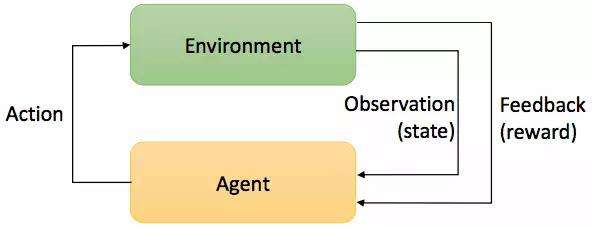
强化学习是指智能系统在与环境的连续互动中学习最优行为策略的机器学习问题。假设智能系统与环境的互动基于马尔科夫决策过程,智能系统观测到的是与环境互动得到的数据序列。强化学习的本质是学习最优的序贯决策。
如上图,智能系统在每一步t,从环境中观测到一个状态S与一个奖励r采取一个动作a。环境根据智能系统选择的动作,决定下一步t+1的状态S与奖励r。 要学习的策略就是在给定状态下,采取什么样的动作。智能系统的目标,是长期积累的奖励的最大化。在强化学习的过程中,系统不断地试错,以达成学习最优策略的目的。
半监督学习与主动学习
半监督学习指利用标注数据和未标注数据进行学习。主动学习是指机器主动给出需要标注的实例请人工进行标注。这两者的共同动机在于人工标注数据成本较高,可能能给标注的数据有限。因此,在半监督学习中,研究如何利用未标注数据辅助标注数据进行学习,在主动学习中,系统找出对学习最优价值的实例让人工进行标注。这两者都是期望以较小的标注成本达到更好的学习效果。其本质上都接近于监督学习。
按模型分类
概率模型与非概率模型
统计学习的模型按照学习到的形式是概率形式还是确定形式可以分为概率模型(probabilistic model)和确定性模型(deterministic model)。
 概率模型和确定性模型的核心区别在于,概率模型一定可以表示为联合概率分布的形式。其中的随机变量表示输入输出,隐变量甚至参数。而非概率模型则不一定存在这样的联合概率分别。
概率模型和确定性模型的核心区别在于,概率模型一定可以表示为联合概率分布的形式。其中的随机变量表示输入输出,隐变量甚至参数。而非概率模型则不一定存在这样的联合概率分别。
至于最终学习得到的条件概率分布或者函数是可以相互转换的。条件概率分布最大化之后是函数,函数归一化后是条件概率分布。
监督学习+概率模型 = 生成模型
监督学习+非概率模型 = 判别模型
线性模型与非线性模型

参数化模型与非参数化模型

按算法分类
按算法分类可以把统计学习分为在线学习与批量学习。在线学习是指每次接受一个样本进行预测,之后根据损失学习模型,并不断重复上述操作。而批量学习一次接受所有数据来学习模型。
利用随机梯度下降的感知机学习算法就是在线学习算法。
按技巧分类
贝叶斯学习

(上图的贝叶斯公式有错误)
假设随机变量D表示数据,随机变量 表示模型参数。贝叶斯估计和极大似然估计的在于,极大似然估计认为模型参数是一个确定值,不会发生变化。因此极大似然估计通过极大化似然函数,获得。而贝叶斯估计认为服从一个先验分布。依据观察到的数据D,我们可以修正先验分布得到一个后验分布。而贝叶斯学习的预测过程可以看做是利用后验分布计算分布期望值的过程。
表示模型参数。贝叶斯估计和极大似然估计的在于,极大似然估计认为模型参数是一个确定值,不会发生变化。因此极大似然估计通过极大化似然函数,获得。而贝叶斯估计认为服从一个先验分布。依据观察到的数据D,我们可以修正先验分布得到一个后验分布。而贝叶斯学习的预测过程可以看做是利用后验分布计算分布期望值的过程。
贝叶斯定理计算后验概率:

其中 代表了先验分布,
代表了先验分布, 代表了各种下D发生的全概率。
代表了各种下D发生的全概率。 代表了似然函数,
代表了似然函数, 代表了后验分布。进行估计/预测时,通常最大化后验概率来进行估计。
代表了后验分布。进行估计/预测时,通常最大化后验概率来进行估计。
预测数据时,也可以计算需要预测的数据在后验分布下的期望值。
核方法
核方法是使用核函数表示和学习非线性模型的机器学习方法。如核函数支持向量机,核PCA,核k均值等都属于核方法。
通常把线性模型扩展到非线性模型的方法是显式地定义从输入空间(低维空间)到特征空间(高维空间)的映射,在特征空间进行线性计算。比如,可以把线性不可分问题转化为线性可分问题,然后使用支持向量机解决。核方法的能够直接定义核函数,然后直接利用核函数基于输入空间进行计算,而不需要显式地定义特征空间。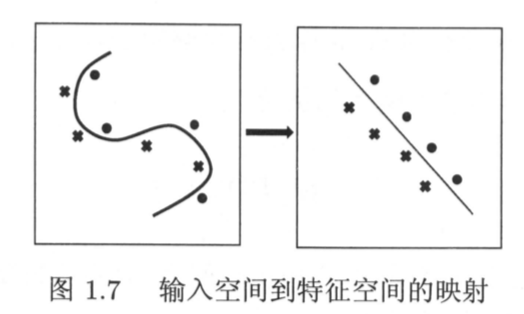
统计学习方法三要素
统计学习方法都是由模型,策略和算法构成的。即
方法 = 模型 + 策略 + 算法
模型
在监督学习中,模型就是要学习的条件概率分布或决策函数。模型的假设空间包含了所有的候选模型。假设空间用F表示。 代表参数空间。对于决策函数,假设空间可以表示为:
假设空间也可以表示为条件概率的集合:
其中X, Y是定义在输入空间和输出空间上的随机变量。
策略
损失函数和风险函数用来度量模型预测的好坏。损失函数度量模型一次预测的好坏,而风险函数度量平均意义下模型预测的好坏。
常用损失函数
常用的损失函数有
- 0-1损失函数

- 平方损失函数
 **
**
- 绝对损失函数
 **
**
- 对数损失函数

P(Y|X)的概率越大,它的对数值为负且越接近于0(因为概率小于1)。因此这个式子可以用来衡量分类的正确性。
对于多分类分类器,对数损失的计算公式可以进一步展开为
其中Y为输出结果,X为输入集,N为样本数量,M为类别个数, 为指示函数,是Y的分量,表示该样本是否属于某类别,属于为1,否则为0。
为指示函数,是Y的分量,表示该样本是否属于某类别,属于为1,否则为0。 为第i个样本是第j个类别的概率,是预测结果。
为第i个样本是第j个类别的概率,是预测结果。
对于(0,1)二类分类器,对数损失的公式可以简化为:
经验风险(经验损失)
给定一个训练数据集,模型关于训练数据集的平均损失称为经验风险或经验损失。即
期望风险 是模型关于联合分布的期望损失。如果我们能知道期望损失,那么就能完美衡量模型的性能。当然这个不现实,因此只能用经验风险来近似期望风险。这个近似是有一定风险的。如果近似差距较大,就会发生过拟合的现象。因此,需要考虑结构风险最小化。
是模型关于联合分布的期望损失。如果我们能知道期望损失,那么就能完美衡量模型的性能。当然这个不现实,因此只能用经验风险来近似期望风险。这个近似是有一定风险的。如果近似差距较大,就会发生过拟合的现象。因此,需要考虑结构风险最小化。
经验风险最小化与结构风险最小化
样本容量足够大的时候,经验风险是对期望风险的一个良好估计。因此经验风险最小化能够得到不错的学习效果。极大似然估计就是经验风险最小化的一个例子。可以证明,当模型是条件概率分布,损失函数是对数损失时,最大似然估计就是经验风险最小化。(证明见习题二)。
样本容量不够大时,单纯依赖于经验风险会产生”过拟合“现象。而结构风险最小化就是为了防止过拟合而提出来的策略。结构风险最小化通过增加一个惩罚项来抑制模型的复杂度。结构风险的定义如下:
 代表了模型的复杂度,模型越复杂,取值越大。结构风险最小化,有利于抑制模型变得过于复杂。
代表了模型的复杂度,模型越复杂,取值越大。结构风险最小化,有利于抑制模型变得过于复杂。
贝叶斯估计中的最大后验概率估计就是结构风险最小化的例子。当模型是条件概率分布,损失函数是对数损失,模型复杂度由模型的先验概率表示时,结构风险最小化就等价于最大后验估计。(证明见习题二)
算法
算法是指学习模型的具体计算方法。统计学习基于训练数据,根据学习策略,从假设空间中选择出最优的模型。算法就是考虑用什么样的计算方法求解出最优模型。此时,统计学习方法转化为最优化方法。通常情况下,最优化问题不存在解析解,需要用数值计算的方法来找到全局最优解(或足够好的局部最优解)
模型评估与模型选择
训练误差与测试误差
我们期望学习到的模型对于未知数据也有很好地预测能力。这种能力我们也称之为模型的泛化能力。使用测试数据集是评估泛化能力的普遍方法。
模型在训练数据集上的平均损失称为训练误差。而模型在测试数据集上的平均损失称为测试误差。评估模型性能时使用的损失函数和训练模型时使用的损失函数原则上应该保持一致,但这不是必须的。
当损失函数是0-1损失时,测试误差也可以称为是测试数据集上的误差率。
这里 I 是指示函数,即 时为1,否则为0。
时为1,否则为0。
测试集的准确率为:
误差率+准确率=1。
过拟合与模型选择
当假设空间中含有不同复杂度的模型时,如何从其中选择出一个最理想,泛化能力最强,对未知数据预测误差很小的模型呢?这个就是如何选择模型以避免过拟合的问题。
过拟合一般是指为了提高对训练数据的拟合程度,在降低了训练损失的同时,增加了对未知数据预测的损失。具体如下图所示。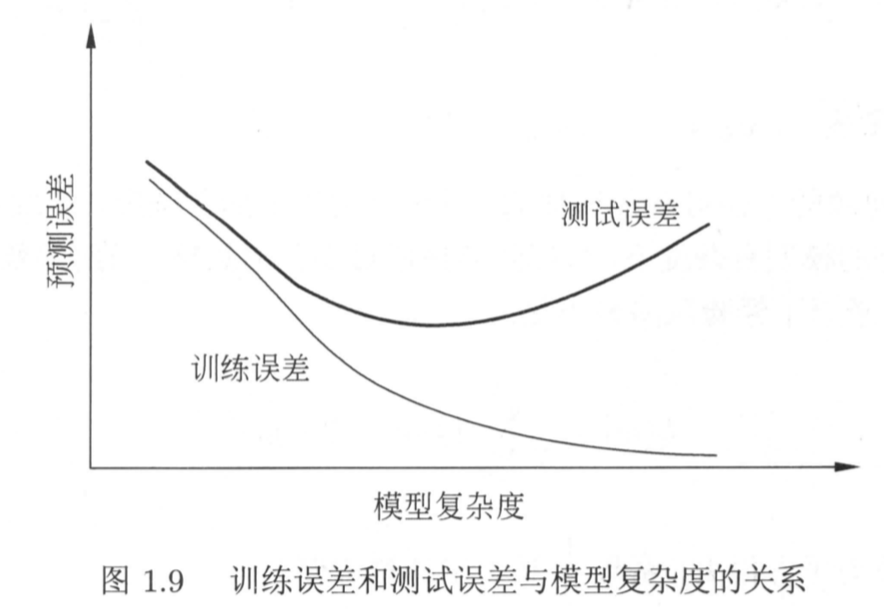
实际过程中经常使用的模型选择方法有正则化和交叉验证这两种方法。
正则化与交叉验证
正则化
正则化就是结构风险最小化的具体策略。一般通过在损失函数上增加一个和模型复杂度负相关的惩罚项来实现。即
常用的惩罚项有参数向量的L范数 或L范数
或L范数 。
。
从贝叶斯估计的角度来看,正则化项对应于模型的先验概率。复杂的事情通常较少发生,因此复杂的事情有比较小的先验概率。对于复杂的模型,通过惩罚项降低它被选中的概率,往往能得到更好的泛化能力。
交叉验证
简单交叉检验
即对于获得的数据进行划分,分为训练集与测试集。利用测试集上的测试误差来评估选择模型,选择出测试误差最小的模型。
S折交叉检验
获得的标注数据有限的情况下,可以把获得的数据切分为S个互不相交,大小相同的的子集。然后挑出一个子集作为测试数据集来评估模型性能。将这一过程进行S次,最后综合考虑后选出在S次评测中平均误差最小的模型。
留一交叉检验
可以认为是S折交叉验证的特殊情况,即只留了一条记录,重复评测的过程和记录数总数相同。一般在标注数据稀缺时考虑采用。
泛化能力
泛化误差
如前面所述,实践中经常使用测试误差评估模型的泛化能力。但为什么可以使用测试误差来评估泛化能力?机器学习为什么可以学到东西,为什么可行?这些都是关于学习理论的讨论。
我们把模型对于未知数据的预测误差称为泛化误差。也可以理解它是训练出来的模型在考虑了整个分布后的期望损失(而不是基于某个抽样数据集的损失)。
泛化误差上界
在本书中李航老师重点介绍了假设空间有限的情况下,利用霍夫丁不等式证明了泛化误差存在一个上界。但实际上,大多数假设空间都是无限的。假设空间无限(但模型复杂度有限)的情况下,讨论泛化误差上界需要引入VC维的概念。在林轩田老师的机器学习基石课程中,对于VC维以及机器学习的可行性做了非常详尽的阐释,可以参考课程。
生成模型与判别模型
监督学习方法可以分为生成方法和判别方法。
生成方法根据数据试图学习出联合概率分布P(X,Y)。然后根据联合概率分布求出条件概率分布作为预测的模型,即生成模型。生成方法命名的原因是因为我们认为训练集是由一个联合概率分布生成的,学习的目的就是找到背后的联合概率分布。典型的生成模型有朴素贝叶斯法,隐马尔科夫模型等。
判别方法则直接学习给定X的条件概率,或者决策函数f(X)。判别方法关心的是给定输入X,应该输出什么样的Y。典型的方法包括:k近邻法,感知机,决策树等。
生成方法学习在样本量增加时,更容易收敛于理想真实模型。当存在隐变量时,生成方法仍然可以工作。判别方法直面要解决的问题,同样样本量下学习的准确率可能更高,能够利用特征工程简化学习问题。因此这两种方法各有优缺点。
监督学习应用
监督学习的应用主要在三个方面:分类问题,标注问题和回归问题。
分类问题
评价分类器性能的指标一般是分类准确率。其定义是,对于给定的测试数据集,分类器正确分类的样本数与总样本数之比。
对于二分类问题,常见的评价指标还有精确率(precision)与召回率。原书公式有印刷错误。正确的指标公式如下:
TP = 真阳性
FN = 假阴性
FP = 假阳性
TN = 真阴性
准确率 accuracy: 
精确率(precision)/查准率:

标注问题
标记问题的输入是一个观测序列,输出是一个标记序列或状态序列。标记问题的目标是学习到一个标注模型。学习系统基于训练数据构建出一个条件概率分布模型,在给定的输入观测序列下,某种标记序列的条件概率是多大
输入序列和输出序列是等长的。
标注常用的统计学习方法有隐马尔科夫模型,条件随机场等。常常被用在信息抽取,自然语言处理等领域。
回归问题
回归问题用来建模预测自变量和因变量之间的关系。回归问题的学习等价于函数拟合。按照变量个数可以分为一元回归和多元回归,按模型类型分为线性回归和非线性回归。最常用的损失函数是平方损失。
章节关系
https://github.com/SmirkCao/Lihang/blob/master/assets/data_algo_map.png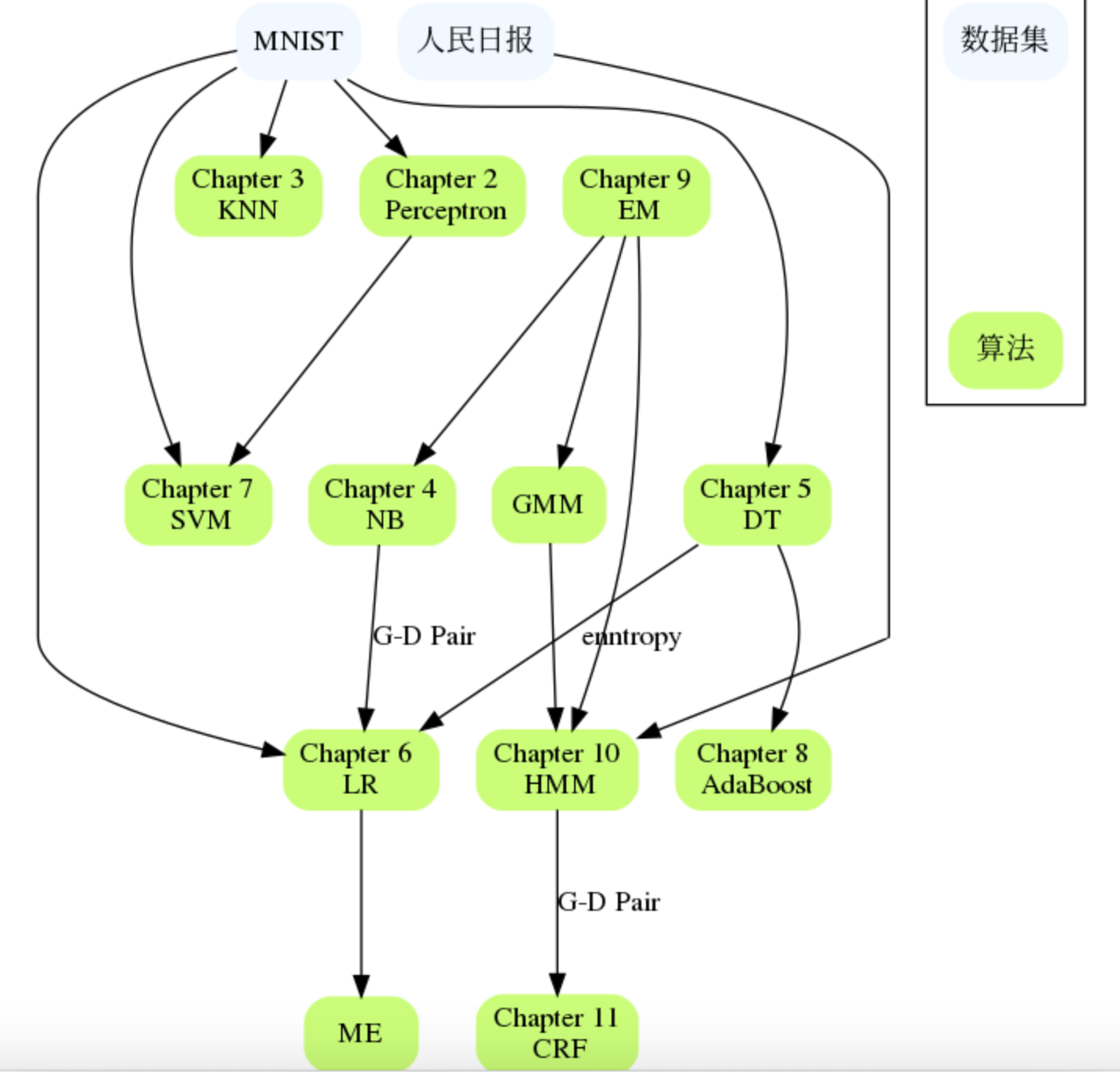

若有收获,就点个赞吧
0 人点赞

{kind=link}