13.1 ZooKeeper伪集群安装和配置
安装目录:D:\develop\zookeeper-3.4.13
13.1.1 创建数据目录和日志目录
ZooKeeper节点数有以下要求:
- ZooKeeper集群节点数必须是基数
- ZooKeeper集群节点数必须是基数
13.1.2 创建myid文本文件
myid文件的特点如下:
- myid文件的唯一作用,是存放(伪)节点的编号;
- myid文件是一个文本文件,文件名称为myid;
- myid文件内容为一个数字,表示节点的编号;
- myid文件中,只能有一个数字,不能有其他的内容;
-
13.1.3 创建和修改配置文件
13.1.4 配置文件示例
13.1.5 启动ZooKeeper伪集群
13.2 使用ZooKeeper进行分布式存储
13.1.1 详解:Zookeeper存储模型
ZooKeeper的存储模型是一棵以 “/“ 为根节点的树, 存储模型中的每一个节点,叫做ZNode(ZooKeeper node)节点。所有的ZNode节点,通过树的目录结构按照层次关系组织在一起,构成一棵ZNode树。
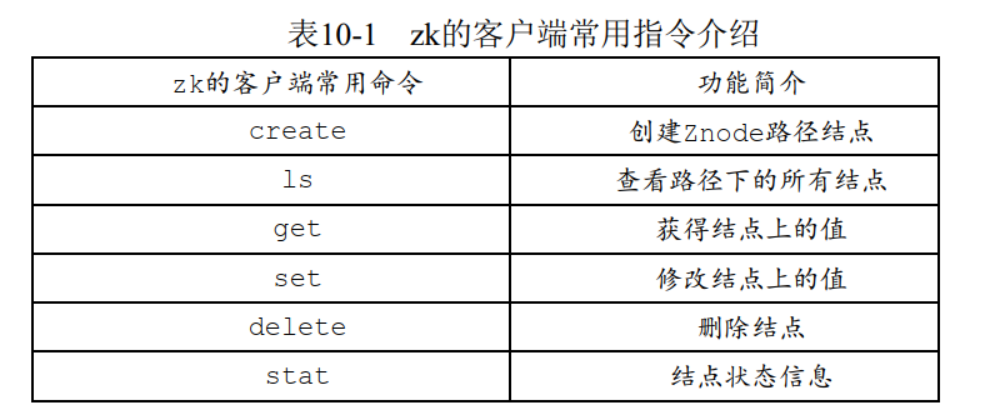
ZooKeeper为了保证高吞吐和低延迟,整个树状的目录结构全部都放在内存中。与硬盘和其他的外存设备相比,机器的内存比较有限,使得ZooKeeper的目录结构,不能用于存放大量的数据。 ZooKeeper官方的要求是,每个节点存放的Payload负载数据的上限,仅仅为1M13.2.2 zkCli客户端指令清单
使用stat指令可以查看ZNode树的根节点“/”的状态信息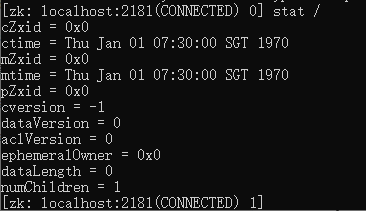
一个Znode的建立或者更新, 都会产生一个新的Zxid值,所以在节点信息中,保存了3个Zxid事务ID值,分别是: cZxid: Znode节点创建时的事务ID (Transaction id);
- mZxid: Znode节点修改时的事务ID,与子节点无关;
- pZxid: Znode节点的子节点的最后一次创建或者修改时间,与孙子节点无关
stat指令所返回的节点信息,包含的时间戳有两个:
- ctime: Znode节点创建时的时间戳;
- mtime: Znode节点最新一次更新发生时的时间戳
stat指令所返回的节点信息,包含的版本号有三个:
- dataversion: 数据版本号;
- cversion:子节点版本号;
- aclversion:节点的ACL权限修改版本号
13.3 实战: ZooKeeper应用开发
ZooKeeper应用开发,主要通过Java客户端API去连接和操作ZooKeeper集群。可以供选择的Java客户端API 有:
- ZooKeeper官方的Java客户端API
-
13.3.1 ZkClient开源客户端介绍
ZkClient是一个开源客户端,在ZooKeeper原生API接口的基础上进行了包装,更便于开发人员使用。 ZkClient客户端,在一些著名的互联网开源项目中,到了应用,比如:阿里的分布式Dubbo框架,对它进行了集成使用
ZkClient也有它自身的不少不足之处,具体如下:
ZkClient社区不活跃,文档不够完善,几乎没有参考文档
- 异常处理简化(抛出RuntimeException);
- 重试机制比较难用
-
13.3.2 Curator开源客户端介绍
Curator是Netflix公司开源的一套ZooKeeper客户端框架,和ZkClient一样, Curator提供了非常底层的细节开发工作,包括Session会话超时重连、 掉线重连、 反复注册Watcher和NodeExistsException异常等
13.3.3 Curator开发之环境准备
curator-framework:对ZooKeeper的底层API的一些封装;
- curator-client:提供一些客户端的操作,例如重试策略等;
- curator-recipes:封装了一些高级特性,如: Cache事件监听、选举、分布式锁、分布式计数器、分布式Barrier等。
```xml
org.apache.curator curator-client 4.0.0 org.apache.ZooKeeper ZooKeeper
<a name="XIGIL"></a>## 13.3.4 实战Curator:客户端实例创建1. 使用工厂类`CuratorFrameworkFactory`的静态`newClient(…)`方法;1. 使用工厂类`CuratorFrameworkFactory`的静态`builder `构造者方法。```javapublic static CuratorFramework createSimple(String connectionString) {long stime = System.currentTimeMillis();// 重试策略:第一次重试等待1s,第二次重试等待2s,第三次重试等待4s// 第一个参数:等待时间的基础单位,单位为毫秒// 第二个参数:最大重试次数ExponentialBackoffRetry retryPolicy =new ExponentialBackoffRetry(1000, 3);// 获取 CuratorFramework 实例的最简单的方式// 第一个参数:zk的连接地址// 第二个参数:重试策略CuratorFramework client = CuratorFrameworkFactory.newClient(connectionString, retryPolicy);Logger.info("创建连接耗费时间ms:"+ (System.currentTimeMillis()-stime));return client;}/**方式二* @param connectionString zk的连接地址* @param retryPolicy 重试策略* @param connectionTimeoutMs 连接超时时间* @param sessionTimeoutMs 会话超时时间* @return CuratorFramework 实例*/public static CuratorFramework createWithOptions(String connectionString, RetryPolicy retryPolicy,int connectionTimeoutMs, int sessionTimeoutMs) {// builder 模式创建 CuratorFramework 实例return CuratorFrameworkFactory.builder().connectString(connectionString).retryPolicy(retryPolicy).connectionTimeoutMs(connectionTimeoutMs).sessionTimeoutMs(sessionTimeoutMs)// 其他的创建选项.build();}
13.3.5 实战Curator:节点创建
@Testpublic void createNode() {//客户端实例CuratorFramework client = ClientFactory.createSimple("127.0.0.1");try {// 启动客户端实例,连接服务器client.start();// 创建一个ZNode结点// 节点数据为payloadString data = "hello";byte[] payload = data.getBytes(StandardCharsets.UTF_8);String zkPath = "/test/CRUD/node-1";client.create().creatingParentContainersIfNeeded().withMode(CreateMode.PERSISTENT).forPath(zkPath, payload);} catch (Exception e) {e.printStackTrace();}finally {CloseableUtils.closeQuietly(client);}}
ZooKeeper节点有四种类型 :
- PERSISTENT 持久化节点
- PERSISTENT_SEQUENTIAL 持久化顺序节点
- PHEMERAL 临时节
-
13.3.6 实战Curator:读取节点
在Curator 框架,与节点读取的有关的方法,主要有三个:
(1)首先是判断节点是否存在,使用checkExists方法。
(2)其次是获取节点的数据,使用getData方法。
(3)最后是获取子节点列表,使用getChildren方法。/*** 读取节点*/@Testpublic void readNode() {// 创建客户端CuratorFramework client = ClientFactory.createSimple("127.0.0.1:2181");try {client.start();String zkPath = "/test/CRUD/node-1";Stat stat = client.checkExists().forPath(zkPath);if (null != stat){byte[] payload = client.getData().forPath(zkPath);String data = new String(payload, "UTF-8");log.info("read data:{}", data);String parentPath = "/test";List<String> children = client.getChildren().forPath(parentPath);for (String child : children) {log.info("child:{}", child);}}} catch (Exception e) {e.printStackTrace();}finally {CloseableUtils.closeQuietly(client);}}
13.3.7 实战Curator:更新节点
使用setData() 方法,进行同步更新
@Testpublic void updateNode() {CuratorFramework client = ClientFactory.createSimple("127.0.0.1:2181");try {client.start();String data = "hello world";byte[] payload = data.getBytes(StandardCharsets.UTF_8);String zkPath = "/test/CRUD/node-1";client.setData().forPath(zkPath, payload);} catch (Exception e) {e.printStackTrace();}finally {CloseableUtils.closeQuietly(client);}}
如果需要进行异步更新,如何处理呢?其实很简单: 通过SetDataBuilder 构造者实例的
inBackground(AsyncCallback callback)方法,设置一个AsyncCallback回调实例。@Testpublic void updateNodeAsync() {CuratorFramework client = ClientFactory.createSimple("127.0.0.1:2181");try {//更新完成监听器AsyncCallback.StringCallback callback = new AsyncCallback.StringCallback() {@Overridepublic void processResult(int i, String s, Object o, String s1) {System.out.println("i = " + i + " | " +"s = " + s + " | " +"o = " + o + " | " +"s1 = " + s1);}};client.start();String data = "hello, every body!";byte[] payload = data.getBytes(StandardCharsets.UTF_8);String zkPath = "/test/CRUD/node-1";client.setData().inBackground(callback) // 设置回调实例.forPath(zkPath, payload);} catch (Exception e) {e.printStackTrace();}finally {CloseableUtils.closeQuietly(client);}}
13.3.8 实战Curator:删除结点
@Testpublic void deleteNode() {CuratorFramework client = ClientFactory.createSimple("127.0.0.1:2181");try {client.start();String zkPath = "/test/CRUD/node-1";client.delete().forPath(zkPath);// 删除后查看结果String parentPath = "/test";List<String> children = client.getChildren().forPath(parentPath);for (String child : children) {log.info("child:{}", child);}} catch (Exception e) {e.printStackTrace();}finally {CloseableUtils.closeQuietly(client);}}
13.4 实战:分布式命名服务
命名服务,也就是提供系统中资源的标识能力。 ZooKeeper的命名服务,主要是利用ZooKeeper节点的树型分层结构和子节点的次序维护能力,为分布式系统中的资源命名。
典型的分布式命名服务场景有 分布式API目录
- 分布式的ID生成器
-
13.4.1 ID生成器
传统的数据库自增主键,或者单体Java应用的自增主键,已经不能满足分布式ID生成器的需求。在分布式系统环境中,迫切需要一种全新的唯一ID系统,这种系统需要满足以下需求:
全局唯一:不能出现重复ID
- 高可用: ID生成系统是非常基础系统,被许多关键系统调用,一旦宕机,会造成严重影响。
分布式的ID生成器方案
- Java 的 UUID ;
- 分布式缓存Redis生成ID, 利用Redis的原子操作INCR和INCRBY,生成全局唯一的ID ;
- Twitter的Snowflake算法;
- ZooKeeper生成ID, 利用ZooKeeper 的顺序节点,生成全局唯一的ID;
- MongoDb的ObjectId, MongoDB是一个分布式的非结构化NoSql数据库,每插入一条记录,会自动生成的全局唯一的“_id” 字段值, 该值是一个12字节的字符串,可以作为分布式系统中全局唯一的ID。
UUID的优点:本地生成ID,不需要进行远程调用,时延低,性能高。
UUID的缺点: UUID过长, 16字节128位,通常以36长度的字符串表示,很多场景不适用,比如,由于UUID没有排序,无法保证趋势递增,用做数据库索引字段的效率就很低,新增记录存储入库时性能差。
13.4.2 实战:ZooKeeper分布式ID生成器
ZK的四种节点中,其中以下两种节点具备自动编号的能力:
- PERSISTENT_SEQUENTIAL 持久化顺序节点
- EPHEMERAL_SEQUENTIAL 临时顺序节点
通过创建ZK临时顺序节点的方法,生成全局唯一ID的演示代码,大致如下:
public class IDMaker {private static final String ZK_ADDRESS = "127.0.0.1:2181";CuratorFramework client = null;private String createSeqNode(String pathPrefix) {try {// 创建一个 ZNode 顺序节点// 为了避免 zookeeper 的顺序节点暴增,建议创建后, 直接删除创建的节点String destPath = client.create().creatingParentContainersIfNeeded().withMode(CreateMode.EPHEMERAL_SEQUENTIAL).forPath(pathPrefix);return destPath;} catch (Exception e) {e.printStackTrace();}return null;}//获取ID值public String makeId(String nodeName) {String str = createSeqNode(nodeName);if (null == str) {return null;}// 取得zk节点的末尾序号int index = str.lastIndexOf(nodeName);if (index >= 0) {index += nodeName.length();return index <= str.length() ? str.substring(index) : "";}return null;}}
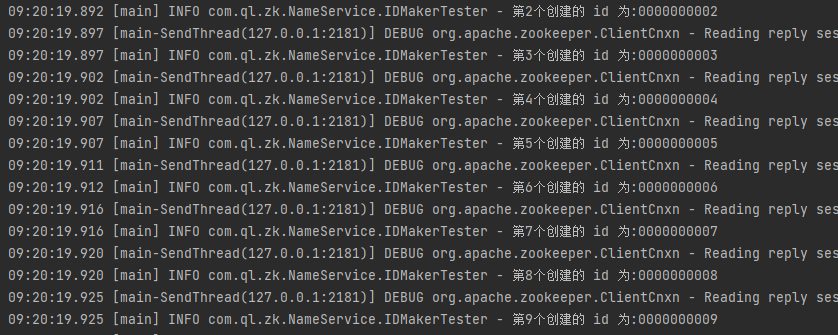
测试用例:
@Slf4jpublic class IDMakerTester {@Testpublic void testMakeId() {IDMaker idMaker = new IDMaker();idMaker.init();String nodeName = "/test/IDMaker/ID-";for (int i = 0; i < 10; i++) {String id = idMaker.makeId(nodeName);log.info("第"+ i + "个创建的 id 为:" + id);}idMaker.destroy();}}
13.4.3 实战:集群节点的命名服务
有以下两个方案,可供生成集群节点编号:
- 使用数据库的自增ID特性,用数据表,存储机器的MAC地址或者IP来维护
- 使用ZooKeeper持久顺序节点的次序特性,来维护节点的NodeId编号。
这里使用第二种:
public class SnowflakeIdWorker {transient private CuratorFramework zkClient = null;//工作节点的路径private String pathPrefix = "/test/IDMaker/worker-";private String pathRegistered = null;public static SnowflakeIdWorker instance = new SnowflakeIdWorker();public SnowflakeIdWorker() {this.zkClient = ZKclient.instance.getClient();this.init();}// 在zookeeper中创建临时节点并写入信息public void init() {// 创建一个 ZNode 节点// 节点的 payload 为当前worker 实例try {byte[] payload = pathPrefix.getBytes(StandardCharsets.UTF_8);pathRegistered = zkClient.create().creatingParentsIfNeeded().withMode(CreateMode.EPHEMERAL_SEQUENTIAL).forPath(pathPrefix, payload);} catch (Exception e) {e.printStackTrace();}}public long getId() {String sid = null;if (null == pathRegistered) {throw new RuntimeException("节点注册失败");}int index = pathRegistered.lastIndexOf(pathPrefix);if (index >= 0) {index += pathPrefix.length();sid = index <= pathRegistered.length() ? pathRegistered.substring(index) : null;}if (null == sid) {throw new RuntimeException("节点ID生成失败");}return Long.parseLong(sid);}}
13.4.4 结合ZK实现SnowFlake ID算法
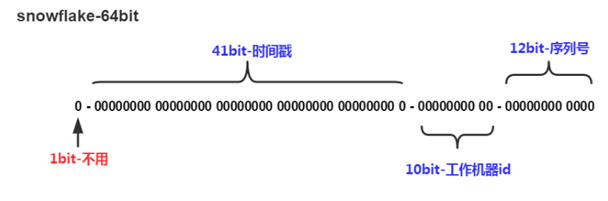
- SnowFlake ID 的组成
SnowFlake算法所生成的ID是一个64bit的长整形数字
SnowFlake ID 的实现
public class SnowflakeIdGenerator {public static SnowflakeIdGenerator instance = new SnowflakeIdGenerator();public synchronized void init(long workerId) {if (workerId > MAX_WORKER_ID) {// zk分配的workerId过大throw new IllegalArgumentException("woker Id wrong: " + workerId);}instance.workerId = workerId;}private SnowflakeIdGenerator() {}/*** 开始使用该算法的时间为: 2017-01-01 00:00:00*/private static final long START_TIME = 1483200000000L;/*** worker id 的bit数,最多支持8192个节点*/private static final int WORKER_ID_BITS = 13;/*** 序列号,支持单节点最高每毫秒的最大ID数1024*/private final static int SEQUENCE_BITS = 10;/*** 最大的 worker id ,8091* -1 的补码(二进制全1)右移13位, 然后取反*/private final static long MAX_WORKER_ID = ~(-1L << WORKER_ID_BITS);/*** 最大的序列号,1023* -1 的补码(二进制全1)右移10位, 然后取反*/private final static long MAX_SEQUENCE = ~(-1L << SEQUENCE_BITS);/*** worker 节点编号的移位*/private final static long WORKER_ID_SHIFT = SEQUENCE_BITS;/*** 时间戳的移位*/private final static long TIMESTAMP_LEFT_SHIFT = WORKER_ID_BITS + SEQUENCE_BITS;/*** 该项目的worker 节点 id*/private long workerId;/*** 上次生成ID的时间戳*/private long lastTimestamp = -1L;/*** 当前毫秒生成的序列*/private long sequence = 0L;/*** Next id long.** @return the nextId*/public Long nextId() {return generateId();}private synchronized long generateId() {long current = System.currentTimeMillis();if (current < lastTimestamp) {// 如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过,出现问题返回-1return -1;}if (current == lastTimestamp) {// 如果当前生成id的时间还是上次的时间,那么对sequence序列号进行+1sequence = (sequence + 1) & MAX_SEQUENCE;if (sequence == MAX_SEQUENCE) {// 当前毫秒生成的序列数已经大于最大值,那么阻塞到下一个毫秒再获取新的时间戳current = this.nextMs(lastTimestamp);}}else {// 当前的时间戳已经是下一个毫秒sequence = 0L;}// 更新上次生成id的时间戳lastTimestamp = current;// 进行移位操作生成int64的唯一ID//时间戳右移动23位long time = (current - START_TIME) << TIMESTAMP_LEFT_SHIFT;//workerId 右移动10位long workerId = this.workerId << WORKER_ID_SHIFT;return time | workerId | sequence;}private long nextMs(long timeStamp) {long current = System.currentTimeMillis();while (current <= timeStamp) {current = System.currentTimeMillis();}return current;}}
测试: ```java @Slf4j public class SnowflakeIdTest { @Test public void snowflakeIdTest() {
long workId = SnowflakeIdWorker.instance.getId();SnowflakeIdGenerator.instance.init(workId);ExecutorService es = Executors.newFixedThreadPool(10);final HashSet idSet = new HashSet();Collections.synchronizedCollection(idSet);long start = System.currentTimeMillis();log.info("开始生产 *");for (int i = 0; i < 10; i++) {es.execute(() -> {for (int j = 0; j < 5000; j++) {long id = SnowflakeIdGenerator.instance.nextId();synchronized (idSet){idSet.add(id);}}});}es.shutdown();try {es.awaitTermination(10, TimeUnit.SECONDS);} catch (InterruptedException e) {e.printStackTrace();}long end = System.currentTimeMillis();log.info("生产id结束");log.info("* 耗费: " + (end - start) + " ms!");
} }
<br /> SnowFlake算法的优点:<br />(1)生成ID时不依赖于数据库,完全在内存生成,高性能高可用。<br />(2)容量大,每秒可生成几百万ID。<br />(3) ID呈趋势递增,后续插入数据库的索引树的时候,性能较高。 <br /> SnowFlake算法的缺点:<br />(1)依赖于系统时钟的一致性,如果某台机器的系统时钟回拨,有可能造成ID冲突,或者ID乱序;<br />(2)在启动之前,如果这台机器的系统时间回拨过,那么有可能出现ID重复的危险<a name="k4Idn"></a># 13.5 重点:分布式事件监听事件监听有两种模式:<br />(1)一种是标准的观察者模式;<br />(2)一种是缓存监听模式。 <br /> 第一种标准的观察者模式,是通过Watcher监听器去实现;第二种缓存监听模式,通过引入了一种本地缓存视图Cache机制去实现。 第二种Cache事件监听机制,可以理解为一个本地缓存视图与远程ZooKeeper视图的对比过程,简单来说, Cache在客户端缓存了Znode的各种状态,当感知到ZooKeeper集群Znode状态变化,会触发event事件, 注册在这些事件上的监听器会处理这些事件。<a name="nj74O"></a>## 13.5.1 Watcher标准的事件处理器在ZooKeeper中,接口类型Watcher用于表示一个标准的事件处理器,用来定义收到事件通知后相关的回调处理逻辑。 接口类型Watcher包含KeeperState和EventType两个内部枚举类,分别代表了通知状态和事件类型。 <br /> 定义回调处理逻辑,需要使用Watcher接口的事件回调方法:<br />`process(WatchedEvent event)`一个Watcher监听器在向服务端完成注册后,当服务端的一些事件触发了这个Watcher,那么就会向注册过的客户端会话发送一个事件通知,来实现分布式的通知功能。在Curator客户端收到服务器的通知后,会封装一个WatchedEvent 事件实例,传递给监听器的process(WatchedEvent)回调方法 <br /> <br /> WatchedEvent包含了三个基本属性:<br />(1)通知状态(keeperState)<br />(2)事件类型(EventType)<br />(3)节点路径(path)1. Watcher 接口定义的通知状态和事件类型1. Watcher 使用实战```java@Slf4jpublic class ZKWatcherDemo {private String workerPath = "/test/listener/node";private String subWorkerPath = "/test/listener/node/id-";//利用watcher来对节点进行监听操作@Testpublic void testWatcher() {CuratorFramework client = ZKclient.instance.getClient();// 检查节点是否存在,没有则创建boolean isExist = ZKclient.instance.isNodeExist(workerPath);if (!isExist) {ZKclient.instance.createNode(workerPath, null);}try {Watcher w = new Watcher() {@Overridepublic void process(WatchedEvent watchedEvent) {System.out.println("监听到的变化 watchedEvent = " + watchedEvent);}};byte[] content = client.getData().usingWatcher(w).forPath(workerPath);log.info("监听节点内容: " + new String(content));// 第一次变更节点数据client.setData().forPath(workerPath, "第 1 次更改内容".getBytes());// 第二次变更节点数据client.setData().forPath(workerPath, "第 2 次更改内容".getBytes());Thread.sleep(Integer.MAX_VALUE);} catch (Exception e) {e.printStackTrace();}}}
既然Watcher监听器是一次性的,如果要反复使用,怎么办呢? 需要反复的通过构造者的usingWatcher方法,去提前进行注册。所以, Watcher监听器不适用于节点的数据频繁变动或者节点频繁变动这样的业务场景,而是适用于一些特殊的、变动不频繁的场景,比 如会话超时、授权失败等这样的特殊场景。既然Watcher需要反复注册,比较繁琐,所以, Curator引入了Cache来监听ZooKeeper服务端的事件。 Cache对ZooKeeper事件监听进行了封装,能够自动处理反复注册监听。
13.5.2 NodeCache 节点缓存的监听
Curator引入的Cache缓存实现, Cache缓存拥有一个系列的类型,包括了Node Cache 、Path Cache、 Tree Cache三组类。
(1)Node Cache节点缓存可以用于ZNode节点的监听;
(2)Path Cache子节点缓存用于ZNode的子节点的监听;
(3) Tree Cache树缓存是Path Cache的增强, 不仅仅能监听子节点,也能监听ZNode节点自身
Node Cache 事件监听的实战案例
@Testpublic void testNodeCache() {boolean isExist = ZKclient.instance.isNodeExist(workerPath);if (!isExist) {ZKclient.instance.createNode(workerPath, null);}CuratorFramework client = ZKclient.instance.getClient();try {NodeCache nodeCache = new NodeCache(client, workerPath, false);NodeCacheListener listener = new NodeCacheListener() {@Overridepublic void nodeChanged() throws Exception {ChildData childData = nodeCache.getCurrentData();log.info("ZNode节点状态改变, path={}", childData.getPath());log.info("ZNode节点状态改变, data={}", new String(childData.getData(), "UTF-8"));log.info("ZNode节点状态改变, stat={}", childData.getStat());}};//启动节点事件监听nodeCache.getListenable().addListener(listener);nodeCache.start();//第一次变更节点数据client.setData().forPath(workerPath, "第一次更改内容".getBytes(StandardCharsets.UTF_8));Thread.sleep(1000);//第二次变更节点数据client.setData().forPath(workerPath, "第二次更改内容".getBytes(StandardCharsets.UTF_8));Thread.sleep(1000);// 第 3 次变更节点数据client.setData().forPath(workerPath, "第三次更改内容".getBytes(StandardCharsets.UTF_8));Thread.sleep(1000);} catch (Exception e) {// e.printStackTrace();log.error("创建 NodeCache 监听失败, path={}", workerPath);}}

13.5.3 Path Cache 子节点监听
(1)只能监听子节点,监听不到当前节点
(2)不能递归监听,子节点下的子节点不能递归监控
启动节点的事件监听start方法,可以传入启动模式作为参数, 启动模式定义在StartMode枚举中,具体如下
( 1) BUILD_INITIAL_CACHE模式:启动时同步初始化Cache,表示创建Cache后,就从服务器拉取对应的数据;
( 2) POST_INITIALIZED_EVENT模式:启动时异步初始化Cache,表示创建Cache后,从服务器拉取对应的数据,完成后 PathChildrenCacheEvent.Type#INITIALIZED事件, Cache中Listener会收到该事件的通知;
( 3) NORMAL模式:启动时,异步初始化cache,完成后不会发出通知。
@Testpublic void testPathChildrenCache() {//检查节点是否存在,没有则创建boolean isExist = ZKclient.instance.isNodeExist(workerPath);if (!isExist) {ZKclient.instance.createNode(workerPath, null);}CuratorFramework client = ZKclient.instance.getClient();try {PathChildrenCache cache = new PathChildrenCache(client, workerPath, true);PathChildrenCacheListener listener = new PathChildrenCacheListener() {@Overridepublic void childEvent(CuratorFramework client, PathChildrenCacheEvent event) throws Exception {try {ChildData data = event.getData();switch (event.getType()) {case CHILD_ADDED:log.info("子节点增加, path={}, data={}", data.getPath(), new String(data.getData(), "UTF-8"));break;case CHILD_UPDATED:log.info("子节点更新, path={}, data={}", data.getPath(), new String(data.getData(), "UTF-8"));break;case CHILD_REMOVED:log.info("子节点删除, path={}, data={}", data.getPath(), new String(data.getData(), "UTF-8"));break;default:break;}}catch (Exception e) {e.printStackTrace();}}};cache.getListenable().addListener(listener);cache.start(PathChildrenCache.StartMode.BUILD_INITIAL_CACHE);Thread.sleep(1000);for (int i = 0; i < 3; i++) {ZKclient.instance.createNode(subWorkerPath + i, null);}Thread.sleep(1000);for (int i = 0; i < 3; i++) {ZKclient.instance.deleteNode(subWorkerPath + i);}} catch (Exception e) {log.error("PathCache监听失败, path=", workerPath);}}
13.5.4 Tree Cache 节点树缓存
Tree Cache可以看做是Node Cache、 Path Cache的合体; Tree Cache不光能监听子节点,也能监听节点自身。
@Testpublic void testTreeCache() {//检查节点是否存在,没有则创建boolean isExist = ZKclient.instance.isNodeExist(workerPath);if (!isExist) {ZKclient.instance.createNode(workerPath, null);}CuratorFramework client = ZKclient.instance.getClient();try {TreeCache treeCache = new TreeCache(client, workerPath);TreeCacheListener listener = new TreeCacheListener() {@Overridepublic void childEvent(CuratorFramework client, TreeCacheEvent event) {try {ChildData data = event.getData();if (data == null) {log.info("数据为空");return;}switch (event.getType()) {case NODE_ADDED:log.info("[TreeCache]节点增加, path={}, data={}",data.getPath(), new String(data.getData(), "UTF-8"));break;case NODE_UPDATED:log.info("[TreeCache]节点更新, path={}, data={}",data.getPath(), new String(data.getData(), "UTF-8"));break;case NODE_REMOVED:log.info("[TreeCache]节点删除, path={}, data={}",data.getPath(), new String(data.getData(), "UTF-8"));break;default:break;}} catch (Exception e) {e.printStackTrace();}}};//设置监听器treeCache.getListenable().addListener(listener);//启动缓存视图treeCache.start();Thread.sleep(1000);//创建 3 个子节点for (int i = 0; i < 3; i++) {ZKclient.instance.createNode(subWorkerPath + i, null);}Thread.sleep(1000);//删除 3 个子节点for (int i = 0; i < 3; i++) {ZKclient.instance.deleteNode(subWorkerPath + i);}Thread.sleep(1000);//删除当前节点ZKclient.instance.deleteNode(workerPath);Thread.sleep(Integer.MAX_VALUE);} catch (Exception e) {log.error("PathCache 监听失败, path=", workerPath);}}
TreeCacheEvent的事件类型,具体为:
(1) NODE_ADDED 对应于节点的增加;
(2) NODE_UPDATED 对应于节点的修改;
(3) NODE_REMOVED 对应于节点的删除。
Curator 事件监听的原理
Curator事件监听的原理:无论是PathChildrenCache,还是TreeCache,所谓的监听,都是进行Curator本地缓存视图和ZooKeeper服务器远程的数据节点的对比,并且进行数据同步时,会触发相应的事件。 以NODE_ADDED(节点新增事件)的触发为例, 进行简单说明。在本地缓存视图开始的创建的时候,本地视图为空,从服务器进行数据同步的时,本地的监听器就能监听到NODE_ADDED事件。为什么呢? 刚开始本地缓存并没有内容,然后本地缓存和服务器缓存进行对比,发现ZooKeeper服务器是有节点数据的,这才将服务器的节点缓存到本地,也会触发本地缓存的NODE_ADDED事件。
13.6 分布式锁原理与实战
13.6.1 公平锁和可重入锁的原理
13.6.2 ZooKeeper分布式锁的原理
13.6.3 分布式锁的基本流程
public interface Lock {boolean lock();boolean unlock();}
使用ZooKeeper实现分布式锁的算法, 有以下几个要点:
(1)一把分布式锁通常使用一个Znode节点表示;如果锁对应的Znode节点不存在,首先创建Znode节点。这里假设为“/test/lock”,代表了一把需要创建的分布式锁。
(2)抢占锁的所有客户端,使用锁的Znode节点的子节点列表来表示;如果某个客户端需要占用锁,则在“/test/lock”下创建一个临时有序的子节点。
(3)如果判定客户端是否占有锁呢? 很简单,客户端创建子节点后,需要进行判断:自己创建的子节点,是否为当前子节点列表中序号最小的子节点。如果是,则认为加锁成功;如果不是,则监听前一个Znode子节点变更消息,等待前一个节点释放锁。
(4)一旦队列中的后面的节点,获得前一个子节点变更通知,则开始进行判断,判断自己是否为当前子节点列表中序号最小的子节点,如果是,则认为加锁成功;如果不是,则持续监听,一直到获得锁。
(5)获取锁后,开始处理业务流程。完成业务流程后,删除自己的对应的子节点,完成释放锁的工作,以方面后继节点能捕获到节点变更通知,获得分布式锁。
13.6.4 实战:加锁的实现
lock()方法的大致流程是:首先尝试着去加锁,如果加锁失败就去等待,然后再重复
lock() 方法的实现代码 ```java @Override public boolean lock() {
//可重入,确保同一线程,可以重复加锁synchronized (this) {if (lockCount.get() == 0) {thread = Thread.currentThread();lockCount.incrementAndGet();}else {if (!thread.equals(Thread.currentThread())){return false;}lockCount.incrementAndGet();return true;}}try {boolean locked = false;//首先尝试着 去加锁locked = tryLock();if (locked) {return true;}// 如果加锁失败就去等待while (!locked) {await();//获取等待的子节点列表List<String> waiters = getWaiters();// 判断是否加锁成功if (checkLocked(waiters)) {locked = true;}}return true;}catch (Exception e) {e.printStackTrace();unlock();}return false;
}
2. tryLock()尝试加锁- 创建临时顺序节点,并且保存自己的节点路径- 判断是否是第一个,如果是第一个,则加锁成功。如果不是,就找到前一个Znode节点,并且保存其路径到prior_path。```javaprivate boolean tryLock() throws Exception {//创建临时Znodelocked_path = ZKclient.instance.createEphemeralSeqNode(LOCK_PREFIX);if (null == locked_path) {throw new Exception("zk error");}//取得加锁的排队编号locked_short_path = getShortPath(locked_path);//获取加锁的对列List<String> waiters = getWaiters();//获取等待的子节点列表,判断自己是否第一个if (checkLocked(waiters)) {return true;}// 判断自己排第几个int index = Collections.binarySearch(waiters, locked_short_path);if (index < 0) {// 网络抖动,获取到的子节点列表里可能已经没有自己了throw new Exception("节点没有找到: " + locked_short_path);}//如果自己没有获得锁// 保存前一个节点,稍候会监听前一个节点prior_path = ZK_PATH + "/" + waiters.get(index - 1);return false;}
- checkLocked()检查是否持有锁
在checkLocked()方法中,判断是否可以持有锁。判断规则很简单:当前创建的节点,是否在上一步获取到的子节点列表的第一个位置:
(1)如果是,说明可以持有锁,返回true,表示加锁成功;
(2)如果不是,说明有其他线程早已先持有了锁,返回false。
private boolean checkLocked(List<String> waiters) {//节点按照编号,升序排列Collections.sort(waiters);// 如果是第一个,代表自己已经获得了锁if (locked_short_path.equals(waiters.get(0))) {log.info("成功的获取分布式锁,节点为{}", locked_short_path);return true;}return false;}
- await() 监听前一个节点释放锁
监听前一个ZNode节点(prior_path成员) 的删除事件
private void await() throws Exception {if (null == prior_path) {throw new Exception("prior_path error");}final CountDownLatch latch = new CountDownLatch(1);//监听方式一: Watcher 一次性订阅//订阅比自己次小顺序节点的删除事件Watcher w = new Watcher() {@Overridepublic void process(WatchedEvent watchedEvent) {System.out.println("监听到的变化 watchedEvent = " + watchedEvent);log.info("[WatchedEvent]节点删除");latch.countDown();}};//开始监听client.getData().usingWatcher(w).forPath(prior_path);//限时等待,最长加锁时间为 3slatch.await(WAIT_TIME, TimeUnit.SECONDS);}
13.6.5 实战:释放锁的实现
(1)减少重入锁的计数,如果最终的值不是0,直接返回,表示成功的释放了一次;
(2)如果计数器为0,移除Watchers监听器,并且删除创建的Znode临时节点。
@Overridepublic boolean unlock() {//只有加锁的线程,能够解锁if (!thread.equals(Thread.currentThread())) {return false;}//减少可重入的计数int newLockCount = lockCount.decrementAndGet();//计数不能小于 0if (newLockCount < 0) {throw new IllegalMonitorStateException("计数不对: " + locked_path);}//如果计数不为 0,直接返回if (newLockCount != 0) {return true;}try {//删除结点if (ZKclient.instance.isNodeExist(locked_path)) {client.delete().forPath(locked_path);}}catch (Exception e) {e.printStackTrace();return false;}return true;}
13.6.6 实战:分布式锁的使用
@Slf4jpublic class ZkLockTester {//需要锁来保护的公共资源//变量int count = 0;@Testpublic void testLock() throws InterruptedException {//10 个并发任务for (int i = 0; i < 10; i++) {FutureTaskScheduler.add(() -> {//创建锁ZkLock lock = new ZkLock();lock.lock();//每条线程,执行10次累加for (int j = 0; j < 10; j++) {//公共的资源变量累加count++;}try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}log.info("count = " + count);//释放锁lock.unlock();});}Thread.sleep(Integer.MAX_VALUE);}}
13.6.7 实战:curator的InterProcessMutex可重入锁
分布式锁Zlock自主实现主要的价值: 学习一下分布式锁的原理和基础开发, 仅此而已。实际的开发中,如果需要使用到分布式锁,不建议去自己造轮子,建议直接使用Curator客户端中的各种官方实现的分布式锁,比如其中的InterProcessMutex 可重入锁。
@Testpublic void testZkMutex() throws InterruptedException {CuratorFramework client = ZKclient.instance.getClient();//创建互斥锁final InterProcessMutex zkMutex = new InterProcessMutex(client, "/mutex");//每条线程,执行10次累加for (int i = 0; i < 10; i++) {FutureTaskScheduler.add(() -> {try {//获取互斥锁zkMutex.acquire();for (int j = 0; j < 10; j++) {//公共的资源变量累加count++;}try {Thread.sleep(1000);}catch (Exception e) {e.printStackTrace();}log.info("count = " + count);//释放互斥锁zkMutex.release();} catch (Exception e) {e.printStackTrace();}});}Thread.sleep(Integer.MAX_VALUE);}
13.6.8 ZooKeeper分布式锁的优点和缺点
(1)优点: ZooKeeper分布式锁(如InterProcessMutex),能有效的解决分布式问题,不可重入问题,使用起来也较为简单。
(2)缺点: ZooKeeper实现的分布式锁,性能并不太高。为啥呢? 因为每次在创建锁和释放锁的过程中,都要动态创建、销毁瞬时节点来实现锁功能。大家知道, ZK中创建和删除节点只能通过Leader服务器来执行,然后Leader服务器还需要将数据同不到所有的Follower机器上,这样频繁的网络通信,性能的短板是非常突出的。
在目前分布式锁实现方案中,比较成熟、主流的方案有两种:
(1)基于Redis的分布式锁
(2)基于ZooKeeper的分布式锁
两种锁,分别适用的场景为:
( 1)基于ZooKeeper的分布式锁,适用于高可靠(高可用)而并发量不是太大的场景;
( 2)基于Redis的分布式锁,适用于并发量很大、性能要求很高的、而可靠性问题可以通过其他方案去弥补的场景。

若有收获,就点个赞吧
0 人点赞
