6 拓扑排序
拓扑排序,是 有向图 的一个应用。
定义一:
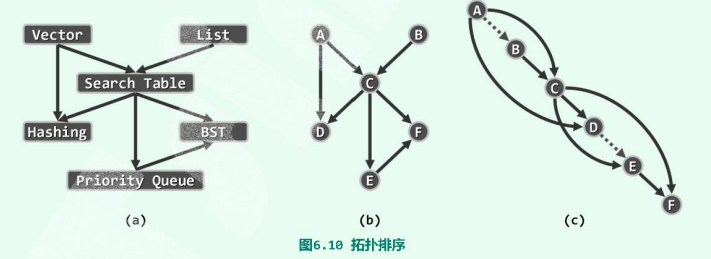
给定描述某一实际应用(图a)的有向图(图b),如何在该图“相容”的前提下,将所有顶点排成一个线性序列(图c)。这样的一个线性序列,称作原有向图的一个 拓扑排序(topological sorting)。
此处的“相容”指:每一顶点都不会通过边,指向其在此序列中的前驱顶点。
定义二:
设G=(V,E)是一个具有n个顶点的有向图,V中的顶点序列V1, V2, …. Vn,满足若从顶点Vi 到Vj有一条路径,则在顶点序列中顶点Vi必在顶点Vj 之前。则我们称这样的顶点序列为一个拓扑序列。
| 我们会把施工过程、生产流程、软件开发、教学安排等都当成一个项目工程来对待,所有的工程都可分为若千个“活动”的子工程。
例如图7-8-1 是电制作流程图。在这些活动之间,通常会受到一定的条件约束,如其中某些活动必
须在另一些活动完成之后才能开始。就像电影制作不可能在人员到位进驻场地时,导演还没有找到,也不可能在拍摄过程中,场地都没有。这都会导致荒谬的结果。因此这样的工程图,一定是**无环的有向图**。 |
| —- |
|
| —- |
AOV网(activity on vertex** network)**:在一个表示工程的有向图中,
- 用顶点表示活动,
- 用弧表示活动之间的优先关系,
这样的有向图为顶点表示活动的网,我们称为AOV 网( Activity On Vertex network)
- AOV网中的 弧 表示活动之间存在的某种制约关系(如:演员确定了、场地联系好了,才可以进场拍摄)。
- 另外,AOV网中不能存在回路。
- AOV网的拓扑排序不唯一。
6.1 有向无环图(DAG)
一个有向图的拓扑排序是否必然存在?如果存在是否唯一?
答:如下图所示,(c)中顶点A、B互换之后依然是一个拓扑排序,可知拓扑排序不一定唯一;
如果有向图中存在有向环路,则该有向图就不存在 拓扑排序。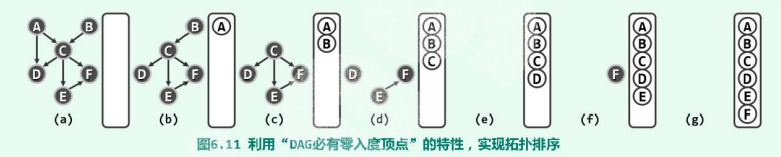
6.2 算法实现
6.2.1 一般算法
对AOV 网进行拓扑排序的基本思路是: 从AOV 网中选择一个人度为0 的顶点输出,然后删去此顶点,井删除以此顶点为尾的弧,继续重复此步骤,直到输出全部顶点或者AOV 网中不存在入度为0 的顶点为止。
6.2.2 基于DFS搜索实现拓扑排序算法
极大顶点:入度为0; 极小顶点:出度为零;
根据DFS搜索的特性,顶点m(当前顶点的入度为0)及其关联边 对伺候的搜索过程将不起任何作用。于是,下一转至VISITED状态的顶点可等效地理解为:从图中剔除顶点m及其关联边 之后的出度为0的顶点——在拓扑排序中该顶点应为顶点m的前驱。
由此可见,DFS搜索的过程中各顶点被标记为VISITED的次序,恰好** 按逆序 给出了 拓扑排序**。
实现:
template <typename Tv, typename Te> //基于DFS的拓扑排序算法Stack<Tv>* Graph<Tv, Te>::tSort ( int s ) { //assert: 0 <= s < nreset(); int clock = 0; int v = s;Stack<Tv>* S = new Stack<Tv>; //用栈记录排序顶点do {if ( UNDISCOVERED == status ( v ) )if ( !TSort ( v, clock, S ) ) { //clock并非必需/*DSA*/print ( S );while ( !S->empty() ) //任一连通域(亦即整图)非DAGS->pop(); break; //则不必继续计算,故直接返回}} while ( s != ( v = ( ++v % n ) ) );return S; //若输入为DAG,则S内各顶点自顶向底排序;否则(不存在拓扑排序),S空}template <typename Tv, typename Te> //基于DFS的拓扑排序算法(单趟)bool Graph<Tv, Te>::TSort ( int v, int& clock, Stack<Tv>* S ) { //assert: 0 <= v < ndTime ( v ) = ++clock; status ( v ) = DISCOVERED; //发现顶点vfor ( int u = firstNbr ( v ); -1 < u; u = nextNbr ( v, u ) ) //枚举v的所有邻居uswitch ( status ( u ) ) { //并视u的状态分别处理case UNDISCOVERED:parent ( u ) = v; type ( v, u ) = TREE;if ( !TSort ( u, clock, S ) ) //从顶点u处出发深入搜索return false; //若u及其后代不能拓扑排序(则全图亦必如此),故返回并报告break;case DISCOVERED:type ( v, u ) = BACKWARD; //一旦发现后向边(非DAG),则return false; //不必深入,故返回并报告default: //VISITED (digraphs only)type ( v, u ) = ( dTime ( v ) < dTime ( u ) ) ? FORWARD : CROSS;break;}status ( v ) = VISITED; S->push ( vertex ( v ) ); //顶点被标记为VISITED时,随即入栈return true; //v及其后代可以拓扑排序}
相对于标准的DFS搜索算法,这里增加了一个栈结构,一旦某一个顶点被标记为VISITED状态,就立马入栈。如此当搜索终止时,所有顶点即按照被访问完毕的次序——即拓扑排序的次序——在栈中自顶向下排列(即,将此时的栈中元素依次出栈,得到的就是拓扑排序)。
6.2.2.2 复杂度

6.2.2.2 实例
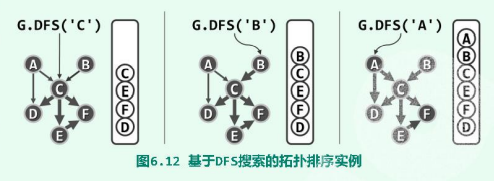
上图所示,一个含6个顶点、7条边的有向无环图,按照“基于DFS的拓扑排序算法”进行。
注意:
- 观察各顶点的入栈次序。
- 极大、极小 顶点(入度为0、出度为0)不止一个,所以,其拓扑排序不唯一。
7 双连通域分解(无向图中)
7.1 关节点与双连通域
在无向图G中,若删除顶点v后 G所包含的连通域增多,则称v为 切割点(cut vertex)或 关节点(articulation point)。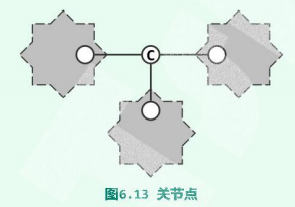
C即为 关节点——它的删除将导致连通域增加两块
关节点更为重要。在网络系统中它们对应于网关,决定子网之间能否连通。
反之,不含任何关节点的图称为 双连通图。
任何一个无向图都可看做是由若干个极大的双连通子图组合而成。这样的每一子图都称作原图的一个双连通域**(bi-connected component)**。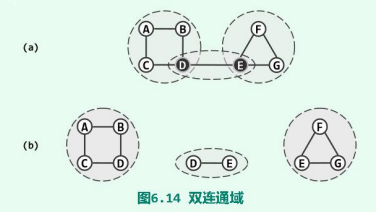
(a)中的无向图,可分解为(b)的三个双连通域
7.2 暴力算法
如何找出图中的关节点?
答:
- 通过BFS或DFS统计出图G包含的连通域数目;
- 逐一枚举各个顶点v,暂时将其从图中删去,在此通过搜索统计出图G{V}所含连通域的数目。
此时,当且仅当G{V}包含的连通域多余图G,顶点v才是关节点。
复杂度:
该算法需要执行n趟,耗时 。
。
7.3 更优算法
下面介绍一种,基于DFS搜索的另一种算法,它不仅可以调高效率,还可以对原图做双连通域分解。
叶节点、根节点:
- DFS树中的叶节点,绝不可能是原图中的关节点——此类顶点的删除既不影响DFS树的连通性,也不影响原图的连通性。
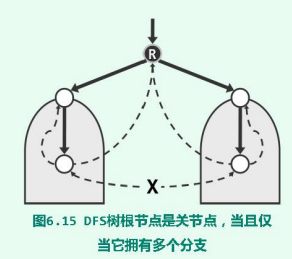
- DFS树的根节点若至少拥有两个分支,则必是一个关节点。
- 因为根节点R不同分支之间不可能通过 跨边 相连接,R是他们之间唯一的枢纽。
- 反之,如果根节点仅有一个分支,则与叶节点类似,R不可能是关节点。
内部节点:
- 若某内部节点C的移除导致其某一棵(比如以D为根的)真子树与其祖先(如A)之间无法连通,则C为关节点。
- 反之,若C的所有真子树都能(如以E为根的子树)与C的某一真祖先连通,则C就不是关节点。
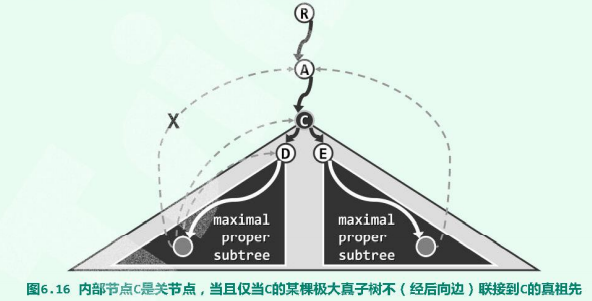
在原无向图中的DFS树中,C的真子树只可能通过“后向边”与C的真祖先连通。
因此,只要在DFS搜索过程记录并更新各顶点v所能(经由 后向边)连通的最高祖先(highest connected ancestor,HCA)hca[v],即可及时认定关节点,并报告对应的双连通域。
template <typename Tv, typename Te> void Graph<Tv, Te>::bcc ( int s ) { //基于DFS的BCC分解算法reset(); int clock = 0; int v = s; Stack<int> S; //栈S用以记录已访问的顶点doif ( UNDISCOVERED == status ( v ) ) { //一旦发现未发现的顶点(新连通分量)BCC ( v, clock, S ); //即从该顶点出发启动一次BCCS.pop(); //遍历返回后,弹出栈中最后一个顶点——当前连通域的起点}while ( s != ( v = ( ++v % n ) ) );}#define hca(x) (fTime(x)) //利用此处闲置的fTime[]充当hca[]template <typename Tv, typename Te> //顶点类型、边类型void Graph<Tv, Te>::BCC ( int v, int& clock, Stack<int>& S ) { //assert: 0 <= v < nhca ( v ) = dTime ( v ) = ++clock; status ( v ) = DISCOVERED; S.push ( v ); //v被发现并入栈for ( int u = firstNbr ( v ); -1 < u; u = nextNbr ( v, u ) ) //枚举v的所有邻居uswitch ( status ( u ) ) { //并视u的状态分别处理case UNDISCOVERED:parent ( u ) = v; type ( v, u ) = TREE; BCC ( u, clock, S ); //从顶点u处深入if ( hca ( u ) < dTime ( v ) ) //遍历返回后,若发现u(通过后向边)可指向v的真祖先hca ( v ) = min ( hca ( v ), hca ( u ) ); //则v亦必如此else { //否则,以v为关节点(u以下即是一个BCC,且其中顶点此时正集中于栈S的顶部)do {temp.push ( S.pop() ); print ( vertex ( temp.top() ) );} while ( v != temp.top() );while ( !temp.empty() ) S.push ( temp.pop() );while ( v != S.pop() ); //依次弹出当前BCC中的节点,亦可根据实际需求转存至其它结构S.push ( v ); //最后一个顶点(关节点)重新入栈——分摊不足一次}break;case DISCOVERED: //标记为‘后向边’type ( v, u ) = BACKWARD; //标记(v, u),并按照“越小越高”的准则if ( u != parent ( v ) ) hca ( v ) = min ( hca ( v ), dTime ( u ) ); //更新hca[v]break;default: //VISITED (digraphs only)type ( v, u ) = ( dTime ( v ) < dTime ( u ) ) ? FORWARD : CROSS;break;}status ( v ) = VISITED; //对v的访问结束}
由于处理的是无向图,在顶点vv的孩子uu处返回后,通过比较hca[u]与dTime[v]的大小,即可判断是否为关节点。
- 若hca[u]≥dTime[v],则说明u的后代无法通过后向边与v的真祖先联通,故v为关节点。
- 此时,栈S存有搜索过的顶点,与该 关节点相对应的双连通域内的顶点,此时都集中存放与栈S的顶部。故可依次弹出这些顶点。而v本身必然最后弹出,作为多个连通域的枢纽,它应当重新入栈。
- 若hca[u]<dTime[v],则意味着u可经由后向边连通至v的真祖先,所以v不可能是关节点。
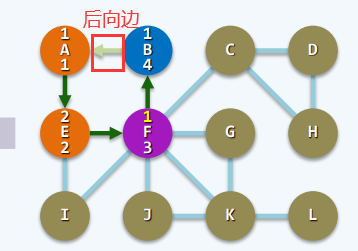
- 此时,则需要更新“hac(v)”。由于u可以指向v的祖先,所以,v可以通过u指向该祖先,所以需要更新“hac(v)”(即,更新v能连通的最高祖先):【如下图所示】

当每遇到一条后向边(v,u),也需要及时的将hca[v]更新为hca[v]和dTime[u]之间的小者,以确保hca[v]可以始终记录顶点v可经由 后向边 上连通的最高祖先。
/
|
下面看一个实例:
- 后向边:
07.图应用.pdf |
| —- |
7.3.1 复杂度
空间:
额外引入的栈复杂度不超过顶点总数O(n)O(n) ,总体而言,空间复杂度与基本深度优先算法一致,为O(n+e)。
时间:
时间方面,尽管同一节点可能多次入栈,但是每次入栈都对应于一个新发现的连通域,与之对应地必有至少另一顶点出栈并不再入栈,此类重复入栈操作不超过n次,入栈操作累计不超过2n次,为O(n+e)。
8 优先级搜索
以上图搜索,基本框架大致相似。都需要通过迭代逐一发现个顶点,将其纳入遍历树中并作相应处理,同时根据应用问题的需求,适时给出解答。
各算法的差异主要体现在:每一步迭代对新顶点的选取策略不同:
- BFS搜索会优先考察更早被发现的顶点;
- DFS搜索会优先考察最后被发现的顶点。
每一种选取策略等效于:给所有顶点赋予不同的优先级,而且随着算法的推进不断调还早呢个;而每一步迭代所选取的顶点,都是当时的优先级最高者。
按照这种说法,包括BFS和DFS在内的几乎所有图搜索,都可纳入统一框架中。
这种算法称为:优先级搜索(priority-first search, PFS)或 最佳优先搜索(best-first search, BFS)。
基本框架:
注意,这里假设 优先级数越小,其优先级越高。
template <typename Tv, typename Te> template <typename PU> //优先级搜索(全图)void Graph<Tv, Te>::pfs ( int s, PU prioUpdater ) { //assert: 0 <= s < nreset(); int v = s; //初始化do //逐一检查所有顶点if ( UNDISCOVERED == status ( v ) ) //一旦遇到尚未发现的顶点PFS ( v, prioUpdater ); //即从该顶点出发启动一次PFSwhile ( s != ( v = ( ++v % n ) ) ); //按序号检查,故不漏不重}template <typename Tv, typename Te> template <typename PU> //顶点类型、边类型、优先级更新器void Graph<Tv, Te>::PFS ( int s, PU prioUpdater ) { //优先级搜索(单个连通域)priority ( s ) = 0; status ( s ) = VISITED; parent ( s ) = -1; //初始化,起点s加至PFS树中while ( 1 ) { //将下一顶点和边加至PFS树中for ( int w = firstNbr ( s ); -1 < w; w = nextNbr ( s, w ) ) //枚举s的所有邻居wprioUpdater ( this, s, w ); //更新顶点w的优先级及其父顶点for ( int shortest = INT_MAX, w = 0; w < n; w++ )if ( UNDISCOVERED == status ( w ) ) //从尚未加入遍历树的顶点中if ( shortest > priority ( w ) ) //选出下一个{ shortest = priority ( w ); s = w; } //优先级最高的顶点sif ( VISITED == status ( s ) ) break; //直至所有顶点均已加入status ( s ) = VISITED; type ( parent ( s ), s ) = TREE; //将s及与其父的联边加入遍历树}} //通过定义具体的优先级更新策略prioUpdater,即可实现不同的算法功能
上述代码:
每次都是引入当前优先级最高(优先级数最小)的顶点s,然后按照不同的策略更新其邻接顶点的优先级数。
函数对象
prioUpdater,使算法设计者得以根据不同的问题需求,简明的描述和实现对应的更新策略。- 具体地,只需重新定义prioUpdater对象即可。
  |
|---|
下面,最小支撑树就使用了 最佳优先搜索算法。
9 最小支撑树
- 连通图G的某一无环连通子图T若覆盖G中所有顶点,则T为 G的一棵 支撑树 或 生成树(spanning tree)。
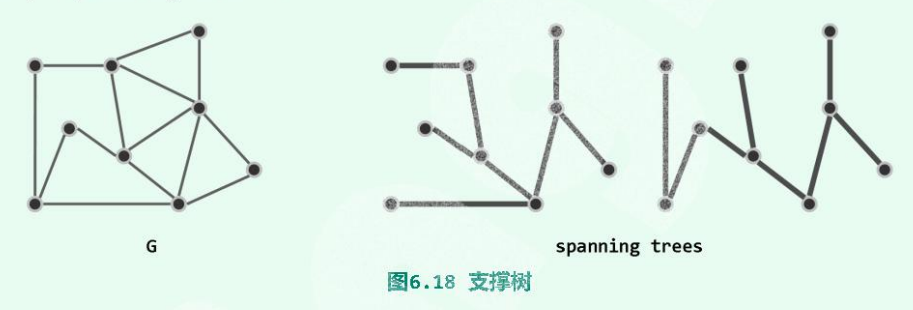
同一图可能有多个支撑树,但是其中的支撑树的顶点数均为n,边数均为n-1。
- 就保留原图G中边的数目而言, 支撑树 既是“禁止环路”前提下的极大子图,也是“**保持连通**”前提下的最小子图。
- 若图G为一带权网络,则每一棵支撑树的成本(cost)即为其所采用各边权重的总和。在G的所有支撑树中,成本最低的是 最小支撑树(minimum spanning tree,MST)。
最小支撑树的歧义性:
在图中的 最小支撑树未必唯一。若有两个或以上的支撑树的成本都是最低的,则这些支撑树叫做“极小支撑树(minimal spanning tree)”。
- 消除:通过强制附加某种次序便可消除这种歧义性。所以,不妨仍然称之为 最小支撑树。
9.1 蛮力算法
由最小支撑树定义,可直接导出蛮力算法大致如下:
- 逐一考察G的所有支撑树并统计其成本,找出成本最低者,即最小支撑树。
- 但是,由Cayley公式:由n个互异的顶点组成的完全图,共有
 棵支撑树。即便忽略构造所有支撑树的成本,仅为更新最低成本的记录就需要
棵支撑树。即便忽略构造所有支撑树的成本,仅为更新最低成本的记录就需要 时间。
时间。
- 但是,由Cayley公式:由n个互异的顶点组成的完全图,共有
事实上,基于PFS搜索框架,并采用适当的顶点优先级更新策略,就能得出如下高校的最小支撑树的构造算法。
9.2 prim算法(普里姆算法)
割:
图G = (V; E)中, 顶点集V的 任一非平凡子集U 及其 补集V\U 都构成G的一个割(cut),记作(U : V\U)。
跨越边:
若边uv 满足u∈U且 ,则称作该割的一条跨越边(crossing edge)。因此类边联接于V及其补集之间,故亦形象地称作该割的一座桥( bridge)。
,则称作该割的一条跨越边(crossing edge)。因此类边联接于V及其补集之间,故亦形象地称作该割的一座桥( bridge)。
- 最短跨越边:在跨越边中其权重最小(大(视情况而定))的为最短跨越边。
prim算法的正确性基于:
最小支撑树总是会采用连接于每一割的最短跨越边。
证明:(这里采用反证法)  |
|---|
prim算法思想:
由以上性质,可基于贪心策略导出一个迭代式算法。
- 每一步迭代之前,假设已经得到最小支撑树T的一棵子树
 。
。- 其中:
 包含(n-1)条边。
包含(n-1)条边。
- 其中:
- 于是,若将
 及其 补集 视作原图的一个割,则在找到该割的最短跨越边
及其 补集 视作原图的一个割,则在找到该割的最短跨越边 之后,即可扩展为一颗更大的子树
之后,即可扩展为一颗更大的子树 。
。- 其中

- 其中
- 最初的T不含边,而仅含单个顶点,故可从原图的顶点中任意选取。
9.2 kruskal算法(克鲁斯卡尔算法)
普里姆(Prim)算法是以某顶点为起点,逐步找各顶点上最小权值的边来构建最小生成树的。
这就像是我们如果去参观某个展会,例如世博会,你从一个入口进去,然后找你所在位置周边的场馆中你最感兴趣的场馆观光,看完后再用同样的办法看下一个。
现在我们来换一种思考方式,可我们为什么不事宪计划好,进园后直接到你最想去的场馆观看呢?事实上,去世博园的观众,绝大多数都是这样做的。
同样的思路,我们也可以直接就以边为目标去构建,因为权值是在边上,直接去找最小权值的边来构建生成树也是很自然的想法,只不过构建时要考虑是否会形成环路而已。此时我们就用到了图的存储结构中的边集数组结构。以下是edge 边集数组结构的定义代码:
typedef struct{int begin;int end;int weight;}Edge;
krusal算法将每个顶点视作一棵树,并将所有边按权重非降排序,依次考查各边,只要其端点分属于不同的树,则引入该边,并将端点所分别归属的树合二为一,如此迭代,累计已引入n−1条边时,即得到一棵最小生成树。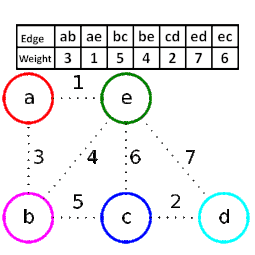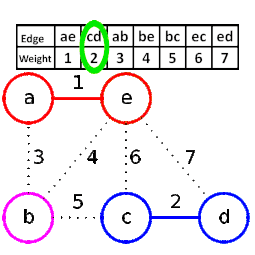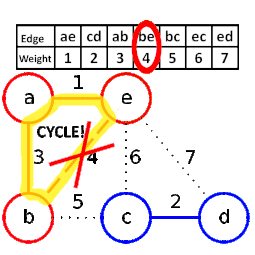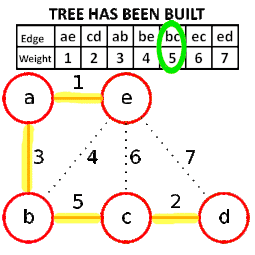
krusal算法生成最小数的动态图
#ifndef DSACPP_GRAPH_KRUSKAL_H_#define DSACPP_GRAPH_KRUSKAL_H_/*参考于:《大话数据结构》P251*/#include "GraphMatrix.h" //邻接矩阵//对边集数组Edge结构定义typedef struct{int begin;int end;int weight;}Edge;template<class Tv, class Te>void bubbleSort(GraphMatrix<Tv, Te> G) /*邓俊辉《数据结构》P5*/{bool sorted = false; //整体排序壁纸,首先假定尚未排序int n1 = G.E.size();while (sorted){sorted = true; //假定已经排序for (int i = G.E; i < n1; i++){if (G.E[i] > G.E[i+1]){swap(G.E[i], G.E[i + 1]);sorted = false;}}n1--; //此时,末尾元素必然就位,所以可以缩短待排序序列的长度}}int Find(int* parent, int f) /*查找 连线顶点 的尾部下标*/{while (parent[f] > 0){f = parent[f];}return f;}template<class Tv, class Te>void MiniSpanTree_Krusal(GraphMatrix<Tv,Te> G){int n, m;Edge edges[G.e_]; //定义边集数组(它的数组长度应不小于原图G的边数)int parent[G.n_]; //定义 数组用来判断边与边是否形成环路bubbleSort(G); //将邻接矩阵转化G为边集数组edges,并按权由小到大排序(在这里选择 冒泡排序)for (int i = 0; i<G.n_; i++){parent[i] = 0; //将数组元素初始化为0}for (int j = 0; j < G.e_; j++){n = Find(parent, edges[j].begin);m = Find(parent, edges[j].end);if (n != m) //假如n与m不等,说明此边没有与现有生成树形成环路{parent[n] = m; //将此边的结尾顶点放入下标为起点的parent中,表示此顶点已经在生成树集合中}}}#endif
算法具体描述过程:
其中,主要的就是如何判断 是否构成环路。
复杂度:
此算法的Find函数由边数e决定,时间复杂度为O(loge),而外面的for循环e次,所以,总体时间复杂度为O(eloge)。
对比克鲁斯卡尔算法、普里姆算法:
- 克鲁斯卡尔算法主要针对边来展开,适用于稀疏图;
- 是对于顶点来展开;适用于稠密图。
10 最短路径
若以带权图来表示真实的通讯、交通、物流或社交网络,则各边的权重可代表信道成本、交通运输费用或交往程度。此时我们经常关心的一类问题,可以概括为:
给定有向图G及其中的顶点u和v,找到从u到v的 最短路径 和 长度 即为最短路径问题。
对旅游者来说,最短路径意味着最经济的出行路线,对路由器来说,最短路径意味着最快将数据包传送至指定位置。
其中:
- 第一个顶点u,称作 源点;
- 最后一个顶点v,称作 终点。
10.1 最短路径树
1、单调性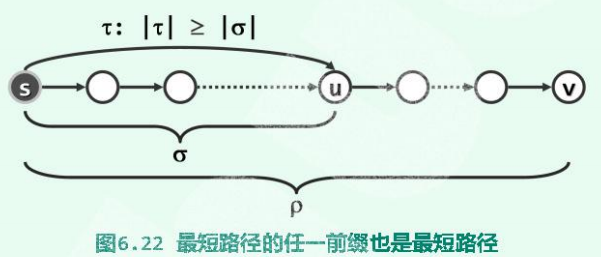
设顶点S至V的最短路径为ρ。则对于该路径上的任意顶点u,若其在ρ上对应的前缀为σ,则σ也是s至u的最短路径(之一)。
2、歧义性
首先,即便各边权重互异,从s到v的最短路径未必唯一。
另外,当存在非正 权重的边,并导致某个环路的总权值非正时,最短路径甚至无从定义。因此,不放假定,带权网络G内各边权重均大于0。
3、无环性
由于其单调性,可知,最短路径(若有不止一条),则每一条最短路径中都不含有任何(有向)回路。
10.2 Dijkstra算法
迪杰斯特拉( Dijkstra ) 算法:是一个按路径长度递增的次序产生最短路径的算法。
地杰斯特拉算法并不是一下子就求出了两个顶点之间的最短路径,而是一步步求出它们之间定点的最短路径,过程中都是基于已经求出的最短路径的基础上,求得更远顶点的最短路径,最终得到你要的结果。
应当注意,绝大多数的戴克斯特拉算法不能有效处理带有负权边的图。
此方法求的是:单源最短路径问题。
10.2.1 算法思想、步骤
问题描述:在无向图 G=(V,E) 中,假设每条边 E[i] 的长度为 w[i],找到由顶点 V0 到其余各点的最短路径。(单源最短路径)
算法思想:
设G=(V,E)是一个带权有向图,把图中顶点集合V分成两组,第一组为已求出最短路径的顶点集合(用S表示,初始时S中只有一个源点,以后每求得一条最短路径 , 就将加入到集合S中,直到全部顶点都加入到S中,算法就结束了),第二组为其余未确定最短路径的顶点集合(用U表示),按最短路径长度的递增次序依次把第二组的顶点加入S中。在加入的过程中,总保持从源点v到S中各顶点的最短路径长度不大于从源点v到U中任何顶点的最短路径长度。此外,每个顶点对应一个距离,S中的顶点的距离就是从v到此顶点的最短路径长度,U中的顶点的距离,是从v到此顶点只包括S中的顶点为中间顶点的当前最短路径长度。
算法描述:
初始时,S只包含源点,即S={v},v的距离为0。U包含除v外的其他顶点,即:U={其余顶点},若v与U中顶点u有边,则
从U中选取一个距离v最小的顶点k,把k,加入S中(该选定的距离就是v到k的最短路径长度)。
以k为新考虑的中间点,修改U中各顶点的距离;若从源点v到顶点u的距离(经过顶点k)比原来距离(不经过顶点k)短,则修改顶点u的距离值,修改后的距离值为 顶点k的距离加上边上的权。
重复步骤2、3直到所有顶点都包含在S中。
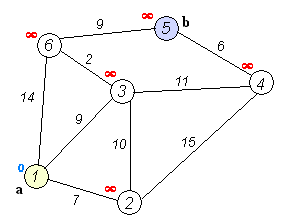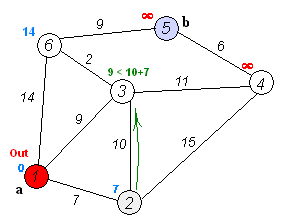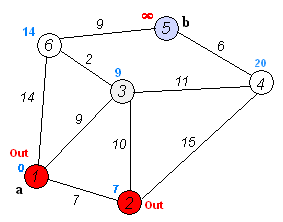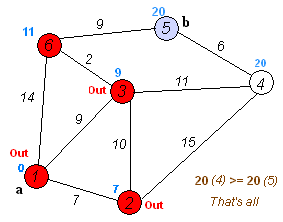
执行动画过程如下图
代码如下:
#ifndef DSACPP_GRAPH_DIJKSTRA_H_
#define DSACPP_GRAPH_DIJKSTRA_H_
#include "Graph.h"
template <typename Tv, typename Te> //最短路径Dijkstra算法:适用于一般的有向图
void Graph<Tv, Te>::dijkstra(int s)
{ //assert: 0 <= s < n
reset(); priority(s) = 0;
for (int i =0; i<n_; i++) //共需引入n个顶点、n-1条边
{
Status(s) = VISITED;
if (parent(s) != -1)
type(parent(s), s); ////引入当前的s
for(int j = firstNbr(s); j>-1; j = nextNbr(s,j)) //枚举s的所有邻居j
if (Status(j) == UNDISCOVERED && priority(j) > (priority(s) + weight(s, j))) //对邻接顶点j做松弛(更新距离(权值))
{////与Prim算法唯一的不同之处
priority(j) = priority(s) + weight(s, j);
parent(j) = s;
}
for (int shortest = INT_MAX, j = 0; j < n_; j++) //选出下一最近顶点
{
if (Status(j) == UNDISCOVERED && shortest > priority(j))
{
shortest = priority(j);
s = j;
}
}
}
} // 对于无向连通图,假设每一条边表示为方向互逆、权重相等的一对边
template <typename Tv, typename Te>
struct DijkstraPU ////针对Dijkstra算法的顶点优先级更新器
{
virtual void operator() (Graph<Tv, Te>* g, int uk, int v)
{
if (UNDISCOVERED == g->status(v)) //对于uk每一尚未被发现的邻接顶点v,按Dijkstra策略
if (g->priority(v) > g->priority(uk) + g->weight(uk, v)) //做松弛
{
g->priority(v) = g->priority(uk) + g->weight(uk, v); //更新优先级(数)
g->parent(v) = uk; //并同时更新父节点
}
}
};
#endif // !DSACPP_GRAPH_DIJKSTRA_H_
10.3 Floyd算法
Floyd-Warshall算法(Floyd-Warshall algorithm)是解决任意两点间的最短路径的一种算法,可以正确处理有向图或负权的最短路径问题,同时也被用于计算有向图的传递闭包。Floyd-Warshall算法的时间复杂度为O(N),空间复杂度为O(N)。
算法描述:
Floyd算法是一个经典的动态规划算法。用通俗的语言来描述的话,首先我们的目标是寻找从点i到点j的最短路径。从动态规划的角度看问题,我们需要为这个目标重新做一个诠释(这个诠释正是动态规划最富创造力的精华所在)
从任意节点i到任意节点j的最短路径不外乎2种可能:
- 直接从
i到j, - 从
i经过若干个节点k到j。
所以,我们假设Dis(i,j)为节点u到节点v的最短路径的距离,对于每一个节点k,我们检查Dis(i,k) + Dis(k,j) < Dis(i,j)是否成立,如果成立,证明从i到k再到j的路径比i直接到j的路径短,我们便设置Dis(i,j) = Dis(i,k) + Dis(k,j),这样一来,当我们遍历完所有节点k,Dis(i,j)中记录的便是i到j的最短路径的距离。
算法描述:
- 从任意一条单边路径开始。所有两点之间的距离是边的权,如果两点之间没有边相连,则权为无穷大。
- 对于每一对顶点 u 和 v,看看是否存在一个顶点 w 使得从 u 到 w 再到 v 比己知的路径更短。如果是更新它。
Floyd算法过程矩阵的计算——十字交叉法**
方法:两条线,从左上角开始计算一直到右下角 如下所示
给出矩阵,其中矩阵A是邻接矩阵,而矩阵Path记录u,v两点之间最短路径所必须经过的点。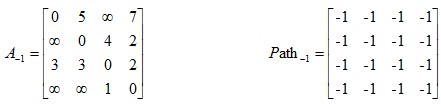
注意:https://blog.csdn.net/qq_22873427/article/details/76432761 先来简单分析下,由于矩阵中对角线上的元素始终为0。因此以k为中间点时,从上一个矩阵到下一个矩阵变化时矩阵的第k行、第k列、对角线上的元素 是不发生改变的(对角线上都是0,因为一个顶点到自己的距离就是0,一直不变;而当k为中间点时,k到其他顶点(第k行)和其他顶点到k(第k列)的距离是不变的)。
因此每一步中我们只需要判断44-34+2=6个元素是否发生改变即可。 也就是要判断既不在第k行第k列又不在对角线上的元素。具体计算步骤如下: 以k为中间点(1)“三条线”:划去第k行,第k列,对角线(2)“十字交叉法”:对于任一个不在三条线上的元素x,均可与另外在k行k列上的3个元素构成一个2阶矩阵,x是否发生改变与2阶矩阵中不包含x的那条对角线上2个元素的和有关,若二者之和小于x,则用它们的和替换x,对应的Path矩阵中的与x相对应的位置用k来替代**。**
**
相应计算方法如下:
最后,求得A3。
其实,其核心还是:
typedef struct
{
char vertex[VertexNum]; //顶点表
int edges[VertexNum][VertexNum]; //邻接矩阵,可看做边表
int n,e; //图中当前的顶点数和边数
}MGraph;
void Floyd(MGraph g)
{
int A[MAXV][MAXV];
int path[MAXV][MAXV];
int i,j,k,n=g.n;
for(i=0;i<n;i++)
for(j=0;j<n;j++)
{
A[i][j]=g.edges[i][j];
path[i][j]=-1;
}
for(k=0;k<n;k++)
{
for(i=0;i<n;i++)
for(j=0;j<n;j++)
if(A[i][j]>(A[i][k]+A[k][j]))
{ A[i][j]=A[i][k]+A[k][j];
path[i][j]=k;
}
} }

若有收获,就点个赞吧
0 人点赞
