1 概念
比如,联接于各公交站之间的街道、互联网中,联接于IP节点之间的路由、等等。这种信息往往可以表述为定义于一组对象之间的二元关系。
相互之间存在二元关系的一组对象,从数据结构的角度分类,属于 非线性结构(non-linear structure)。这属于图论(graph theory)的研究范畴。
1.1 无向图、有向图、混合图:
- 图:可定义为
 。其中,
。其中,- 集合V中的元素称为 顶点(或 节点);【V一定是非空集合】
- 集合E中的元素分别对应于V中的某一对顶点
 。它们之间存在的某种关系,称作边(edge)。
。它们之间存在的某种关系,称作边(edge)。
- 无向图(undirected edge):边所对应的的顶点u和v之间次序无所谓。
- 如:表示同学关系的边。
若E中各边均**无**方向,则G为无向图。
- 如:表示同学关系的边。
- 有向图(directed edge):反之则为有向图。
- 如:程序中函数相互调用的关系。
若E中各边均**有**方向,则G为有向图。
- 如:程序中函数相互调用的关系。
约定:有向边是从u指向v。其中
- u称作该边的起点(origin)或尾顶点(tail);
- v称作该边的终点(destination)或头顶点。
- 混合图(mixed graph):E中的边既有有向边、也有无向边。
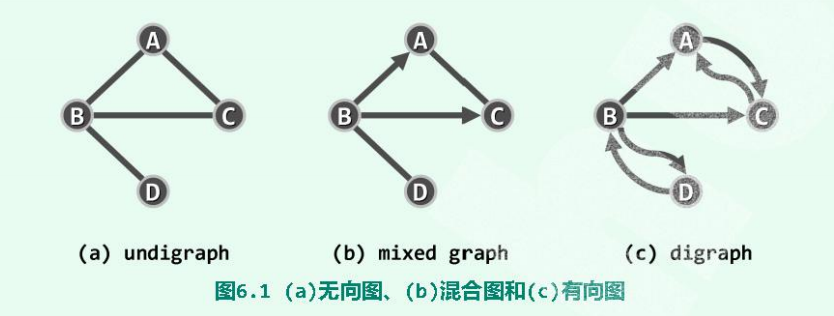
相对而言,有向图的通用性更强,因为 无向图、混合图 均可以转化为 有向图。
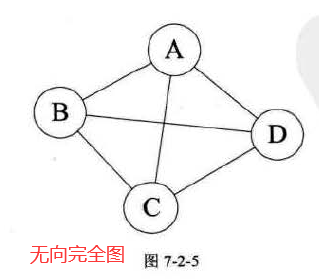
1.1.1 无向完全图
在无向图中,如果任意两个顶点之间都存在边,则为 无向完全图。
- 含有n个顶点的无向完全图有
 条边。
条边。
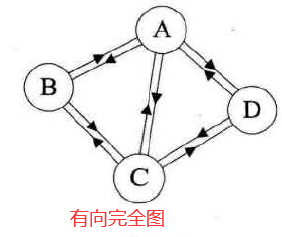
1.1.2 有向完全图
在有向图中,如果任意两个顶点之间都存在方向互为相反的两条弧,则称该图为 有向完全图。
- 含有n个顶点的有向完全图有
 条边。
条边。
1.1.3 稀疏图、稠密图
有很少条边(弧)的图称为 稀疏图;反之为 稠密图。
1.2 度
对于任何边 e=(u , v),称作顶点u和v彼此邻接(adjacent),互为邻居;而他们都与边e彼此关联(incident)。
无向图中:
与顶点v关联的边数称作 v的度数(degree),记作 deg(v)。
如上图中,6.1(a),顶点 {A , B, C, D}的度数分别为 {2,3,2,1}
有向图中:
有向边e=(u , v),e称作u的**出边、v的**入边。
- v的出边总数 称作其 出度(out-degree),记作outdeg(v);
- v的入边总数 称作其 入度(out-degree),记作indeg(v);
在图6.1(c)中个顶点的出度为{1,3,1,1};入度为{2,1,2,1}
1.3 简单图、多重图
自环(self-loop):若一条边的两个顶点为同一顶点,则此边称作自环。
不含任何自环的图称为 简单图(simple graph)。
通路 与 环路
通路或路径**:由m+1个顶点 与 m条边交替形成的一个序列: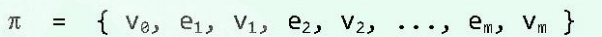
且对于任何  都有
都有 。也就是说,这些边依次首尾相连。其中沿途的边的总数为m,称作通路的长度,记作:
。也就是说,这些边依次首尾相连。其中沿途的边的总数为m,称作通路的长度,记作: 。
。
为简化描述,可以只给出通路中沿途的顶点,而省略连接于其间的边,即: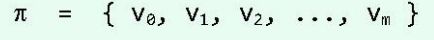
简单通路:通路上的 边 必须互异,但是 顶点 却 可能重复 的通路称为 简单通路。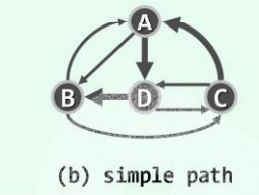
{C, A, B, D}即为:从顶点C到B的一条简单通路, 长度为3
环路(cycle):对于长度 m≥1 的通路π,若 起、止 顶点相同(即 ) ,则称作环路。
) ,则称作环路。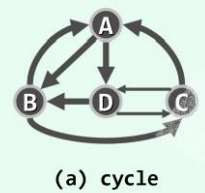
{C, A, B, C}是一条环路,长度为3
有向无环图(directed acyclic graph,DAG):该图中不含任何环路。
简单环路:在环路中,当 沿途中除了外,所有的**顶点**均互异,则称作简单环路。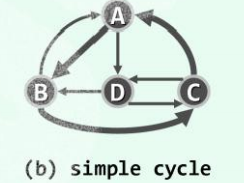
{C, A, B, C}也是一条简单环路,长度为3
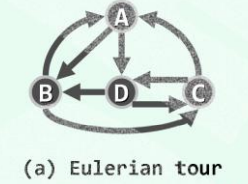
欧拉环路(Eulerian tour):经过图中 各边一次且恰好一次的环路,称为 欧拉环路。
所以,它的长度也恰好等于 边的总数e。

哈密尔顿环路(Hamiltonian tour):经过图中 各顶点一次且恰好一次的环路。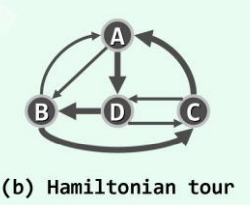
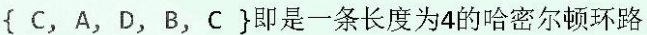
多重图
—图G中某两个结点之间的边数多于 一条,又允许顶点通过同一条边和自己关联, 则G为多重图。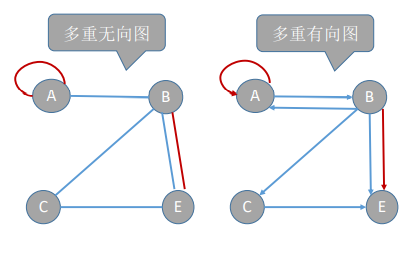
1.4 带权网络
为每一条边e指定一个权重(weight),比如wt(e)是边e的权重。
各边均带有权重的图,称作 带权图(weigthed graph) 或 带权网络(weighted network),
- 有时也简称 网络,
- 记作

含有n个顶点的图中,至多可能包含多少条边?
- 无向图中,每一对顶点至多贡献一条边,总共不超过: n(n-1)/2,且这个上界由 完全图 达到。
- 有向图中,每一对顶点都可能贡献(互逆的)两条边,因此至多有:n(n-1) 条边。
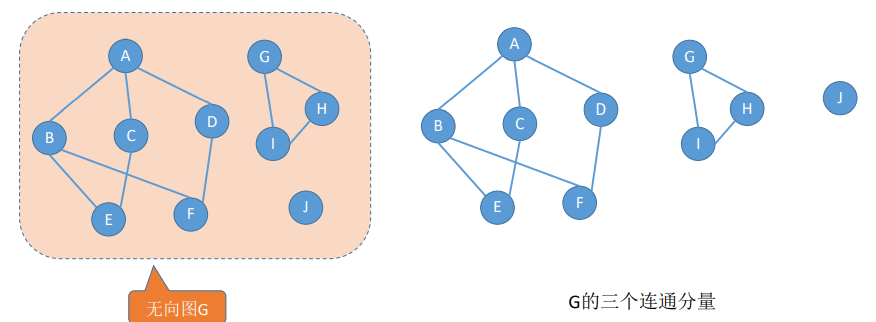
1.5 连通图
在无向图G中,如果从顶点A到顶点B有路径,则称A和B是联通的。
图中任意两个顶点 ,
, 都是连通的,则称G是连通图(connected graph)。如果此图是有向图,则称为强连通图(注意:需要双向都有路径)。
都是连通的,则称G是连通图(connected graph)。如果此图是有向图,则称为强连通图(注意:需要双向都有路径)。
无向图中的极大连通子图称为连**通分量**。注意连通分量的概念,他强调:
- 要是子图;
- 子图是连通的;
- 连通子图含有极大顶点数;
- 具有极大顶点数的连通子图包含依附于这些顶点的所有边。
有向图的极大强连通子图称作有向图的强连通分量。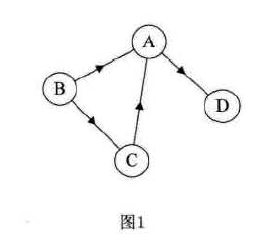
非强连通图(因为D→A不存在路径)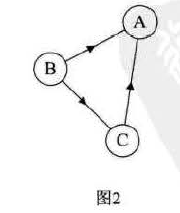
强连通图【也是图1的 极大强连通子图,即是图1的 强连通分量】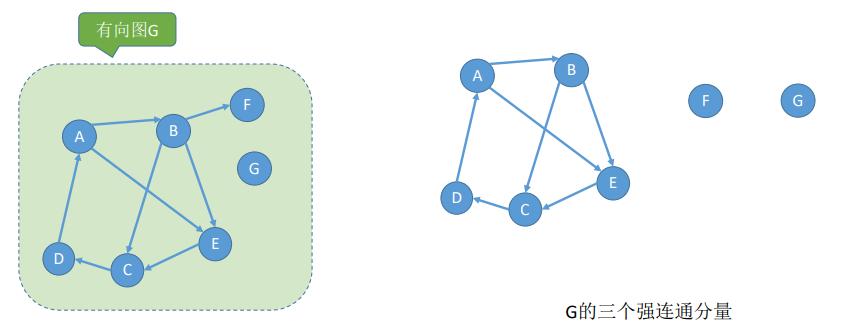
1.6 子图
设有两个图G = (V, E)和G′ = (V′, E′),若V′是V的子集,且E′是 E的子集,则称G′是G的子图。
若有满足V(G′) = V(G)的子图G′,则称其为G的生成子图。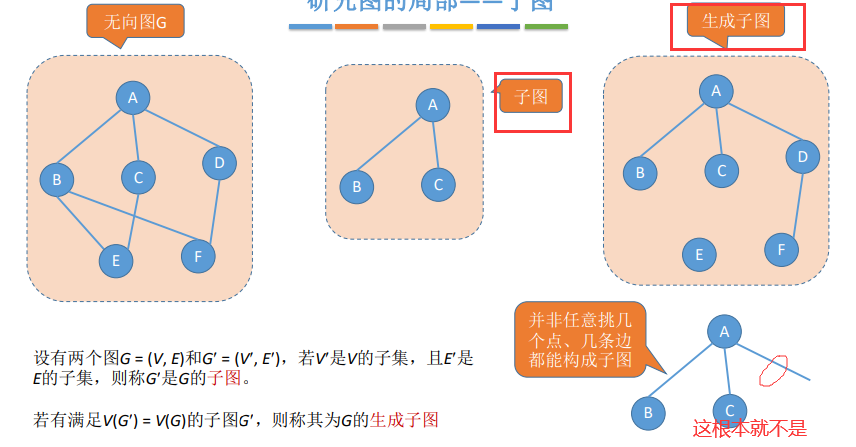
1.7 生成树、生成森林
连通图的生成树:是包含图中全部顶点的一个**极小连通子图**。
- 若图中顶点数为n,则它的生成树含有 n-1 条边。对生成树而言,若砍去它的一条边,则会变成非连通图,若加上一条边则会形成一个回路。
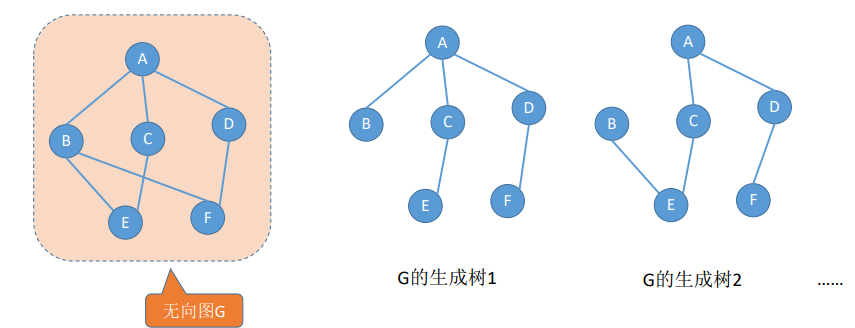
在非连通图中,连通分量的生成树构成了 非连通图的**生成森林**。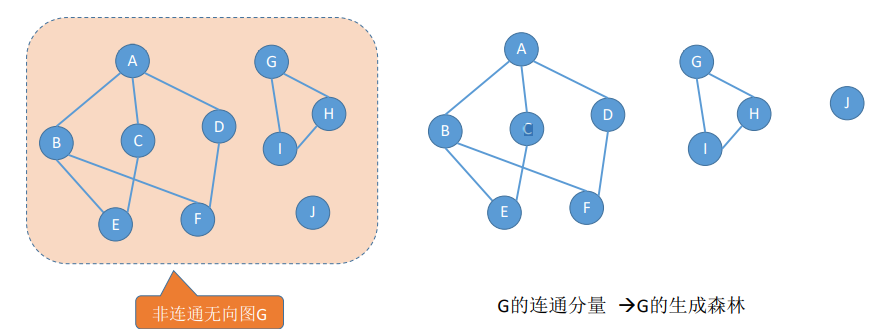
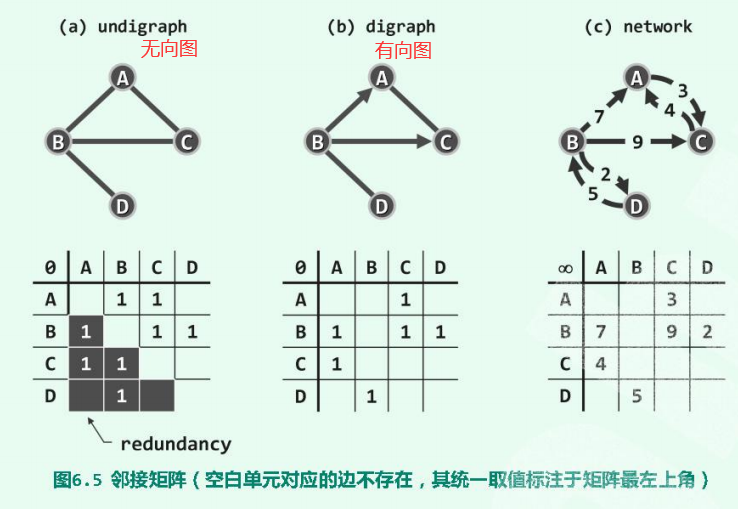
2 邻接矩阵
两个顶点之间 有连接边,则称 该两点之间存在 邻接关系。
具有邻接关系的,顶点与该边 之间的关系是 关联关系。
邻接矩阵(adjacency matrix),使用 方阵 表示由n个顶点构成的图, 其中每个单元,各自负责描述一堆顶点之间可能存在的邻接关系。
表示由n个顶点构成的图, 其中每个单元,各自负责描述一堆顶点之间可能存在的邻接关系。
- 对于无权图,存在(不存在)从u到v的边,当且仅当 A[u][v] = 1(0)。
- 对于带权图,每个单元格表示该边的权值。
- 对于不存在的边,通常取值为
 或者0
或者0
- 对于不存在的边,通常取值为
实现:
template <typename Tv> struct Vertex { //顶点对象(为简化起见,并未严格封装)Tv data; int inDegree, outDegree; VStatus status; //数据、出入度数、状态int dTime, fTime; //时间标签int parent; int priority; //在遍历树中的父节点、优先级数Vertex ( Tv const& d = ( Tv ) 0 ) : //构造新顶点data ( d ), inDegree ( 0 ), outDegree ( 0 ), status ( UNDISCOVERED ),dTime ( -1 ), fTime ( -1 ), parent ( -1 ), priority ( INT_MAX ) {} //暂不考虑权重溢出};typedef enum { UNDISCOVERED, DISCOVERED, VISITED } VStatus; //顶点状态typedef enum { UNDETERMINED, TREE, CROSS, FORWARD, BACKWARD } EType; //边在遍历树中所属的类型template <typename Te> struct Edge { //边对象(为简化起见,并未严格封装)Te data; int weight; EType type; //数据、权重、类型Edge ( Te const& d, int w ) : data ( d ), weight ( w ), type ( UNDETERMINED ) {} //构造};template <typename Tv, typename Te> //顶点类型、边类型class GraphMatrix : public Graph<Tv, Te> { //基于向量,以邻接矩阵形式实现的图private:Vector< Vertex< Tv > > V; //顶点集(向量)Vector< Vector< Edge< Te > * > > E; //边集(邻接矩阵)public:GraphMatrix() { n = e = 0; } //构造~GraphMatrix() { //析构for ( int j = 0; j < n; j++ ) //所有动态创建的for ( int k = 0; k < n; k++ ) //边记录delete E[j][k]; //逐条清除}};
2.1 时间复杂度
| 判断两点之间是否存在联边 | O(1) |
|---|---|
| 获取顶点的出/入度数 | O(1) |
| 添加、删除边后更新度数 | O(1) |
由于向量循秩访问的特点,所有静态操作接口,均只需常数时间。边的静态操作和动态操作也只需常数时间,代价是邻接矩阵的空间冗余。
缺点:但是顶点的动态操作非常耗时,为了插入新的顶点,顶点集向量需添加一个元素,边集向量也需要添加一行,且每行都需要添加一个元素。
2.2 空间复杂度
空间复杂度为 ,与边数无关。
,与边数无关。
对于无向图,有改进的空间,无向图的邻接矩阵必为对称矩阵,其中除了自环以外的每条边,都被重复地存放了两次。可以采用压缩技术,进一步提高空间利用率。
2.3 关联矩阵
记录顶点与边的关系。
n行:有n个顶点;
e列:有e条边;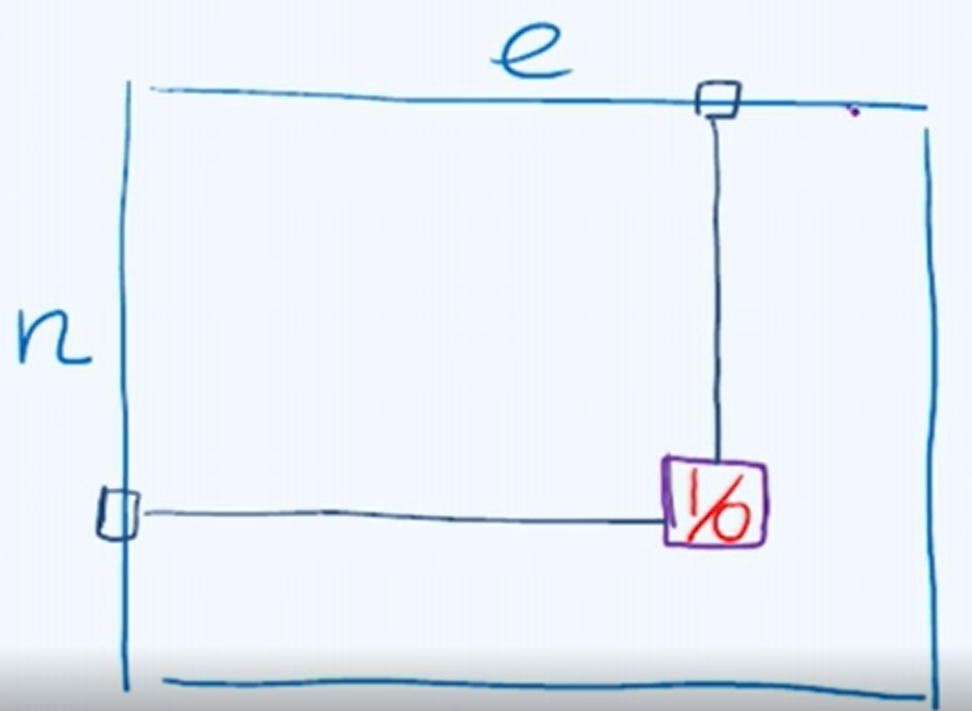
顶点与边之间有关联,则为1;否则为0;
每一列恰好只有两个单元的数值为1(因为一个边与 两个顶点有关联)
空间复杂度为

基于关联矩阵,可以将差分约束系统转换为有向带权图,将差分约束变量视作顶点,将差分约束矩阵视为关联矩阵,如此一来,原问题转换为了有向带权图的最短路径问题。
3 邻接表
上面已经说过,在无向图中,使用邻接矩阵,会浪费很多空间。
而即便就是 有向图,的空间也有改进的余地。实际应用中所处理的图,所含的边通常远少于。
- 如在 “平面图”之类的稀疏图中,边数渐进的不超过
 ,仅与顶点总数大致相当【证明:习题[6-3]】
| 这里使用的欧拉公式:
,仅与顶点总数大致相当【证明:习题[6-3]】
| 这里使用的欧拉公式:
 |
| —- |
|
| —- |
所以,邻接矩阵的空间效率之所以很低,是因为其中大量单元所对应的的边,通常并未在图中出现。
为了改进空间的利用率,可以:类似于关联矩阵的思路,将关联矩阵组织的各行组织为列表,只记录存在的边。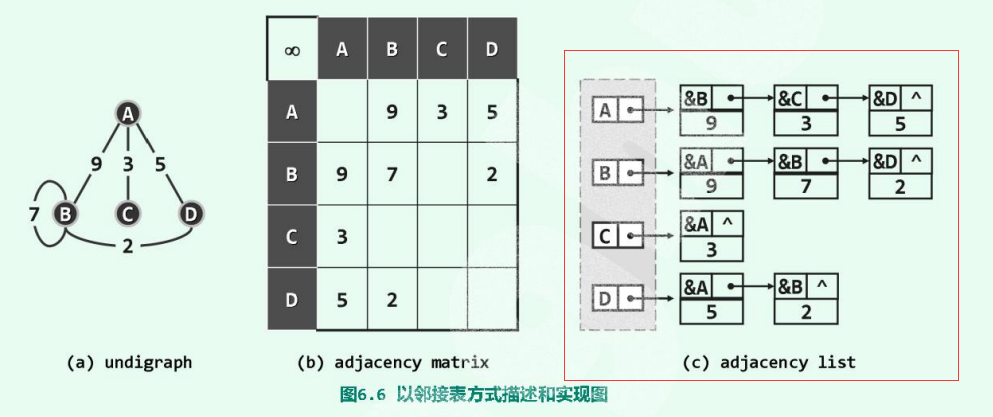
我们将邻接矩阵,逐行的转换为邻接表(上图C),即可分别记录个顶点的关联边(或 邻接顶点)。
3.1 时间复杂度
| 建立邻接表 | O(n+e) |
|---|---|
| 枚举从v出发的边 | O(1+deg(v)) |
| 枚举顶点v的邻居(无向图) | O(1+deg(v)) |
| 枚举到v的边 | O(n+e) |
3.2 空间复杂度
有向图=O(n+e)
无向图=O(n+2e)=O(n+e)
4 邻接矩阵、邻接表适用场景
用邻接矩阵还是邻接表来表示图,取决于以下原则:
- 空间/速度
- 顶点类型
- 弧类型(方向/权值)
- 图类型(稠密图)
| 邻接矩阵 | 邻接表 |
|---|---|
| 经常检测边的存在 | 经常计算顶点的度数 |
| 经常做边的插入/删除 | 顶点数目不确定 |
| 图的规模固定 | 经常做遍历 |
| 稠密图 | 稀疏图 |
5 图的遍历算法
图算法是个庞大的家族,其中大部分成员的主体框架,都可归结于图的遍历。
图的遍历 可理解为:将非线性结构 转化为 半线性结构的过程。
经遍历而确定的边类型中,最重要的一类即所谓的树边,它们与所有顶点共同构成了原图的一棵支撑树(森林),称作遍历树(traversal tree)。
图的遍历更加强调对处于特定状态顶点的甄别与查找,故也称为“图搜索(graph search)”。
5.1 广度优先搜索(遍历)
广度优先搜索(breadth-first search,BFS)采用的策略:
越早被访问到的顶点,其邻居越优先被选用
- 于是,始自图中的顶点S的BFS搜索,将首先访问其顶点S,在依次访问S所有尚未访问到的邻居;
- 再按照后者被访问的先后次序,逐个访问它们的令居;……;如此不断。

实际上,图的广度优先遍历=树的层次遍历
在所有已访问到的顶点中,仍有邻居尚未访问者,构成所谓的波峰集(frontier)。
- 反复从波峰集中找到最早被访问到的顶点v,若其令居均已被访问,则将其逐出波集;否则,随意选出一个尚未访问到的邻居,并将其加入到波峰集中。
- 波峰集内顶点的深度始终相差不超过1;
实例:
代码:
template <typename Tv, typename Te> //广度优先搜索BFS算法(全图)void Graph<Tv, Te>::bfs ( int s ) { //assert: 0 <= s < nreset(); int clock = 0; int v = s; //初始化do //逐一检查所有顶点{if ( UNDISCOVERED == status ( v ) ) //一旦遇到尚未发现的顶点BFS ( v, clock ); //即从该顶点出发启动一次BFS}while ( s != ( v = ( ++v % n ) ) ); //按序号检查,故不漏不重}template <typename Tv, typename Te> //广度优先搜索BFS算法(单个连通域)void Graph<Tv, Te>::BFS ( int v, int& clock ) { //assert: 0 <= v < nQueue<int> Q; //引入辅助队列status ( v ) = DISCOVERED; Q.enqueue ( v ); //初始化起点while ( !Q.empty() ) { //在Q变空之前,不断int v = Q.dequeue(); dTime ( v ) = ++clock; //取出队首顶点vfor ( int u = firstNbr ( v ); -1 < u; u = nextNbr ( v, u ) ) //枚举v的所有邻居uif ( UNDISCOVERED == status ( u ) ) { //若u尚未被发现,则status ( u ) = DISCOVERED; Q.enqueue ( u ); //发现该顶点type ( v, u ) = TREE; parent ( u ) = v; //引入树边拓展支撑树} else { //若u已被发现,或者甚至已访问完毕,则type ( v, u ) = CROSS; //将(v, u)归类于跨边}status ( v ) = VISITED; //至此,当前顶点访问完毕}}
算法的实质功能是由,BFS()完成。对该函数的反复调用,即可遍历所有联通或可达域。
BFS()遍历结束后,所有访问过的顶点通过parent[] 指针依次连接,从整体上给出类原图某一联通或可达域的一棵遍历树,称作 广度优先搜索树,简称 BFS树。
5.1.2 复杂度
空间:除了作为输入的图本身外,BFS搜索使用的空间,主要消耗在用于维护顶点访问次序的辅助队列、用于记录顶点和边状态的标识位向量,累计:
时间:
5.2 深度优先搜索(遍历)
深度优先搜索(Depth-First Search,DFS)选取下一顶点的策略可概括为:
优先选取最后一个被访问到的顶点的邻居
如下动画所示:
 于是,从顶点s出发的DFS搜索,将首先访问顶点s,再从顶点s所有未访问到的邻居任取其一,并从ss所有未访问的邻居中任取一个,并从该顶点递归地执行DFS搜索,故各顶点访问的次序类似于树的**先序遍历,而各顶点被访问完的次序,则类似于树的**后序遍历。
于是,从顶点s出发的DFS搜索,将首先访问顶点s,再从顶点s所有未访问到的邻居任取其一,并从ss所有未访问的邻居中任取一个,并从该顶点递归地执行DFS搜索,故各顶点访问的次序类似于树的**先序遍历,而各顶点被访问完的次序,则类似于树的**后序遍历。
template <typename Tv, typename Te> //深度优先搜索DFS算法(全图)void Graph<Tv, Te>::dfs ( int s ) { //assert: 0 <= s < nreset(); int clock = 0; int v = s; //初始化do //逐一检查所有顶点{if ( UNDISCOVERED == status ( v ) ) //一旦遇到尚未发现的顶点DFS ( v, clock ); //即从该顶点出发启动一次DFS}while ( s != ( v = ( ++v % n ) ) ); //按序号检查,故不漏不重}template <typename Tv, typename Te> //深度优先搜索DFS算法(单个连通域)void Graph<Tv, Te>::DFS ( int v, int& clock ) { //assert: 0 <= v < ndTime ( v ) = ++clock; status ( v ) = DISCOVERED; //发现当前顶点vfor ( int u = firstNbr ( v ); -1 < u; u = nextNbr ( v, u ) ) //枚举v的所有邻居uswitch ( status ( u ) ) { //并视其状态分别处理case UNDISCOVERED: //u尚未发现,意味着支撑树可在此拓展type ( v, u ) = TREE; parent ( u ) = v; DFS ( u, clock ); break;case DISCOVERED: //u已被发现但尚未访问完毕,应属被后代指向的祖先type ( v, u ) = BACKWARD; break;default: //u已访问完毕(VISITED,有向图),则视承袭关系分为前向边或跨边type ( v, u ) = ( dTime ( v ) < dTime ( u ) ) ? FORWARD : CROSS; break;}status ( v ) = VISITED; fTime ( v ) = ++clock; //至此,当前顶点v方告访问完毕}
通过显式地维护一个栈结构,动态记录从起始顶点到当前顶点通路上地各个顶点,其中栈顶对应于当前顶点。每当遇到undiscovered状态顶点,并令其入栈,一旦当前顶点的所有邻居都不再处于undiscovered状态,则将其转为visited状态,并令其出栈。
边的分类
每一递归实例中,先将当前节点标记为discovered状态,再递归地对其邻居递归处理,待所有邻居处理完毕之后再将顶点v置为visited状态,便可回溯。
- 若顶点u为
undiscovered状态,则将边(v,u)归纳为树边。并将v记作u的父节点。伺候,便可将u作为当顶点,继续递归的遍历。
- 若顶点u处于
discovered状态,则发现一个有向环路,此时,在DFS遍历树中,u必为v的祖先,应将边(v,u)归纳为后向边。
这里为每个顶点都记录了被发现的顶点和访问完成的时刻,对应的时间 [ dTime(v),fTime(v) ] 称为v的活跃期。
- 对于有向图,顶点v还可能处于
visited状态,此时通过对比v和u活跃期,即可判定v是否为u的祖先,若是,则边(v,u)应为前向边,否则,二者必定来自不同的分支,边(v,u)应归类为跨边。
- 此处需特别注意,无向图只有后向边(不区分),没有跨边和前向边。
顶点v是u的祖先,当且仅当
| 先证明仅当,若vv为uu的祖先,则遍历过程的次序应该是
1. v被发现
1. u被发现
1. u访问完成
1. v访问完成
也就是说,uu的活跃期包含于vv的活跃期中,在任一顶点刚被发现的时候,其每个后代顶点uu都应处于undiscovered状态。
反之,若u包含于v的活跃期中,则意味着当u被发现 (由undiscovered状态转入discovered状态),v应该正处于discovered状态。因此,v既不可能与u处于不同的分支,又不可能是u的后代,故当亦成立。
由以上分析可进一步看出,此类顶点活跃期之间是严格的包含关系。> v**和u无承袭关系,当且仅当二者的活跃期无交集**
当必然成立,只需证明仅当
考察没有承袭关系的顶点v和u,不妨设 ,则
,则
若不然 ,则意味着当u被发现时,v应该仍处于
,则意味着当u被发现时,v应该仍处于discovered状态。此时必然有一条从v到u的路径,沿途的节点都处于visited状态,在DFS的函数调用栈中,沿途各节点依次分别存有一帧。在DFS树中,该路径上的每一条边都对应于一对父子节点,故说明u是v的后代,与假设矛盾。> 起始于顶点ss的DFS搜索过程中的某时刻,设当前节点为v,任一顶点u处于discovered状态,当且仅当u来自s通往v的路径沿途,或者等效地,在DFS树中u必定为v的祖先
由条件可知dTime(u)
dTime(u)
由以上规律可知,起始顶点ss既是第一个转入discovered状态的,也是最后一个转入visited状态的,其活跃期贯穿整个DFS算法的始末,在此期间的任何一个时刻,任何顶点处于discovered状态,当且仅当它属于从起始顶点ss到当前顶点vv的通路上。 |
| —- |
综上所述,可用如下图表示:
顶点的活动期:
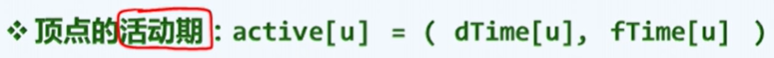

5.2.1 复杂度
空间:
除了原图本身,深度优先遍历算法所使用的的空间:
- 主要消耗于各顶点的时间标签和状态标记,以及各边分类标记。二者累计不超过:

- 另一部分则是直接递归实现方式时,操作系统为维护运行栈还需要耗费一定空间。
为此,我们可以仿照5.4节的做法,通过显示的引入并维护一个栈结构,将DFS改写为迭代版本。
时间:
- 首先需要花费
 的时间对所有顶点和边的状态复位。
的时间对所有顶点和边的状态复位。 - 不计入对子函数DFS()的调用,dfs()本身对所有顶点的枚举共需的时间。
- 不计入DFS()之间的相互递归调用。每一个顶点、每一条边只在子函数DFS()的某一递归实例中消耗
 的时间。
的时间。
累计共需要:的时间。
5.2.2 应用
从顶点s出发的深度优先搜索:
- 在无向图中将访问与s联通的所有顶点
- 在有向图中将访问由s可达的所有顶点 | 联通图的支撑树 | DFS/BFS | | :—- | :—- | | 非联通图的支撑森林 | DFS/BFS | | 联通性检测 | DFS/BFS | | 无向环路检测 | DFS/BFS | | 有向环路检测 | DFS | | 顶点之间可达性检测/路径求解 | DFS/BFS | | 顶点之间的最短距离 | BFS | | 直径 | DFS | | Eulerian tour | DFS | | 拓扑排序 | DFS | | 双联通分量、强联通分量分解 | DFS |

若有收获,就点个赞吧
0 人点赞
