MSE和CE是机器学习中常见的两种损失函数,在训练神经网络中,也经常用到,但是如何深刻地理解二者的异同,却不是容易轻松搞定的。本文从模拟面试的角度尝试对这一问题作出解读。
精灵是一名研二的学生,土木专业,本科数学专业,从读研开始,精灵就已经感觉到自己所学专业就业行情惨淡,但是人工智能却如日中天,各大厂针对应届生开出的薪酬也是让人咂舌。凭着本科扎实的数学功底,精灵开始了人工智能修行之路,无数的挑灯夜战,写代码、调bug、推公式,什么python,什么模型,什么tensorflow,统统拿下!
眼瞅着要找实习了,精灵信心满满地将简历投到了某大厂,一天,电话突然响起:“喂,是精灵吗?我是某某厂的面试官,现在方便进行电话面试吗?”正在宿舍吃着泡面,盯着屏幕上的epoch不断增长的精灵火速擦了擦嘴,关门关窗,无比激动地开始了自己的电面之旅。
面试官先问了几个简单问题,精灵自然轻松答出来了。终于面试官问到了MSE和CE的区别。
面试官:MSE和CE你熟悉吗?
精灵:熟悉,MSE就是mean square error,CE就是cross entropy。
面试官:没错,是这样的,训练神经网络时,你经常用哪一个?
精灵:如果是回归问题,用MSE,如果是分类问题,一般用CE。(这是一个小坑,先要区分问题是分类还是回归,面试官故意模糊这一点,就是考察精灵是否清楚这样的细节)
面试官:为什么呢?
精灵:因为MSE容易发生梯度消失问题,而CE则不会。
面试官:为什么呢?
精灵:以分类问题为例,假设我们的类别数量是T,最后一层使用softmax。对一条样本(x,c)而言,其label为c。在神经网络softmax之前那一层,共有T个神经元,让我们将目光投向第c个神经元,如下图所示:

不管是用MSE还是CE,我们都是希望y_c越大越好,其他与其并列的神经元越小输出值越好。
如果是MSE,这条样本的误差是:
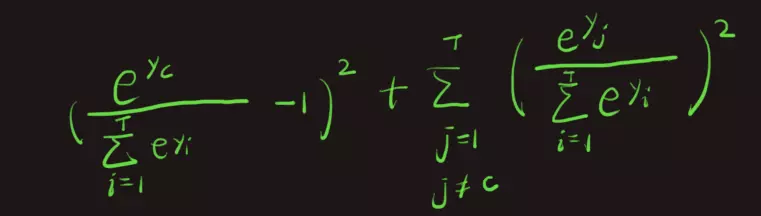
我们来分析这个误差对于参数w的梯度。上式中一共有T项,我们不妨先取出其中一项,比如第一项来分析:
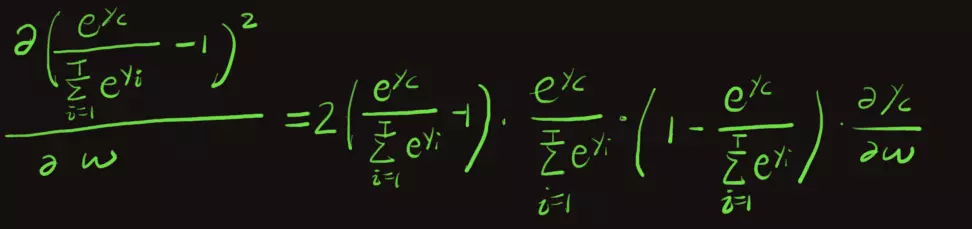
这里,我省略了其中的推导过程,相信面试官您也能理解。观察这个式子,我们发现了一个尴尬的问题,我们是想调整参数w从而增大这一项,使它尽可能接近于1:
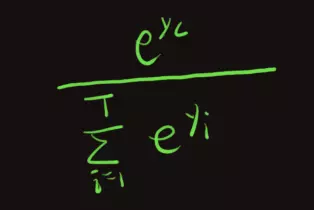
可当这一项接近于0时,上面的梯度也将接近于0,因为该值就是梯度的一个因子。这就是gradient vannishing。
如果是用CE,则不会出现这个问题,用CE,其损失为:
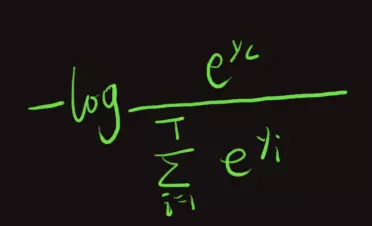
同样我们求该损失对w的梯度:
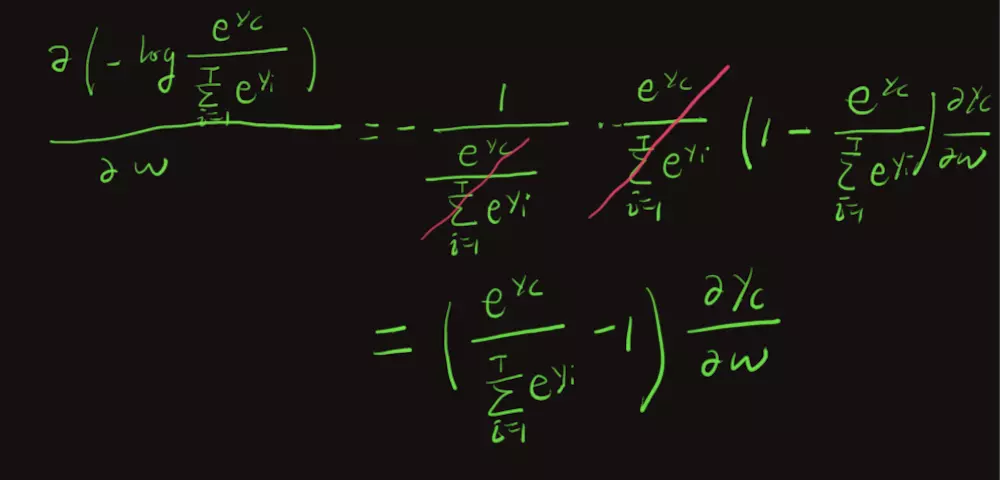
此时,我们发现,该梯度就不会发生gradient vanishing了。因为消去了导致梯度错误消失的因子。
可见,因为我们最后做了softmax,所以用CE会比MSE好。
面试官:不错!分析的很到位!就你了,明天来公司上班吧!
精灵:好嘞!
Note:写完后才发现文章中有一重大bug,不知道你看出来了没有?如果你觉得文章不错,点赞和转发就是最大的支持!

若有收获,就点个赞吧
0 人点赞
