在深度学习中,我们有许多优化器可以选择,但是只有清楚了它们的原理才能更好地选择。
1、SGD
随机梯度下降是最经典的方法,其思想如下图所示: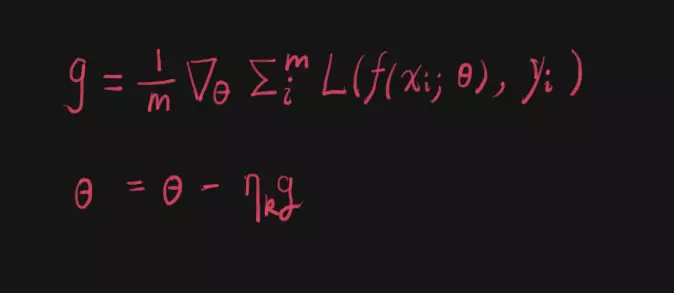
相信大家都很容易理解。
首先求出m个样本的Loss的和,求这个和对于神经网络参数theta的梯度,并将该梯度除以样本数m,得到平均梯度。然后,利用反向梯度来更新参数theta。
η_k是学习率,k表示第k次迭代更新。通常,学习率会随着k的增大逐渐减小。
其他的优化器,都是在这个基础上修改完善得来的。
2、Momentum
动量优化器如下图所示:
与SGD相比,在更新参数theta时,除了像SGD一样按照本次的反向梯度更新外,还会:
将上次更新的反向梯度乘以系数alpha后也更新到参数theta中。
这相当于:
上次更新时是往前走的,这次更新的梯度算出来是往左走,这变化太剧烈了,所以我们来做个折中,往左前方走。感觉上像是上次更新还带有一定的惯性。
3、Nesterov Momentum
Nesterov Momentum如下图所示:
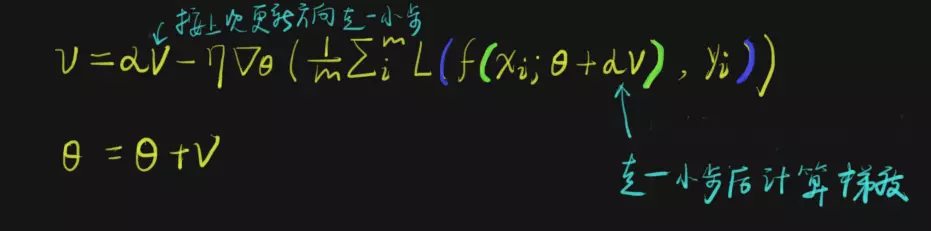
该优化器相对于Momentum,唯一不同的是计算反向梯度的时机。Momentum计算的是当前位置的反向梯度,Nesterov Momentum 计算的是按照上次更新方向走一小步后的反向梯度。
这相当于:
上次是往前走了10米,这次我先往前走上2米,然后再来观察下一步怎么走。可以认为是分两步更新了theta。
4、AdaGrad
AdaGrad相当于增加了一个学习率递减系数:
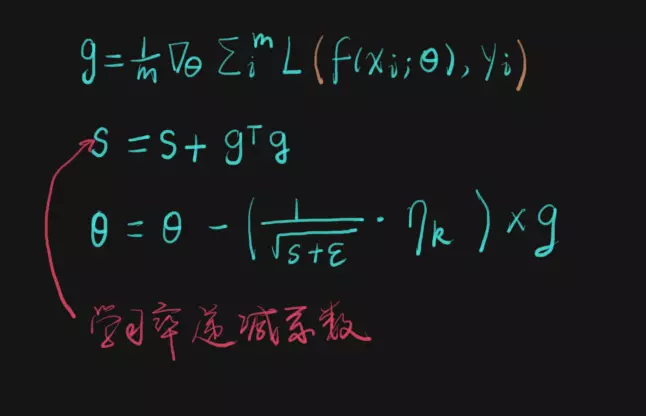
注:上图中的s是历史梯度的平方的和
特殊之处在于这个递减系数由之前所有更新的反向梯度的平方的和来决定。可见,AdaGrad的学习率始终是在减小。
它的优点在于:上图中的theta可以某一个具体的参数,而不是所有参数组成的向量。当theta是某个具体参数时,可以发现,这样计算学习率递减系数相当于:
对于经常更新的参数,我们已经积累了大量关于它的知识,不希望被单个样本影响太大,希望学习速率慢一些;对于偶尔更新的参数,我们了解的信息太少,希望能从每个偶然出现的样本身上多学一些,即学习速率大一些。
但它的问题在于,衰减系数累积了所有更新步骤中的梯度,我们可能更希望考察最近几步中的梯度来决定衰减系数。这就是RMSProp。
5、RMSProp
如下图所示: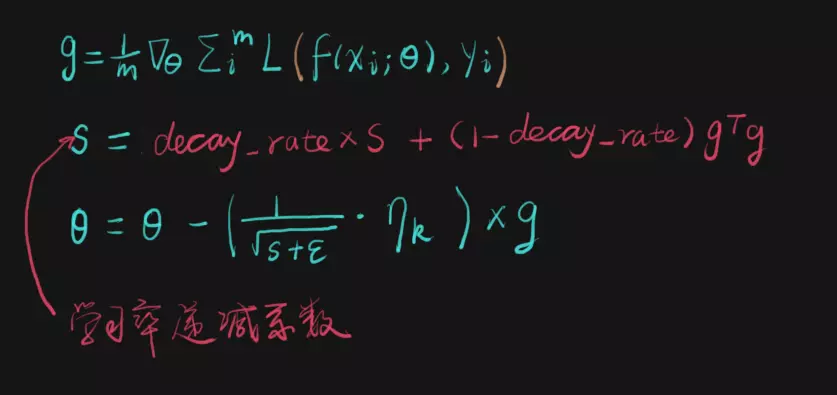
随着更新进行,越早时候计算的梯度对计算衰减系数的影响越小,这种影响的减小速度就是decay_rate的指数衰减速度。
6、Adam
Adam综合了Momentum的更新方向策略和RMProp的计算衰减系数策略,如下图所示: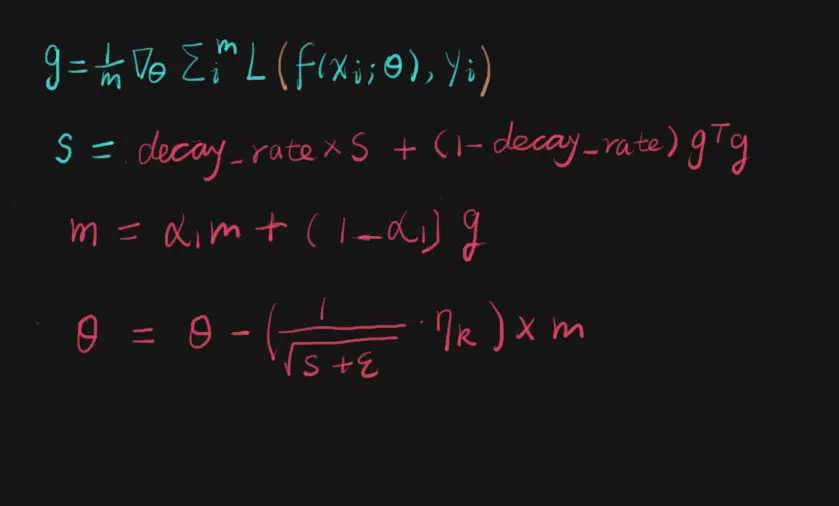
7、总结
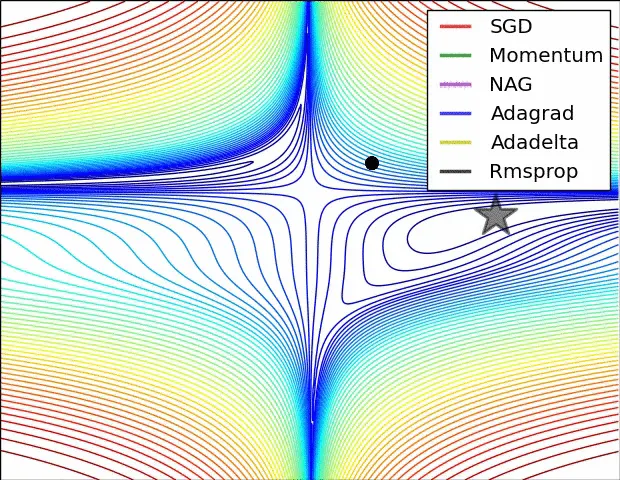
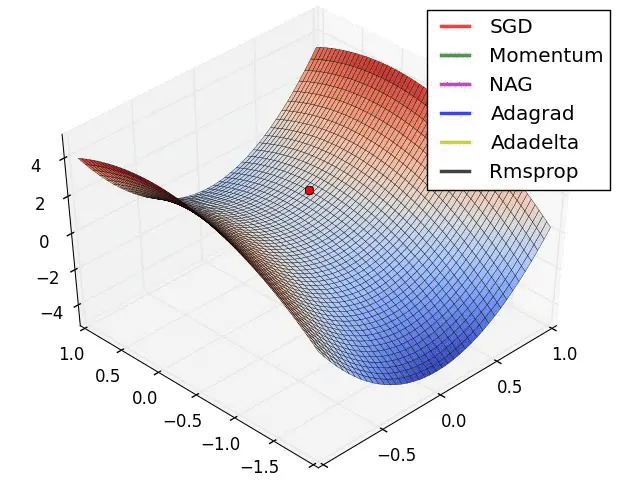
可见,虽然优化器比较多,但是它们之间是有着内在关联的,存在互相借鉴和改进的关系。最后,用图来表示不同的优化器的效果:
简单讲,可分为三大类:
- 改进梯度的:
Momentum是考虑了上次更新时的梯度,Nesterov Momentum是对Momentum的改进
- 改进学习率的:
AdaGrad 根据累积的梯度的和衰减学习率,RMSProp是对AdaGrad的改进
- 同时改进梯度和学习率的:
Adam

若有收获,就点个赞吧
0 人点赞
