生成模型和判别模型是机器学习中两类基本的模型,在机器学习面试中,经常会被问到。能否清晰简明地说明二者的不同,直接影响到面试官对求职者基础知识掌握程度的判断。本文试图给出一个回答,希望大家多多指正。
最近,milter在进行算法工程师的面试,发现面试官特别钟爱生成模型和判别模型相关的问题,为了能够和面试官谈笑风生,milter精心整理了面试官可能问到的相关问题。
1、什么是生成模型和判别模型?
从本质上讲,生成模型和判别模型是解决分类问题的两类基本思路。首先,您得先了解,分类问题,就是给定一个数据x,要判断它对应的标签y(这么naive的东西都要解释下,求面试官此时内心的阴影面积,嘎嘎)。生成模型就是要学习x和y的联合概率分布P(x,y),然后根据贝叶斯公式来求得条件概率P(y|x),预测条件概率最大的y。贝叶斯公式这么简单的知识相信您也了解,我就不啰嗦了。判别模型就是直接学习条件概率分布P(y|x)。
这样政治正确的回答是必须要先说出来的,这都说不出来,面试肯定没戏了。但面试官可不是吃素的,为了判断你不是背的答案,他会继续提出下面的问题。
2、帅哥,举个栗子呗?
有一句名言说的好,没有什么问题是一个妹子例子解决不了的,如果有,那就两个!那我们就来举两个例子!
例子1
假设你从来没有见过大象和猫,连听都没有听过,这时,给你看了一张大象的照片和一张猫的照片。如下所示:

然后牵来我家的大象(面试官:你家开动物园的吗?),让你判断这是大象还是猫。你咋办?
你开始回想刚刚看过的照片,大概记起来,大象和猫比起来,有个长鼻子,而眼前这个家伙也有个长鼻子,所以,你兴奋地说:“这是大象!”恭喜你答对了!
你也有可能这样做,你努力回想刚才的两张照片,然后用笔把它们画在了纸上,拿着纸和我家的大象做比较,你发现,眼前的动物更像是大象。于是,你惊喜地宣布:“这玩意是大象!”恭喜你又答对了!
在这个问题中,第一个解决问题的思路就是判别模型,因为你只记住了大象和猫之间的不同之处。第二个解决问题的思路就是生成模型,因为你实际上学习了什么是大象,什么是猫。
例子2
来来来,看一下这四个形式为(x,y)的样本。(1,0), (1,0), (2,0), (2, 1)。假设,我们想从这四个样本中,学习到如何通过x判断y的模型。用生成模型,我们要学习P(x,y)。如下所示:
我们学习到了四个概率值,它们的和是1,这就是P(x,y)。
我们也可以用判别模型,我们要学习P(y|x),如下所示: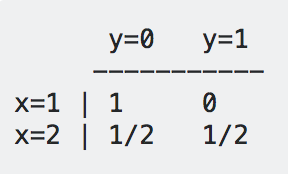
我们同样学习到了四个概率值,但是,这次,是每一行的两个概率值的和为1了。
让我们具体来看一下,如何使用这两个模型做判断。
假设 x=1。
- 对于生成模型, 我们会比较:
P(x=1,y=0) = 1/2
P(x=1,y=1) = 0
我们发现P(x=1,y=0)的概率要比P(x=1,y=1)的概率大,所以,我们判断:x=1时,y=0。
- 对于判别模型,我们会比较:
P(y=0|x=1) = 1
P(y=1|x=1) = 0
同样,P(y=0|x=1)要比P(y=1|x=1)大,所以,我们判断:x=1时,y=0。
我们看到,虽然最后预测的结果一样,但是得出结果的逻辑却是完全不同的。
两个栗子说完,你心里感到很痛快,面试官脸上也露出了赞赏的微笑,但是,他突然问了一个问题。
3、生成模型为啥叫生成模型?
这个问题着实让你没想到,不过,聪明的你略加思考,应该就可以想到。生成模型之所以叫生成模型,是因为,它背后的思想是,x是特征,y是标签,什么样的标签就会生成什么样的特征。好比说,标签是大象,那么可能生成的特征就有大耳朵,长鼻子等等。
当我们来根据x来判断y时,我们实际上是在比较,什么样的y标签更可能生成特征x,我们预测的结果就是更可能生成x特征的y标签。
面试官显然已经基本满意了,这时,只见他轻轻说了句:
4、常见的生成模型和判别模型有哪些呢?
生成模型
经过这四个问题,应该说,可以过关了。
5、无总结,不进步
本文,我们简单分析了生成模型和判别模型的区别和联系,解释过程中,尽量避免了各种数学公式。相信有了现在的知识基础,再去看那些数学公式,你不会再觉得头大了。
下面,给大家留一道思考题:
数据量小时,你会选择哪类模型,为什么?
References:
- 1、https://medium.com/@mlengineer/generative-and-discriminative-models-af5637a66a3
- 2、https://stackoverflow.com/questions/879432/what-is-the-difference-between-a-generative-and-a-discriminative-algorithm
- 3、https://www.quora.com/What-are-the-differences-between-generative-and-discriminative-machine-learning
- 4、https://www.quora.com/Why-are-HMMs-considered-a-generative-model
- 5、https://www.cnblogs.com/fanyabo/p/4067295.html

若有收获,就点个赞吧
0 人点赞
