逻辑回归作为被广泛使用的二分类模型,面试中自然是不可缺少的。但要深刻理解逻辑回归又不是那么容易的,比如说,逻辑回归输出的值是0到1之间的值,这个值是真实的概率吗?逻辑回归为什么要选择sigmoid函数的形式,而不是其他将数值映射到0到1之间的形式?本文试图给出一个尽可能简单明了的分析。
一、从一个例子开始
假设你在一家金融公司工作,老板交给你一个任务,建一个模型,用来预测一个借款人是否会违约,公司拥有一个借款人的特征数据,比如年龄。
将是否违约作为标签变量y,0表示没有违约,1表示违约。在给定特征x的情况下,我们假设 y 是一个服从伯努利分布的二值随机变量。注意,这是我们做的第一个假设哦!从某种意义上讲,模型准不准,首先要看假设合不合理。
我们的任务用数学语言描述就是,寻找一个模型,输入x后,可以告诉我们y所服从的随机分布的参数,知道参数后,就可以计算y的期望作为预测。
具体到违约预测,上面所说的随机分布就是指伯努利分布,该分布的参数就是Φ=P(y=1),同时也是该分布的期望。
请认真体会一下我们的思路:
1、对每一个确定的x,y仍然是一个随机变量
2、该随机变量服从某个随机分布
3、努力求出这个随机分布的参数
4、求出该随机分布的期望
5、将期望作为预测值
二、从更高的层次看待伯努利分布
那么,如何根据x求出y所属的伯努利分布的参数Φ呢。
直接看,似乎没什么思路,我们需要换个角度。
伯努利分布实际上属于某一大类分布中的一种情况。这一大类分布就是指数分布族。
这就好比, x + 1=0是一个方程,但从更广泛的角度来看,它只是 ax + b = 0一次方程的一种具体情况而已。
从指数分布族的角度来分析,我们很容易构建起x与伯努利分布参数的联系。
3、指数分布族
下面,我们就来看看指数分布族是什么样子,如果你是第一次看到它,很可能是这样:
请放轻松,它只是看起来有些复杂,实际上并不难。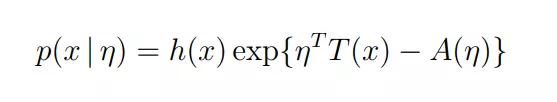
为了简化理解,你可以自动忽略η上面的大写字母T,仅仅将η作为一个实数来理解。
它其实是在告诉我们:
对于一个随机变量x,只要你确定三个函数,就可以确定一类分布。
这三个函数就是:
h(x)
T(x)
A(η)
η用来确定该类分布的具体参数。
对于我们的伯努利分布,这三个函数是什么样子呢?我们可以从伯努利分布出发,一路变形到与指数分布族一样的形式。如下所示:
请认真看看上面的变形推导过程。可以看到,伯努利分布确实可以改写成指数分布族的形式。并且,伯努利分布的参数Φ与η之间,还有一个sigmoid的函数关系。
4、最后一步
现在,我们看到,伯努利分布确实是指数分布族的一个特殊情况,它的参数Φ与指数分布族中的参数η还有对应关系。
这意味着,我们如果能找到x和η之间的关系,那么也就找到了x和Φ之间的关系。
在这里,我们需要再做一个假设,那就是
η和x之间存在线性的关系!!注意,这是我们做的第二个假设哦。即:
η = θx。
有了这个假设,我们的模型训练过程就是这样的:
对一个x,根据 θx算出η
根据η算出Φ
因为Φ既是伯努利分布的唯一参数,也是该分布的期望,所以将Φ作为预测值。
计算Φ与真实的标签y之间的误差loss。(通常用交叉熵)
通过SGD来更新θ,降低loss。
这不就是我们的逻辑回归么?
5 总结
可见,逻辑回归模型之所以是sigmoid 的形式,源于我们假设y服从伯努利分布,伯努利分布又属于指数分布族,经过推导,将伯努利分布变成指数分布族的形式后。我们发现伯努利分布的唯一参数Φ与指数分布族中的参数η具有sigmoid函数关系,于是我们转而求η与x的关系,此时,我们又假设η与x具有线性关系。
至此,找到了我们要用的模型的样子,也就是逻辑回归。
回答文章开头的问题,逻辑回归输出的到底是不是概率呢?答案是如果你的情况满足本文所说的两个假设,那么你训练模型的过程,就确实是在对概率进行建模。
这两个假设并不是那么容易满足的。所以,很多情况下,我们得出的逻辑回归输出值,无法当作真实的概率,只能说是一个近似的概率。

若有收获,就点个赞吧
0 人点赞
