在机器学习的面试中,数据是否需要归一化和标准化是个常见问题。之所以常见,是因为它有很多暗坑,每个暗坑都可以考察应聘者机器学习基础是否扎实。
1、先说是什么,再说为什么
归一化和标准化经常被搞混,程度还比较严重,非常干扰大家的理解。为了方便后续的讨论,必须先明确二者的定义。
- 归一化
就是将训练集中某一列数值特征(假设是第i列)的值缩放到0和1之间。方法如下所示:
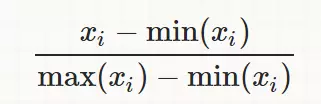
- 标准化
就是将训练集中某一列数值特征(假设是第i列)的值缩放成均值为0,方差为1的状态。如下所示:

- 进一步明确二者含义
归一化和标准化的相同点都是对某个特征(column)进行缩放(scaling)而不是对某个样本的特征向量(row)进行缩放。对特征向量进行缩放是毫无意义的(暗坑1),比如三列特征:身高、体重、血压。每一条样本(row)就是三个这样的值,对这个row无论是进行标准化还是归一化都是好笑的,因为你不能将身高、体重和血压混到一起去!
在线性代数中,将一个向量除以向量的长度,也被称为标准化,不过这里的标准化是将向量变为长度为1的单位向量,它和我们这里的标准化不是一回事儿,不要搞混哦(暗坑2)。
2、 标准化和归一化的对比分析
首先明确,在机器学习中,标准化是更常用的手段,归一化的应用场景是有限的。我总结原因有两点:
1、标准化更好保持了样本间距。当样本中有异常点时,归一化有可能将正常的样本“挤”到一起去。比如三个样本,某个特征的值为1,2,10000,假设10000这个值是异常值,用归一化的方法后,正常的1,2就会被“挤”到一起去。如果不幸的是1和2的分类标签还是相反的,那么,当我们用梯度下降来做分类模型训练时,模型会需要更长的时间收敛,因为将样本分开需要更大的努力!而标准化在这方面就做得很好,至少它不会将样本“挤到一起”。
2、标准化更符合统计学假设
对一个数值特征来说,很大可能它是服从正态分布的。标准化其实是基于这个隐含假设,只不过是略施小技,将这个正态分布调整为均值为0,方差为1的标准正态分布而已。
所以,下面的讨论我们先集中分析标准化在机器学习中运用的情况,在文章末尾,简单探讨一下归一化的使用场景。这样更能凸显重点,又能保持内容的完整性,暂时忘记归一化,让我们focus到标准化上吧。
3、逻辑回归必须要进行标准化吗?
我觉得,回答完上面的问题,就可以很好地掌握标准化在机器学习中的运用。首先,请尝试自己来回答一下,在评论中告诉我你的答案。
(暂停5秒)
无论你回答必须或者不必须,你都是错的!!!哈哈。
真正的答案是,这取决于我们的逻辑回归是不是用正则。
如果你不用正则,那么 ,标准化并不是必须的,如果你用正则,那么标准化是必须的。(暗坑3)
为什么呢?
因为不用正则时,我们的损失函数只是仅仅在度量预测与真实的差距,加上正则后,我们的损失函数除了要度量上面的差距外,还要度量参数值是否足够小。而参数值的大小程度或者说大小的级别是与特征的数值范围相关的。举例来说,我们用体重预测身高,体重用kg衡量时,训练出的模型是:
身高 = 体重*x
x就是我们训练出来的参数。
当我们的体重用吨来衡量时,x的值就会扩大为原来的1000倍。
在上面两种情况下,都用L1正则的话,显然对模型的训练影响是不同的。
假如不同的特征的数值范围不一样,有的是0到0.1,有的是100到10000,那么,每个特征对应的参数大小级别也会不一样,在L1正则时,我们是简单将参数的绝对值相加,因为它们的大小级别不一样,就会导致L1最后只会对那些级别比较大的参数有作用,那些小的参数都被忽略了。
如果你回答到这里,面试官应该基本满意了,但是他可能会进一步考察你,如果不用正则,那么标准化对逻辑回归有什么好处吗?
答案是有好处,进行标准化后,我们得出的参数值的大小可以反应出不同特征对样本label的贡献度,方便我们进行特征筛选。如果不做标准化,是不能这样来筛选特征的。
答到这里,有些厉害的面试官可能会继续问,做标准化有什么注意事项吗?
最大的注意事项就是先拆分出test集,不要在整个数据集上做标准化,因为那样会将test集的信息引入到训练集中,这是一个非常容易犯的错误!
4、归一化的应用场景
有时候,我们必须要特征在0到1之间,此时就只能用归一化。有种svm可用来做单分类,里面就需要用到归一化,由于没有深入研究,所以我把链接放上,感兴趣的可以自己看。
http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.100.2524
5、总结
我们从区分清楚标准化和归一化入手,分析了二者的异同。然后用逻辑回归这个具体的模型来分析了标准化的作用,这是本文的主要目的。最后,简单提了一下归一化的使用场景。
留一个思考题:决策树需要标准化吗,为什么?
答案是:不需要,因为决策树中的切分依据,信息增益、信息增益比、Gini指数都是基于概率得到的,和值的大小没有关系。另外同属概率模型的朴素贝叶斯,隐马尔科夫也不需要标准化。———感谢简书用户https://www.jianshu.com/u/803356d3a2ae的回答。

若有收获,就点个赞吧
0 人点赞
