- 1、为什么需要Estimator
- 2、Estimator框架的整体设计
面向对象,与原有model的兼容 - 3、Estimator框架的组件
##3.1、Layers
这个组件虽然是随Estimator框架一同发布,但它实际上可以独立于Estimator框架使用。它只是又一个方便我们构建模型的tensorflow工具包而已。
深度学习的一大优势就是可以像搭积木一样,用一些基础的组件拼装出我们需要的模型,对这些基础组件进行抽象,就是layer的概念。它实质上只是一段可以复用的代码。
Estimator框架对layer的抽象是,它是一个函数,接收一个tensor(也许还有其他参数),然后输出一个tensor,这与tensorflow中许多的操作是一样的,你可以把它看做是对tensorflow操作的扩展。这样做的优点就是你可以自由地混合使用tensorflow的操作和layer。换句话说,layer是对许多的tensorflow基本操作的抽象。
layer的实现运用了许多最佳实践:
1、layer是一定被包在一个variable_scope中的。这方便我们在tensorboard中查看模型结构,因为同一个variable_scope中的变量,在tensorboard中显示时是可以group在一起的,尤其是当模型比较大的时候,会提供更多的方便。
2、layer中的所有变量都是通过get_variable方法获得的,这使得变量可以在模型的不同部分之间复用或共享。
3、所有的layer都假定输入tensor的第一个维度是batch维度,同时接收一个变量,表示batch的size。这样的好处有两个,一个是在训练时可以动态调整batch的大小,另一个是模型可以直接被用来做inference,此时input可以只是一条数据,你也只需要将batch size设为1就可以了。
如下是一个示例代码,简单的图片分类卷积网络: - 4、分布式执行
最近,google放出了BERT模型的源码,一时间,身边朋友们言必称BERT,纷纷扎入源码研究。可是BERT用的是Estimator这一high level的框架,有的小伙伴不是很熟悉,本文试图从总体的角度对Estimator框架进行一个解析,希望对大家有所帮助。
1、为什么需要Estimator
现在深度学习模型框架有两个极端:
- 一个是极端灵活(Flexibility),给你提供了许多的low level的api,比如mul、add等。好处是你可以自由地定义自己的model,非常适合搞研究,但前提时什么都得你自己搞定,重复代码很多,而且中间充斥着许多你自己定制的模型无关的代码。
- 另一个是极端的定制化,像是一个DSL,对常用的模型,给你规定的死死的,你按它的要求来,就保证可以搞出生产可用的常用模型,非常简单(Simplicity),缺点是不够灵活,尤其是想探索一些新的模型架构时,很麻烦。
Estimator构建在TensorFlow之上,目标是提供一种兼顾灵活性和简单性的模型框架。Estimator这一概念实际上从Scikit-learn借鉴而来,这样便于熟悉Scikit-learn的用户转移到TensorFlow上来。
2、Estimator框架的整体设计
面向对象,与原有model的兼容
3、Estimator框架的组件
##3.1、Layers
这个组件虽然是随Estimator框架一同发布,但它实际上可以独立于Estimator框架使用。它只是又一个方便我们构建模型的tensorflow工具包而已。
深度学习的一大优势就是可以像搭积木一样,用一些基础的组件拼装出我们需要的模型,对这些基础组件进行抽象,就是layer的概念。它实质上只是一段可以复用的代码。
Estimator框架对layer的抽象是,它是一个函数,接收一个tensor(也许还有其他参数),然后输出一个tensor,这与tensorflow中许多的操作是一样的,你可以把它看做是对tensorflow操作的扩展。这样做的优点就是你可以自由地混合使用tensorflow的操作和layer。换句话说,layer是对许多的tensorflow基本操作的抽象。
layer的实现运用了许多最佳实践:
1、layer是一定被包在一个variable_scope中的。这方便我们在tensorboard中查看模型结构,因为同一个variable_scope中的变量,在tensorboard中显示时是可以group在一起的,尤其是当模型比较大的时候,会提供更多的方便。
2、layer中的所有变量都是通过get_variable方法获得的,这使得变量可以在模型的不同部分之间复用或共享。
3、所有的layer都假定输入tensor的第一个维度是batch维度,同时接收一个变量,表示batch的size。这样的好处有两个,一个是在训练时可以动态调整batch的大小,另一个是模型可以直接被用来做inference,此时input可以只是一条数据,你也只需要将batch size设为1就可以了。
如下是一个示例代码,简单的图片分类卷积网络:
# Input images as a 4D tensor (batch , width ,# height , and channels)net = inputs# instantiate 3 convolutional layers with poolingfor _ in range(3):net = layers.conv2d(net, filters=4,kernel_size=3,activation=relu)net = layers.max_pooling2d(net,pool_size=2,strides=1)logits = layers.dense(net, units=num_classes)
Estimator框架将一些有更加严格限制的接口从layer中剥离出来,比如各种Losses,它是一个函数,接收一个input,一个label,一个weight,然后返回一个scalar的 loss。它包含了l1_loss 和l2_loss。
除了Losses这个抽象之外,Metrics是另一个抽象。和Losses一样,它们接受一个label,一个prediction,还有一个可选的weight,然后计算得出一个metric,比如 log-likelihood, accuracy,或者仅仅是一个简单的均方误差。Metrics主要用在Evaluation环节。
Losses 和Metrics有一个共同之处就是,它们都支持跨多个minibatch来聚合loss或者metirc,尤其是当dataset无法装进内存时,这个特性非常有用。Metric返回两个tensor,一个是update_op,看后缀就知道,这是一个操作,用来聚合多个minibatch。当你用这个操作聚合完所有的minibatch后,就可以使用另一个tensor, value_op来获取最终的metric。正确地从零开始实现一个metric并不是一个简单的事情,尤其是当数据集非常大的时候,所以尽可能地用提供好的metric实现是明智的选择。
3.2、Estimator
毫无疑问,该框架的核心就是Estimator类,该类既能方便你将模型部署成服务,又能方便你的开发。之前已经提到,Estimator其实是仿照着Scikit-learn中的Estimator概念实现的。它包含四个方法:
- train
用来根据输入的数据训练模型 - evaluate
用来在测试集上评估模型 - predict
使用训练好的模型在新数据上做推断 - export_savedmodel
导出一个SavedModel,这是一种序列化的模型格式,可以被用在TensorFlow Serving中。TensorFlow Serving是已经实现好的可在生产环境中使用的模型服务器。
当用户创建Estimator时,需要传入一个callback到构造方法中,这个callback就是model_fn。
当构建好Estimator后,你调用上面四个方法中的任一个时,Estimator将会创建TensorFlow 计算图,建立输入数据处理的pipeline。当然,建立pipeline的根据还是你在model_fn中提供的输入数据的信息。有了计算图,有了pipeline,Estimator将会用适当的参数调用model_fn来生成代表模型的计算图。Estimator已经包含了实现train、evaluate、predict、export_savedmodel的必要的代码。
Estimator向用户隐藏了一些大家熟知的TensorFlow中的概念,如Graph、Session。
Estimator的构造方法中还接收一个配置对象,叫RunConfig,这个对象将会告诉Estimator所有它需要了解的运行环境信息,比如,有多少可用的workers,训练多久保存一次checkpoint。
为了确保封装性,每当上述四个方法中的一个被调用时,Estimator都会创建一个新的graph,这个graph有可能是从checkpoint中创建的。这样的实现方法看似很笨,因为重新创建图是一个代价高昂的操作,而且完全可以将graph做缓存,这多经济划算,尤其是在一个循环中调用evaluate或者predict时。但是,框架的作者们认为,明确地重新创建图是在性能和清晰性之间的一个折中。因为即使不重新建图,在循环中调用evaluate、predict等方法都是一种性能极差的操作。明确地创建图,将会阻止用户写出这样糟糕的代码。
下图时Estimator的结构概览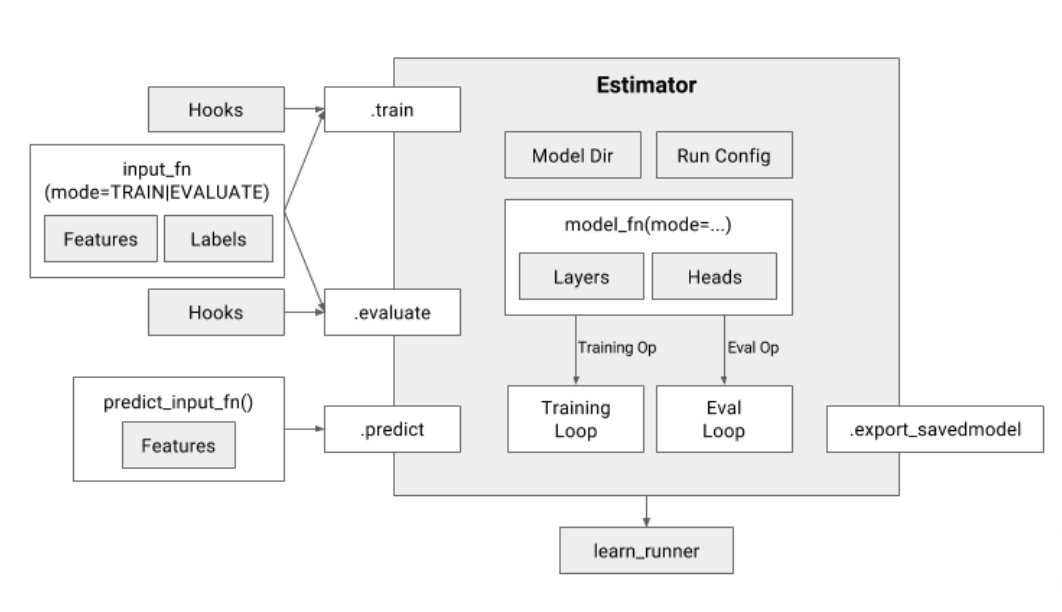
下面,我们将首先介绍如何为train、evaluate和predict方法提供输入,然后,讨论模型如何在model_fn中定制模型,以及如何在里面用Heads来定制输出。
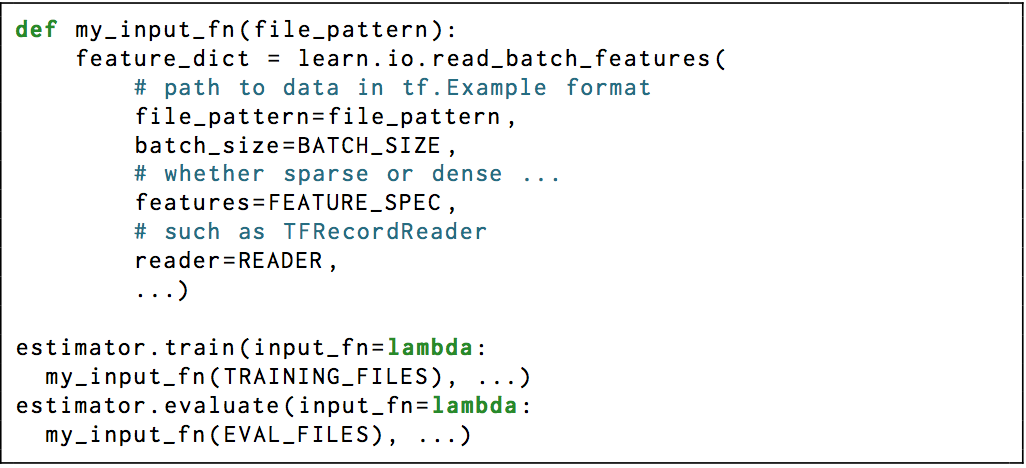
- 1、用input_fn来定制输入。方法train、evaluate和predict都需要提供一个输入函数,该函数将需要产生两个字典,一个包含输入的tensors(在Estimator中成为features);另一个包含labels的tensors。当Estimator的任一个方法被调用时,都会创建一个新的计算图,然后将会调用input_fn创建Estimator的 输入 pipeline。然后,将会调用model_fn,用适当的模型参数来创建真正的模型计算图。从这里可以看出,Estimator有意将输入的处理与核心的模型进行了解耦,这将方便用户自由地切换数据集。如果模型被用在较大的业务中,那么,完全地控制输入对下游来说是非常有价值的。一个典型的input_fn具有如下的形式
- 2、用model_fn来确定模型。该框架在设计时,创建Estimator只需要提供一个callback,即model_fn。该函数返回一个op,可用来进行training、evaluation或者predcition,这取决于你创建的graph是什么,创建什么样的graph又取决于你调用的是Estimator的哪个方法(train、evaluate、predict)。例如当你调用train方法时,model_fn被框架调用时,mode参数将会是TRAIN,这样用户就可以在train这种mode下创建用来训练的graph。
从概念上讲,可以创建完全不同的三个graph,并且model_fn也可以返回不同的信息,这取决于mode这个参数。既然这样,为什么要把这三个不同的graph放在一个model_fn中定义呢?因为设计者发现,生产中常见的一个问题就是训练用的模型和生产用的模型不够同步。尽管大多数情况下训练用的模型和生产用的模型是有差异的,比如 batch normalize和dropout只在训练时发挥作用。然而,如果让一个人三次写同一个差不都的模型,是很容易犯错误的。所以,这里才把三个model都放在一个函数中,鼓励开发者只写一次。对于复杂的模型,比如训练时和生产使用时不一致的模型,可以通过python的条件语句来明确地表达出来。一个典型的model_fn如下所示: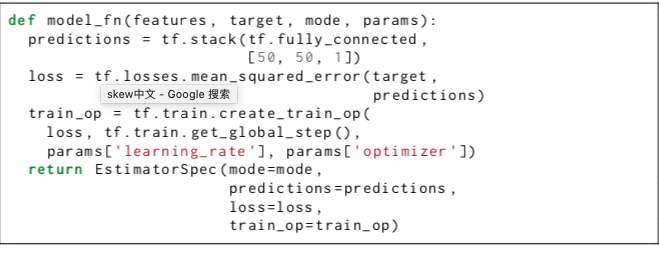
- 3、用heads来确定输出。 head api是对模型最后一个hidden layer之后的部分进行的抽象。其主要的设计目的是简化用户书写 model_fn,兼容一系列的model,并方便用户提供不同的heads。一个Head知道如何计算loss,计算相关验证指标,计算预测和计算预测相关的元数据,以便其他系统可以使用。为了支持尽可能多的model种类,一个Head的输入是lgits和labels,输出是关于loss、metrics或者predictions的tensor。
当然,head也可以直接接收最后的隐层的activation作为输入,从而省去计算logit的计算开销,这在做都个classes的问题时比较有用。一个典型的model_fn如下所示:
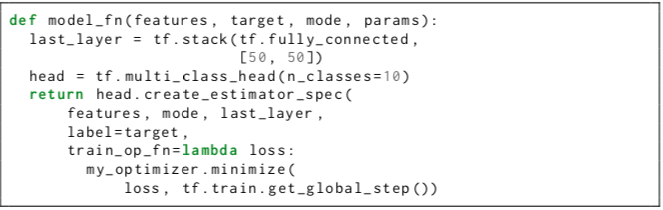
有了这样的设计,对于多个训练目标的model,只需要提供多个head就可以了,如下所示:

- 4、执行计算
graph一旦建立,Estimator就会初始化一个Session,适当初始化后,就会跑train loop,evaluation loop,或者依次读入输入,产生prediction。
典型的model训练过程就是一个train loop,但是用户需要多很多初始化的工作,比如变量初始化,embedding table的初始化,启动queue runner, 周期性写summary到文件中,以便tensorboard使用。这虽然繁琐,但是还可以忍受。当分布式训练时,真正的挑战就来了,所有worker上的变量最多只能初始化一次。模型状态必须周期性地保存,以便worker shut down并重启后可以恢复。输入的结束必须优雅地进行处理。
由于train loop实在太普遍,所以Estimator做了一个更好的实现,去除了许多样板代码,让用户少犯错误。Estimator来控制train loop。它会自动初始化变量到参数服务器,从而简化分布式训练。它将用户和tensorflow的底层适当地隔离
- 5、用hook实现代码注入
hook确保了无论你使用什么高级的优化技术,都不会破坏Estimator控制的train loop。你也可以用来定制和train loop相伴的处理,比如调试,监控、记录、生成报告等。hook允许用户在Session 创建时,每轮迭代之前和之后,训练结束后这几个时点定制自己的操作。这些操作是没有在model_fn中定义的。比如,如果一个用户需要train一定的时间,而不是一定的轮数,他可以这样做:

hook会在传给 train 函数后生效。Estimator内部的生成checkpoint、summary等功能都是借助hook实现的。
3.3、Canned Estimator
这是已经实现好的Estimator,开箱即用。
神经网络依赖dense tensor,但是现实中的输入很多都是稀疏的,比如query , 产品id, url, 视频id等。将这些输入转换成dense tensor是一个费力的事情。
为此,Estimator提供了FeatureColumn来简化这种转换。FeatureColumn是 Canned Estimator的一个参数,用来执行输入到dense tensor的转换,以便核心模型可以使用输入数据。
4、分布式执行
分布式执行的核心接口就是Experiment这个类,它将train和evaluation的输入进行打包。其核心架构如下: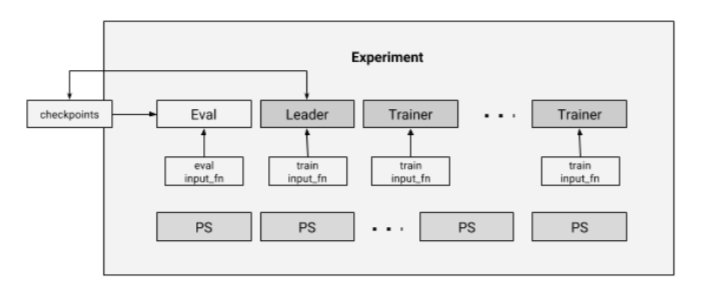

若有收获,就点个赞吧
0 人点赞
