在上一篇文章中,我们简述了skip gram版word2vector的基本原理,留下一个问题待解决,那就是网络非常大,这将导致如下几个困难:1、在上面训练梯度下降会比较慢;2、需要数量巨大的数据来喂到网络中;3、非常容易过拟合。这一节就是专门介绍实际训练中的技巧的。原文在这里:http://mccormickml.com/2017/01/11/word2vec-tutorial-part-2-negative-sampling/
当然,我不会生硬地翻译这篇文章,而是按照自己的理解,尽可能用自己的逻辑将它写出来,期望能够比原文更加清晰一些。
一、将词组和短语看作独立的单词
这个技巧的原理非常简单。比如文本中有“中华人民共和国”,此时,按照机械的划分,中华、人民、共和国应该是三个词,但是显然,中华人民共和国作为一个单独的词会更加合理一些。
如何从文本中发现词组和短语是一个专门的算法,这里略过了,因为超出了我们今天的主题。
二、对高频词进行抽样
让我们回顾一下上一节构造训练数据单词对的方法。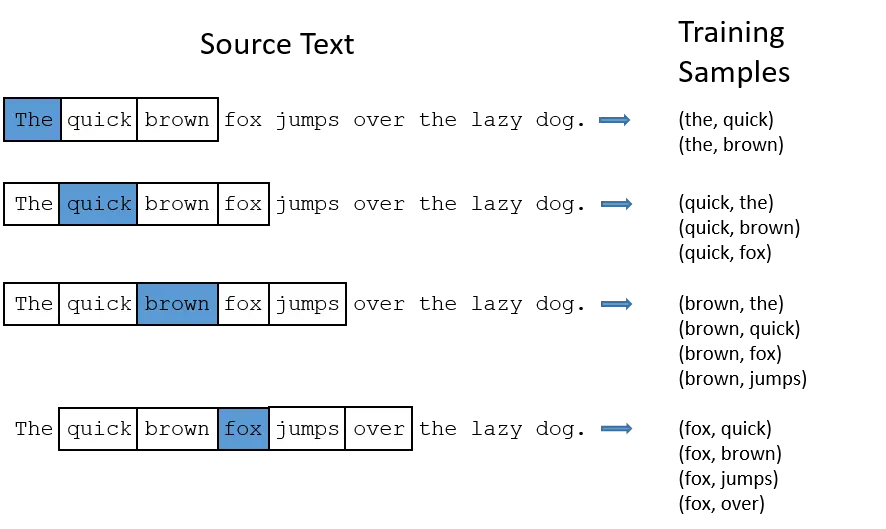
在上面的构建单词对的过程中,对那些常见的词,如“the”存在两个问题:
1、类似(quick,the)这样的单词对并没有什么用,因为此处的the并没有对理解quick产生什么贡献,它太普遍了,以至于在大多数单词的周围都可以发现它。此时,我们只能说the在quick 的周围,却不构成quick 的context。
2、上面的办法会产生太多(the,…)样式的单词对,这对于学习单词the的vector来说,实在是太多了。
解决这两个问题的办法就是subsampling,具体意思是:
当我们扫描文本中的词时,会根据一定的概率删除这个词,也就是相当于文本中此处没有了这个词。这个概率大小取决于该词在整个语料库中的出现频率。出现频率越高,那么我们删除该词的概率就越大。
这个很容易理解,以上面的the为例,由于它在整个语料库中出现的频率很高,我们就会删除相当一部分的the,以便减少训练量。
再具体一点,假设我们删除了jump over the
lazy dog 中的the,我们的窗口大小是2,那么,the与其前后各两个词组成的词对就不会称为训练数据,因为the已经被删除了,其次,以the前后各两个词作为输入的词对中,都会减少一个(*,the)的词对。
那么,接下来一个问题就是如何确定删除一个词的概率?直接上公式: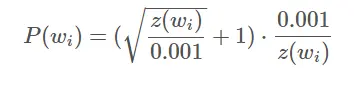
P(wi)是保留单词wi的概率,z(wi)是该词在整个语料库出现的比例。
我们可以将上面的公式画成图来看看: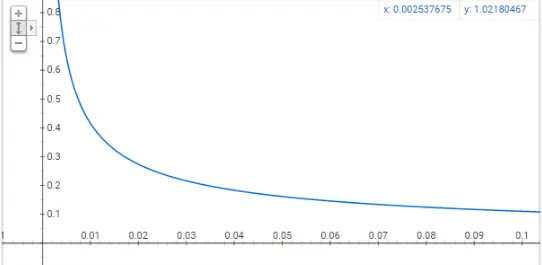
Note:要得到这个图,只需在google中输入
Graph for (sqrt(x/0.001)+1)*0.001/x即可。
至于这个公式怎么来的,说实话,我也不清楚,鉴于它不是本文的重点,我也没有深究,如果有清楚的伙伴,欢迎留言补充。
三、负抽样
这个办法才是本文的重头戏,其中的思想对人很有启发性。刚刚听完蚂蚁金服张家兴老师分享的蚂蚁金服人工智能实践,里面提到了问题匹配模型训练中的一个技巧,其思想与负抽样很相似。可见技术是具体的,但技术背后反映出的解决问题的思想却是共通的。
负抽样技术主要解决的问题就是模型难以训练。所以,我们先来看看模型为什么难以训练。
使用SGD训练神经网络的过程就是取出一条样本数据,然后据此去调整神经网络的所有权重,以便网络能够对这条数据的预测更加准确一些。这里的重点是所有权重!
调整所有的权重是多大的工作量呢?在上篇文章中,我们已经有过解释,请参考上篇文章。总之,所有权重是一个巨大数量的系数。对每一条样本,每训练一次,这么多的系数都要进行轻微的调整。显然,超多的训练数据,巨多的权重系数,将使得神经网络的训练非常缓慢和困难。
负抽样解决这一问题的办法就是使得对每一条样本的每一次训练,只更新很小一部分的权重,而不是全都更新。下面我们深入细节来看一下。
假设我们的训练数据是(fox,quick)单词对,回忆一下,此条训练数据的标签就是quick,用one-hot编码后,就是一个8维向量,quick所对应的维度为1,其他维度为0。
也就是说,我们希望神经网络输出的8维向量中,对应quick的维度是1,其他维度是0。在输出层,每一个输出维度实际上对应着一个神经元。
在我们的例子中,我们看到其他应当为0的维度有7个,在实际工作中,这个维度的数量是非常大的,因为我们的词表一般会很大。
所谓负抽样,即是从这些应当为0的维度中随机抽取几个,只更新这几个维度对应的神经元的权重,这既是负抽样的确切含义。当然,同时还要加上输出应当为1的维度所对应的神经元。
具体负抽样时抽几个维度的神经元,取决于具体的问题,google的论文中建议是5到20个。
让我们用一个例子来具体感受一下。假设我们负抽样的维度数为5,我们的词表中有10000个单词,词向量的维度为300,也即是隐藏层有300个神经元。
那么,在输出层,权重矩阵的大小将是30010000。现在我们抽取了5个负的维度(输出应当为0的维度),加上输出为1的维度,只更新这6个维度所对应的神经元。那么需要更新的权重系数是3006=1800个。这只占输出层中所有权重系数的0.06%!!
另外,在隐藏层,我们还要更新输入的单词所对应的300个权重。这是无论用不用负抽样,都要更新的权重。
如果不好理解,我们就具体一点,隐藏层可以看作一个10000*300的矩阵,其中每一行都代表一个单词的300维词向量,我们更新的就是输入单词所对应的那一行的300个权重系数。
四、负抽样应当抽谁的样?
上一节中,我们说了负抽样,一般抽5到20 个维度。问题来了,假设是抽5个维度,那么,应当抽哪5个维度呢?负的维度实在太多,如果词表为10000,那么负的维度就有9999个。从这里面抽5个,难道是随机抽吗?
答案是否定的。在抽取这5个维度时,是按照单词在语料库中出现的次数多少来的, 出现次数越多,那么越可能被抽中。具体是按照如下公式来决定的: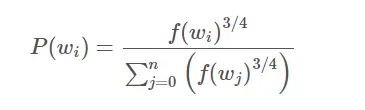
P(w_i)就是w_i这个单词被负抽样抽中的概率。
f(w_i)即是w_i在语料库中出现的次数。
至于为什么要取一次3/4次方,据说是基于经验,这样效果会更好。
五、无总结,不进步
通过这两篇文章,我简要地叙述了skip-gram版的word2vector的原理和部分实现细节。
我觉得最重要的在于体会作者设计这样的神经网络,用n-gram来构造训练数据背后所隐含的思想。这些思想才是我们在实际工作中最紧缺的。
这里留一个问题供大家思考,在负抽样时,为什么要按照单词出现的频率来抽样,这样有什么好处?

若有收获,就点个赞吧
0 人点赞
