这是一篇论文阅读笔记。原论文是How to Fine-Tune BERT for Text Classification?
How-to Fine-Tune-BERT-for-Text-Classification.pdf
一、Bert finetune面临的三个问题和解决办法
1、如何处理超过512长度的句子
head= 128 + tail = 382 效果最好
2、如何选择适当的layer,embedding Layer、encoder Layer、还是pooling Layer?
3、如何处理过拟合问题?
2e-5这样较小的学习率有助于Bert克服 catastrophic forgetting 问题
同时,对较低的layer,进行 lr的decay,有助于达到更好的效果, decay factor 最佳值是0.95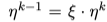 从最后一层往前,逐层降低学习率
从最后一层往前,逐层降低学习率
二、Bert Further Pre-training需要考虑的三个方面
1、使用within-task数据
2、使用in-domain数据
3、使用cross-domain数据
结论:in-domain > within-task > cross-domain
三、Bert结合Multi-task的fine tuning怎么做?
结论:意义不大

若有收获,就点个赞吧
0 人点赞
