机器学习面试中一大类问题就是比较不同模型的异同。这类问题可以迅速刺探出面试者对模型理解的深度,因为它不像单一模型的问题,只要你将这个模型的推导搞清楚,原理说清楚就可以了,而是要求你对不同模型背后的思想有深刻的认识。否则,即使从网上背了一些现成的答案,也很难蒙混过关。本文题目就是一道这样的题。如果你看了题目感觉毫无头绪,那就打起精神看下去吧。
1 从损失函数说开去
svm和lr都是分类模型。我们假设正类为y1=+1,负类为y2=-1。分类模型的基本思路很简单,就是找一个函数f(x),我们希望,如果x为正类,那么f(x)的值是正的,如果x为负类,那么f(x)的值为负的。这个要求也可以换个说法,就是使y*f(x)始终为正,不难发现,这个要求和上面的要求是等价的。
这样变换的目的何在?答案就是,对于一个样本(x,y),f(x)这个函数对该样本预测的loss就成为了y_f(x)的函数。我们可以很容易定义出,如果y_f(x)大于0,预测正确,那么loss为0,如果小于0,那么预测错误,loss为1。将这样的loss降低到0就是我们的终极目标!也就是说,这种loss是我们真正在乎的loss。因为这样的loss降低到0,意味着我们对样本的预测是完全正确的。如下图所示: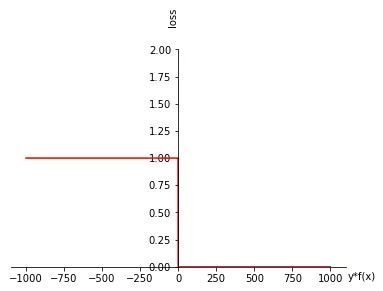
上面的图用函数来描述就是如下: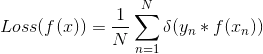
这里的δ函数称为指示函数,即如果y*f(x)小于0,其值为1,否则为0。
既然f(x)在一个样本上的loss可以用δ(y*f(x))衡量,自然就可以衡量在整个训练集上的loss,如果训练集有N笔数据,我们可以得到f(x)在整个训练集上的平均loss:
按照一般套路,下面自然是调整f(x)函数的各个参数,尽可能地最小化loss。But,这个loss不太好最小化哇。
拿其中一个样本(xi,yi)来说,假设现在yi_f(xi)是小于0的,其预测loss为1,若想使得f(x)在这个样本上预测loss降低,我们只能调整f(x)的参数,使得yi_f(xi)大于0,但是显然,若只对f(x)的参数进行微弱的调整,yi_f(xi)的符号很难改变,因为此时,yi_f(xi)对于f(x)的参数来说是连续的。若对f(x)的参数进行大刀阔斧的调整,一步到位使得yi*f(xi)改变符号,则调整后得到的新f(x)在(xi,yi)以外的样本上的预测loss将会完全不可控,因为f(x)的参数变动太剧烈了,从而无法保证新的f(x)在整个训练集上的loss降低。
这里,我们可以体会一下大家熟悉的SGD的思想,它背后的假设就是当你轻微地调整f(x)的参数,使得其对于某个样本的预测loss减小时,微调后的f(x)在其它样本上的loss的和大概率会保持不变,或者说对其他样本的预测loss有的增大,有的减小,总体上可以互相抵消。没有这个假设,SGD就不会有效果。
理想很丰满,现实很骨感,这个问题怎么解决?
对此,svm和lr都给出了自己的解决方案,它们的解决方案有相同的地方,也有不同的地方。
2 替换掉δ
在上面的分析中,我们看到,loss虽然很硬很完美,但是没法最小化,原因在于我们选择的损失函数是δ,前面提过,这个损失函数是我们理想意义上的损失函数,这个损失函数是关于y*f(x)的指示函数。
仔细体会一下,充分发动我们的直觉,不难发现,f(x)对一个样本预测的loss大小与yf(x)有着非常密切的关系。假设y=1,yf(x)若为正,说明f(x)也为正,并且yf(x)越大,说明f(x)正的越大,意味着我们的函数f越倾向于将x预测为+1类别。y=-1时,_y_f(x)若为正,说明f(x)为负,并且y*f(x)越大,说明f(x)负的越多,意味着我们的函数越倾向于将x预测为-1类别。
从这个角度看,我们的δ其实就是刻画了f对样本的loss与y*f(x)之间的这种关系,只是刻画的比较死板。
假设我们可以找到一个新的函数l,它也可以用来刻画f对样本(x,y)的预测loss与y_f(x)的关系,并且函数l是函数δ的upper bound。即,对任意一个样本(x,y),用函数l来评价某个特定的函数f对该样本的预测loss会始终大于用函数δ的评价结果, δ(y_f(x))<=l(y*f(x))。
那么,我们就可以尝试用l来代替δ,通过最小化l来达到最小化δ的目的。
行文至此,有必要重申下l,δ,f三个函数的关系,希望不要搞混了。下面我尝试用拟人的手法来进行叙述,希望能够对大家的理解有所帮助。
f就是我们的模型函数,是我们要优化的。δ是我们优化f的最高理想,δ告诉f:“嗨!f,对于样本(x,y),你的预测值是f(x),对这个预测值错误的程度是δ(y*f(x))”,f在δ面前表示非常无奈:“δ老大,你这不是为难我吗,你告诉我的错误程度要不是1,要不是0,0还好说,表示我预测正确了,这样的样本我可以不再管,可对错误是1的样本,我开始改变自己,你总得告诉我,我改变之后,离错误为0是近了还是远了吧。你这都不告诉我,可让我怎么优化我自己呢?”
其实,δ心中清楚,只要f朝着使y*f(x)增大的方向优化自己,就会变得越来越完美。但δ就像一个刻板的父亲,只愿意告诉f它做的是对是错,不屑于告诉它如何做对。
可见,δ的问题主要在于两点,f预测错误时不告诉正确的方向,其二,f即使刚刚预测正确,立马告诉f错误为0,达到perfect,而不会指导f朝更加优秀的方向去努力。
l相当于我们为f找的一个温柔的母亲,什么样的母亲会是合格的母亲呢,当然是能够很好地纠正父亲δ的缺点的母亲。对一个样本,如果f预测错误,即y_f(x)是负的,它会告诉f,越负错误程度越大,要赶紧想办法增大y_f(x),同时,因为预测错误时,δ说错误程度是1,做为母亲的l可不敢顶撞δ,所以我们希望l告诉f 的错误程度应当要大于1。毕竟,δ才是真正的权威(这里无意宣传男权思想,只是为了叙述的简明,请女士们不要误解)
另一方面,当f对一个样本预测正确时,即y*f(x)为正,l应当鼓励f朝更加正确的方向去优化,而不应当像δ那样,一旦f预测正确,就告诉它错误程度为0,让f骄傲自满,不思进取。
以上,我们大致分析了l应当具有的性质。svm和lr就是两种相似但又不同的l,下面我们具体分析下。
3 lr的l是完美的母亲
lr模型为f找的l是这个样子的: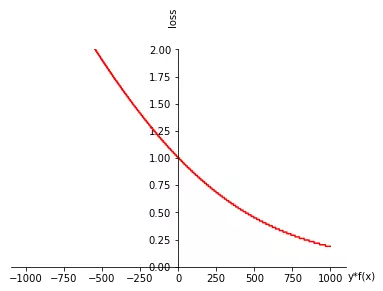
只从数学式子上看,好像看不出啥意思,我们将它画出来就清楚了。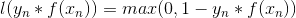
看到这个图,会不会豁然开朗,这不就是我们在第二部分中描述的完美的母亲形象吗!当f对样本(x,y)预测错误时,l评估的错误程度总是大于1的,并且,y_f(x)越负,则l评估的错误程度越严重,同时,l会指出正确的优化方向。同时,当y_f(x)为正时,l并不会像δ那样立马告诉f,对这个样本的错误程度为0了,而是会告诉f,此时的错误已经小于1了,如果能让y*f(x)更加大,则错误还会继续减小的,从而让f精益求精。
4 svm的l更像一个年长的姐姐
svm为f找到的l是这个样子的:
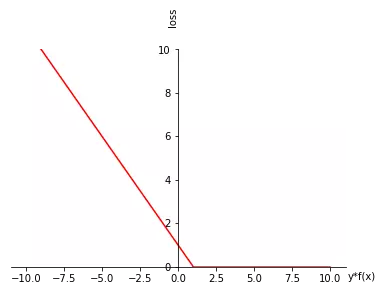
哟!这个l长得也蛮怪哦 ,啥也不说了,无图无真相:
对比svm和lr,我们发现,当f对一个样本预测错误时,它们的l是比较类似的,当f对样本刚刚预测正确时,它们的行为也是类似的,只不过一个是曲线,一个是直线而已。但是,当f对样本预测正确并且大于一定程度时,确切说就是当y_f(x)大于1时,二者的行为明显不同,lr的l还会鼓励f继续增大y_f(x),而svm则会告诉f,对这个样本预测已经非常完美了。
5回答文章题目中的问题
知道了svm和lr 区别,我们再来看看,所谓out lier,是怎么产生的,无非有两种情况,一种就是这个样本的标签y搞错了,一种就是没搞错,但这个样本是一个个例,不具备统计特性。
不论对于哪一种情况,svm会在f将这个out lier预测的比较正确时,就停止,不会一直优化对out lier的预测,因为没有什么太大意义了。而lr则不同,它会继续要求f对这个out lier的预测进行优化,并且永不停止,显然,这样的优化很可能会削弱f的泛化性能,因为没有必要死磕out lier 。
答案就是SVM!!!

若有收获,就点个赞吧
0 人点赞
