1. SDS
SDS 是 Redis 实现的简单动态字符串(Simple Dynamic String),其结构定义如下:
struct sdshdr {// 记录buf数组中已使用的字节数,即SDS字符串长度int len;// 记录buf数组中未使用的字节数int free;// 字节数组,用于保存字符串char buf[];}
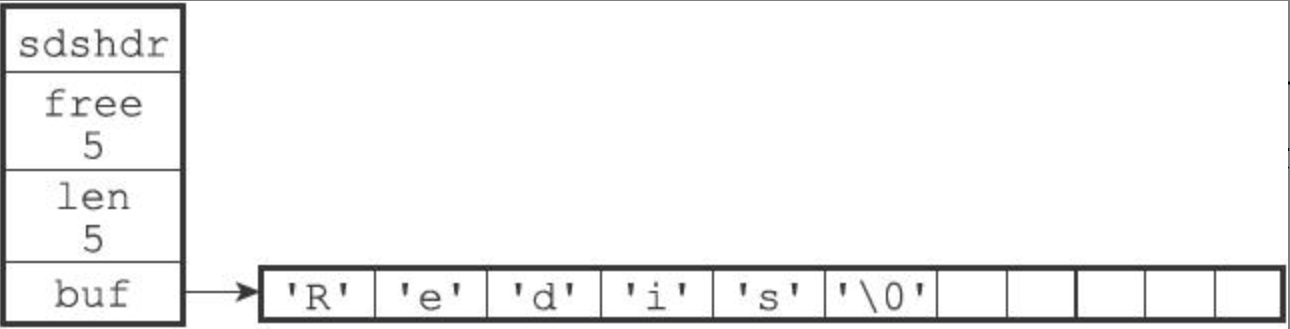
结构上,len 属性记录了当前字符串的长度,与 C 字符串相比,能够以常数复杂度获取字符串长度 O(1)。如上图,当前字符串的长度为 5;
除此之外,SDS 比起 C 字符串还有以下优点:
- 杜绝缓冲区溢出。
- 减少修改字符串长度时所需的内存重分配次数。
- 二进制安全。
- 兼容部分C字符串函数。
2. 链表
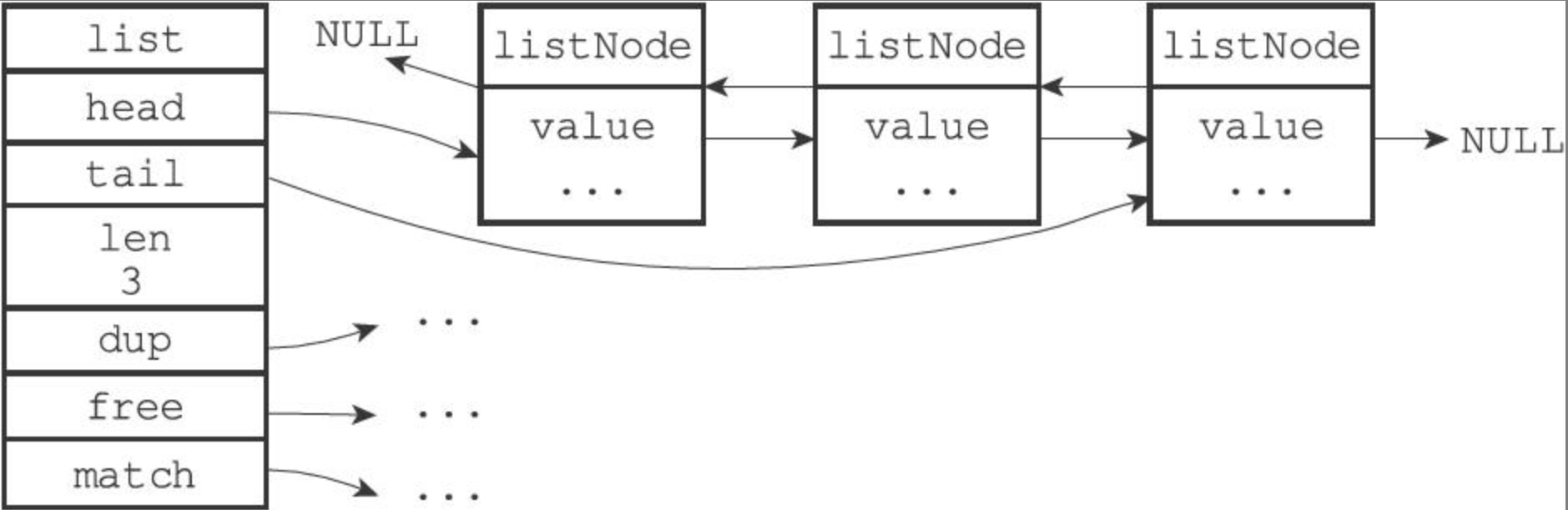
Redis 链表是由 list 结构和 listNode 结构组成的数据结构。
list
typedef struct list {
// 表头节点
listNode * head;
// 表尾节点
listNode * tail;
// 链表所包含的节点数量
unsigned long len;
// 节点值复制函数
void *(*dup)(void *ptr);
// 节点值释放函数
void (*free)(void *ptr);
// 节点值比对函数
int (*match)(void *ptr, void *key);
}list;
listNode
typedef struct listNode {
// 前置节点
struct listNode * prev;
// 后置节点
struct listNode * next;
// 节点的值
void * value;
}listNode;
链表总结
Redis 的链表实现的特性可以总结如下:
- 双端:链表节点带有 prev 和 next 指针,获取某个节点的前置节点和后置节点的复杂度都是 O(1)。
- 无环:表头节点的 prev 指针和表尾节点的 next 指针都指向 NULL,对链表的访问以 NULL 为终点。
- 带表头指针和表尾指针:通过 list 结构的 head 指针和 tail 指针,程序获取链表的表头节点和表尾节点的复杂度为 O(1)。
- 带链表长度计数器:程序使用 list 结构的 len 属性来对 list 持有的链表节点进行计数,程序获取链表中节点数量的复杂度为 O(1)。
- 多态:链表节点使用 void* 指针来保存节点值,并且可以通过 list 结构的 dup、free、match 三个属性为节点值设置类型特定函数,所以链表可以用于保存各种不同类型的值。
- 链表被广泛用于实现 Redis 的各种功能,比如列表键、发布与订阅、慢查询、监视器等。
3. 字典
Redis 的字典使用哈希表作为底层实现,一个哈希表对应一到多个哈希表节点,每个哈希表节点保存了一对键值对。
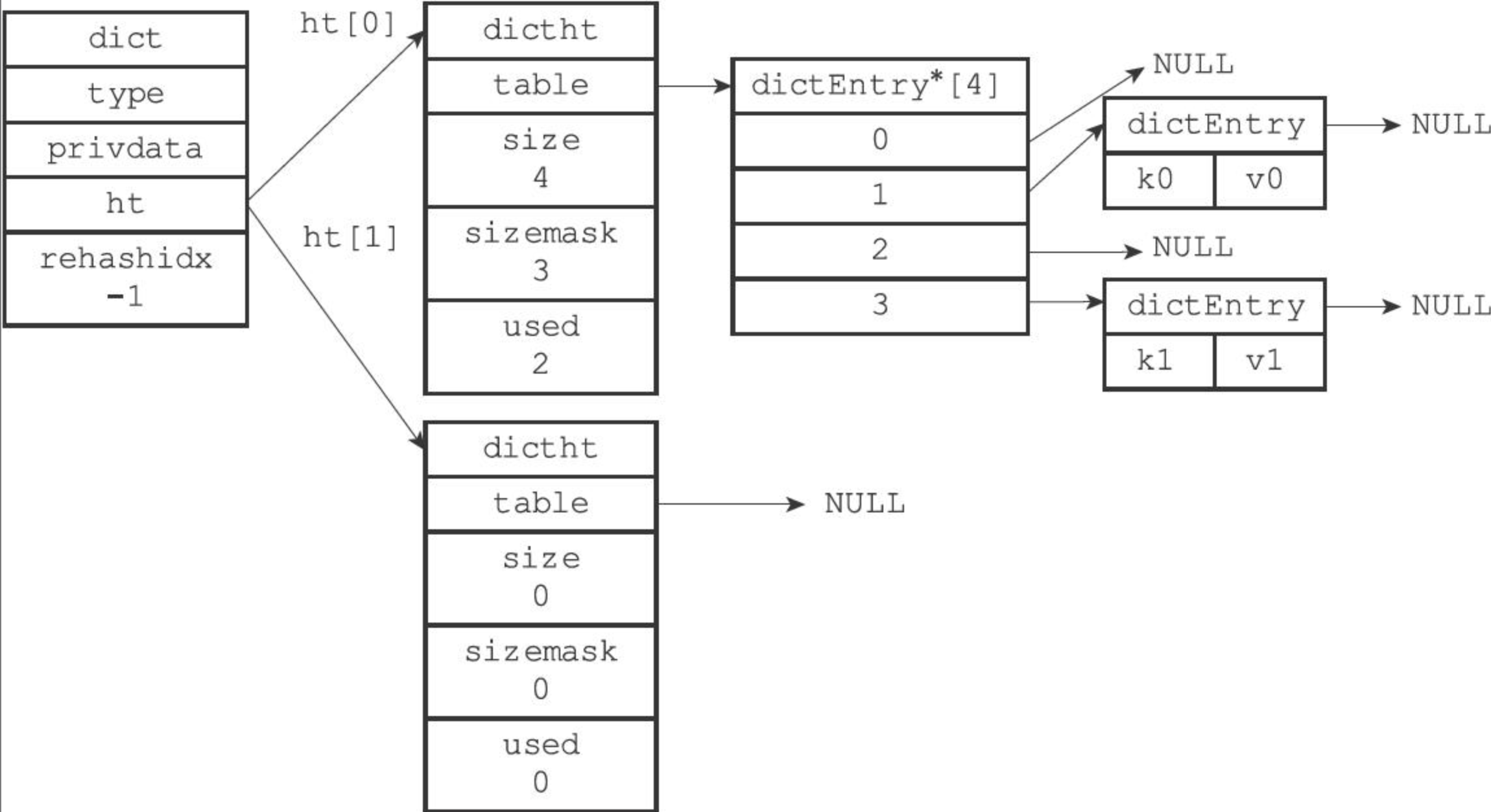
哈希表的实现类似 Java 中的 HashMap。
字典结构
dict
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表
dictht ht[2];
// rehash索引,不进行rehash时 值为-1
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
}dict;
type 属性和 privdata 属性是针对不同类型的键值对,为创建多态字典而设置的:
- type 属性是一个指向 dictType 结构的指针,每个 dictType 结构保存了一簇用于操作特定类型键值对的函数,Redis 会为用途不同的字典设置不同的类型特定函数。
- privdata 属性则保存了需要传给那些类型特定函数的可选参数。
ht 属性是一个哈希表数组,其中包含两个哈希表,一般情况下,ht[0] 保存了字典真正存放的值,而 ht[1] 只会在 ht[0] 进行 rehash 时使用。
rehashidx 属性与 rehash 有关,记录了rehash 的位置索引。
dictht
typedef struct dictht {
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码。用于计算索引值。值为size-1
unsigned long sizemask;
// 哈希表已有节点数
unsigned long used;
} dictht;
table 属性是保存哈希表节点的数组,其长度为 size 属性值。通过 sizemask 属性与存放键值对的 key 的索引计算出该键值对存放到 table 数组中的位置索引;used 属性保存了哈希表中的节点数量。
哈希计算方法:hash = dict -> type -> hashFunction(key);
索引计算方法:index = hash & dict -> ht[0].sizemask;
dict -> type -> hashFunction() 表示调用 dict 中的 type 属性的 hashFunction 函数。
dictEntry
typedef struct dictEntry {
// 键
void *key;
// 值
union{
void *val;
uint64_tu64;
int64_ts64;
}
// 指向下个哈希表节点。形成链表
struct dictEntry *next;
} dictht;
key 属性保存键值对的键值,val 属性保存键值对的值值。
next 属性保存当出现键冲突时的相同索引的键值对,即采用链地址法。
rehash
随着不断的操作,字典中的数据可能逐渐增多或减少。为了合理分配哈希表的空间,即使哈希表的负载因子(load factor)维持在一个合理的范围内,就可以通过 rehash 来完成。
rehash 指的是重新计算键的哈希值和索引值,然后将键值对放置到扩展或收缩的哈希表的指定位置上。
负载因子计算方法:load_factor = ht[0].used / ht[0].size;
rehash 分为扩展和收缩:
扩展的条件:
- 服务器目前没有在执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且哈希表的负载因子大于等于 1。
- 服务器目前正在执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且哈希表的负载因子大于等于 5。
收缩的条件:
- 负载因子小于 0.1。
rehash 的操作步骤:
- 为字典的 ht[1] 哈希表分配空间;
- 扩展时:ht[1] 空间分配为 ht[0].used 的 2 倍的最接近的 2 次幂;
- 收缩时:ht[1] 空间分配为 ht[0].used 的最接近的 2 次幂;
- 将保存在 ht[0] 的所有键值对 rehash 到 ht[1] 哈希表;
- 释放 ht[0] 哈希表,将 ht[1] 设置为 ht[0],新建一个哈希表作为 ht[1];
渐进式 rehash
为避免在 rehash 时由于键值对数量过于庞大影响服务器性能,rehash 的操作并不是一次性完成的。
渐进式 rehash 的详细步骤:
- 为 ht[1] 分配空间, 使字典同时拥有 ht[0] 和 ht[1] 两个哈希表;
- 在字典中维持一个索引计数器变量 rehashidx,初始值为 0,表示 rehash 正式开始工作;
- 在 rehash 期间,每当对字典执行添加、删除、查找或者更新操作时,程序除了执行指定的操作外,还会顺带将 ht[0] 哈希表在 rehashidx 索引上的所有键值对 rehash 到 ht[1],同时 rehashidx 属性值增加一;
- 随着对字典的操作,当 ht[0] 的所有键值对都被 rehash 到 ht[1] 哈希表中时,程序会将 rehashidx 属性的值设为 -1,表示 rehash 操作完成;
rehash 操作过程中,对于字典的操作会在两个哈希表上进行,当程序在 ht[0] 哈希表没有找到要操作的键时,会继续到 ht[1] 哈希表中查找,进而完成操作。
4. 跳跃表
Redis 跳跃表是由 zskiplistNode 和 zskiplist 组成的数据结构。
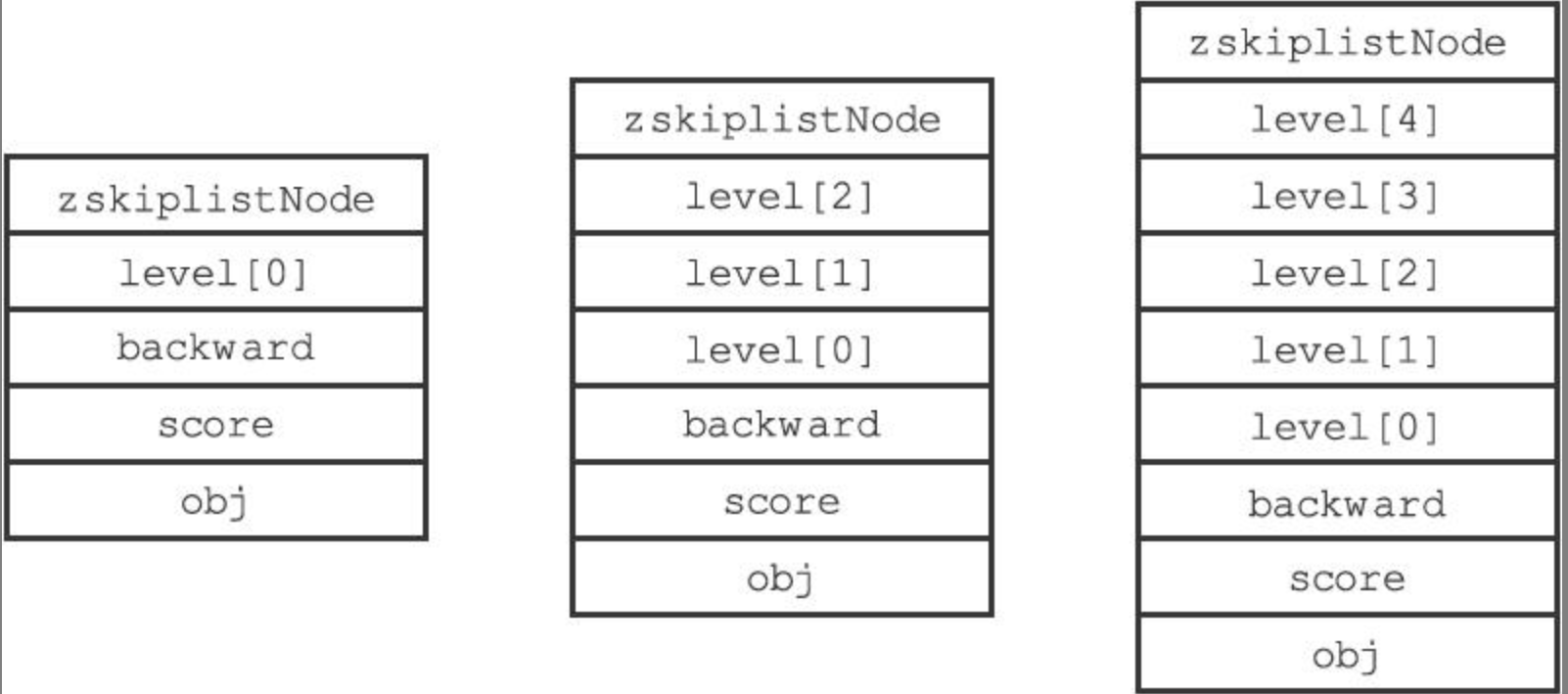
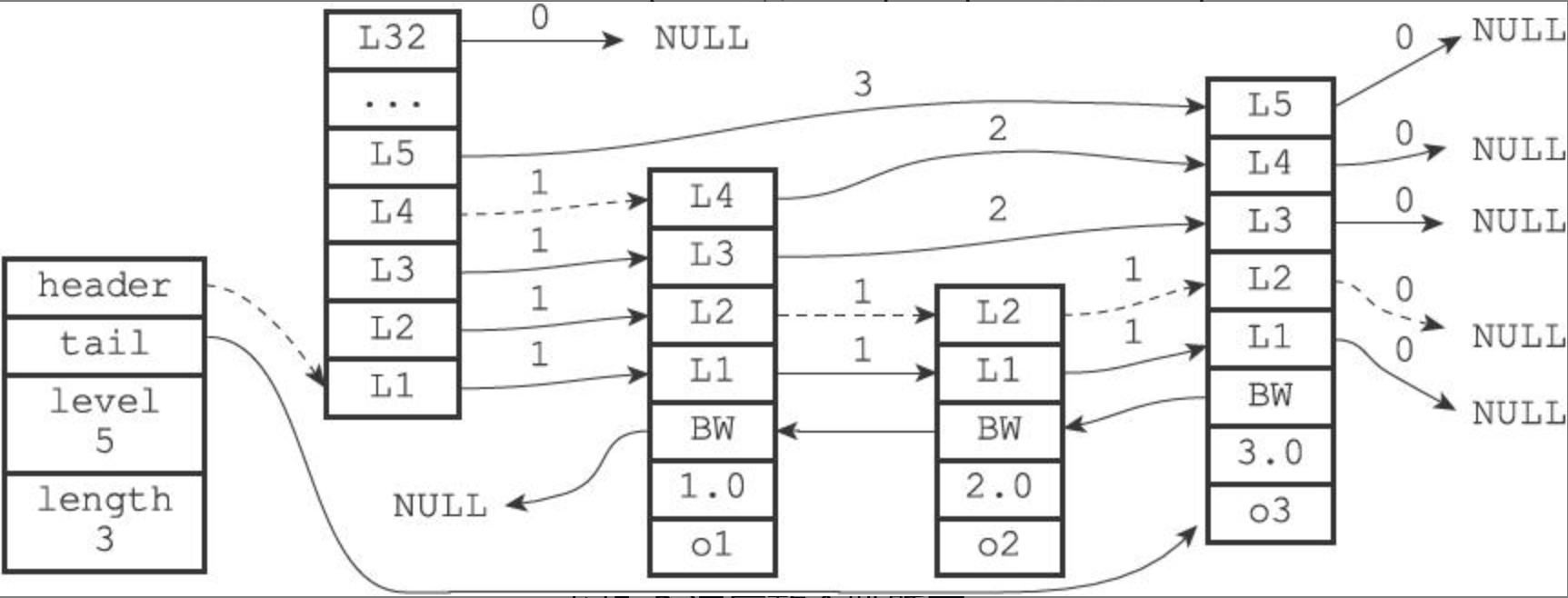
zskiplist
typedef struct zskiplist {
// 表头节点和表尾节点
struct skiplistNode *header, *tail;
// 表中节点的数量
unsigned long length;
// 表示层数最大的节点的层数
int level;
} zskiplist;
- header:指向跳跃表的表头节点;
- tail:指向跳跃表的表尾节点;
- level:记录目前跳跃表内,层数最大的那个节点的层数(表头节点的层数不计算在内);
- length:记录跳跃表的长度,也即是,跳跃表目前包含节点的数量(表头节点不计算在内)
zskiplistNode
typedef struct zskiplistNode {
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
unsigned int span;
} level[];
// 后退指针
struct zskiplistNode *backward;
// 分值
double score;
// 成员对象
robj *obj;
} zskiplistNode;
- 层(level):节点中用 L1、L2、L3 等字样标记节点的各个层,L1 代表第一层,L2 代表第二层,以此类推。每个层都带有两个属性:前进指针和跨度;
- 前进指针用于访问位于表尾方向的其他节点;
- 跨度则记录了前进指针所指向节点和当前节点的距离;
- 在上面的图片中,连线上带有数字的箭头就代表前进指针,而那个数字就是跨度。当程序从表头向表尾进行遍历时,访问会沿着层的前进指针进行;
- 后退(backward)指针:节点中用 BW 字样标记节点的后退指针,它指向位于当前节点的前一个节点。后退指针在程序从表尾向表头遍历时使用;
- 分值(score):各个节点中的 1.0、2.0 和 3.0 是节点所保存的分值。在跳跃表中,节点按各自所保存的分值从小到大排列;
- 成员对象(obj):各个节点中的o1、o2和o3是节点所保存的成员对象;
5. 整数集合
整数集合(intset)是 Redis 用于保存整数值的集合抽象数据结构,它可以保存类型为 int16_t、int32_t 或者 int64_t 的整数值,并且保证集合中不会出现重复元素。
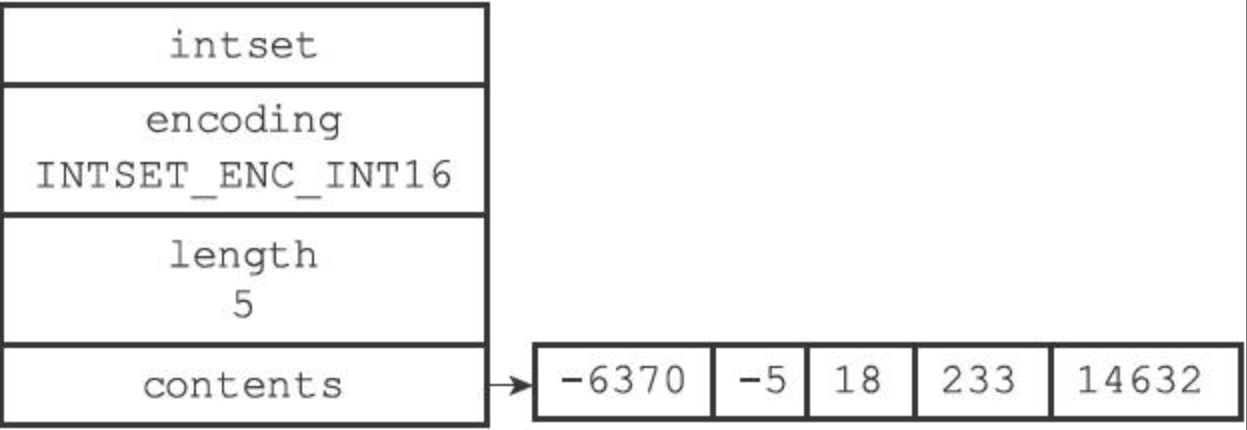
intset
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;
6. 压缩列表
压缩列表 ziplist 是 Redis 为了节约内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型(sequential)数据结构。一个压缩列表可以包含任意多个节点(entry),每个节点可以保存一个字节数组或者一个整数值。

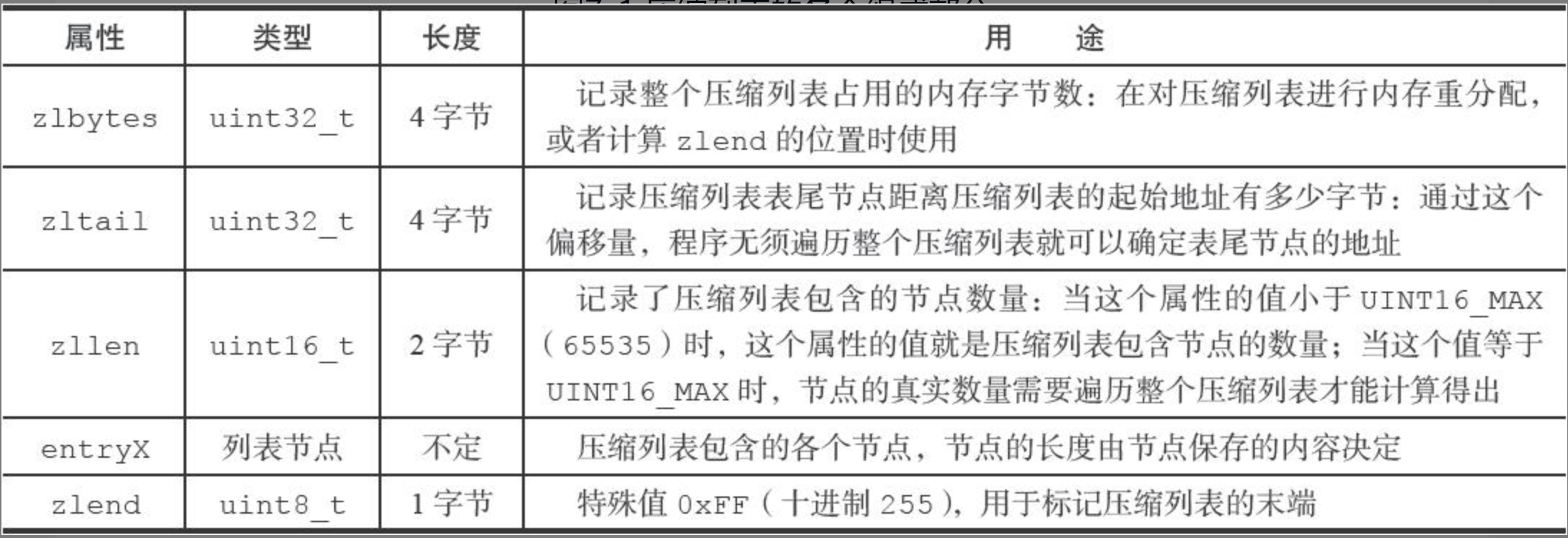
压缩列表节点
每个压缩列表节点都由previous_entry_length、encoding、content三个部分组成。


若有收获,就点个赞吧
0 人点赞
