前言
关于IO一直挺绕的,什么BIO、NIO等等,本篇整理一下下下下下。
两条定理:
1.时间换空间,空间换时间 2.软件开发中,没有什么是加一层中间层解决不了的,如果有,那么就加两层
Linux内核空间和用户空间
IO作为系统底层调用,在这之前有必要先了解下内核空间和用户空间。
内核空间(Kernel space)是内核的运行空间,用户空间(User space)是用户程序的运行空间。之所以区分的目的是为了安全隔离,即使用户程序崩溃了,内核也不受影响。
内核态和用户态
虚拟内存被操作系统划分为两块,一块是内核空间,一块是用户空间,内核空间是内核代码运行的地方,用户空间是用户代码运行的地方。当进程运行在内核空间就处于内核态,运行在用户空间就是用户态。
内核空间可以执行任意命令,调用系统一切资源,用户空间只能执行简单的运算,不能调用系统资源,必须通过系统接口(system call),才能向内核发出指令。例如:
String path = "/usr/local/xxx"; // 用户空间file.write(path); // 切换到内核空间String msg = "Hello World"; // 切回到用户空间
在Unix中可以用top命令查看
user: 用户空间占用CPU时间百分比
sys: 内核空间占用CPU时间百分比
PIO和DMA
PIO
Programming Input/Output Model,在以前磁盘和内存之间的数据传输是通过CPU控制的。如果 我们读取磁盘文件到内存中,数据要经过CPU存储转发,这种方式占用大量的CPU时间来读取文 件。
DMA
Direct Memory Access 直接内存访问,它可以不经过CPU直接进行磁盘和内存数据的传输。CPU只要下达指令,让DMA控制器来处理数据传输即可,DMA控制器通过系统总线传输数据,传输完毕再通知CPU,大大减少了CPU的占用时间。
拿 Node Js 来说,它是单线程的,如果它从磁盘读取一个文件,那么其它的无法工作了,但其实读取文件是个很简单的工作,所以可以把 CPU 让出来,直接下单指令,让 DMA 去读取,等 DMA 读好了,会把数据放到内存中,然后中断来通知 CPU 说,你要的数据已经放到某个地址上了。
缓存IO和直接IO
缓存IO
缓存I/O又被称为标准I/O,数据先从磁盘复制到内核空间的缓冲区,然后从内核空间缓冲区复制到应用程序的地址空间。大多数应用都用了缓存I/O,比如Redis。
读操作
当发生读操作时,操作系统会先检查内核的缓冲区有没有需要的数据,如果已经缓存了,那么就直接从缓存中返回;否则从磁盘中读取,然后缓存在操作系统的缓存中。
写操作
当发生写操作时,将用户空间复制到内核空间的缓存中,这时对用户程序来说写操作已经完成,至于什么时候再写到磁盘中,由操作系统决定,除非显示调用了sync同步命令。
缓存IO优点
- 一定程度上隔离了用户空间和内核空间,保护系统本身的运行安全
- 减少读盘的次数,从而提高性能
缓存IO缺点
- 数据从用户空间拷贝到内核空间多次拷贝操作,实际上开销是非常大的
直接IO
直接IO就是应用程序直接访问磁盘数据,而不经过内核缓冲区,自己管理I/O缓存区,这样做的目的是减少一次从内核缓冲区到用户程序缓存的数据复制带来的开销。对于一些复杂的应用,例如MySQL,会在用户空间自己来管理I/O缓存区。
直接IO优点
- 减少内核缓冲区到用户空间的拷贝次数,减少了系统内核和CPU的开销。
缓存IO缺点
- 每次数据要从磁盘加载,非常缓慢。
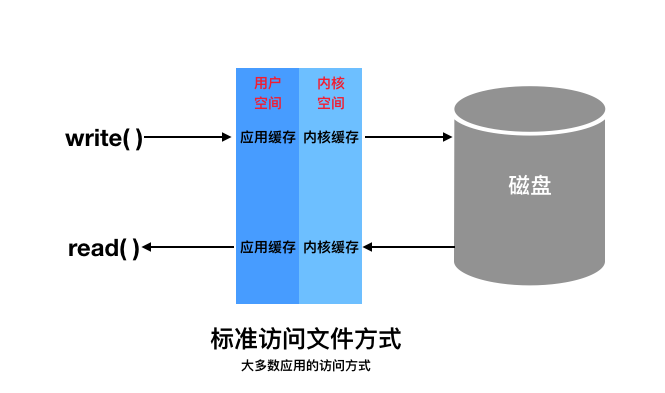
IO访问方式
磁盘IO
执行过程
- 当应用程序调用read接口时,操作系统会先在内核缓存中查看是否有需要的数据,如果有直接返回,否则,从磁盘中读取,然后缓存到内核缓存中。
- 当应用程序调用write接口时,会先将数据从用户空间复制到内核缓存中,此时应用程序写操作依据完成;何时再写到磁盘又操作系统决定,除非显示调用
sync命令。
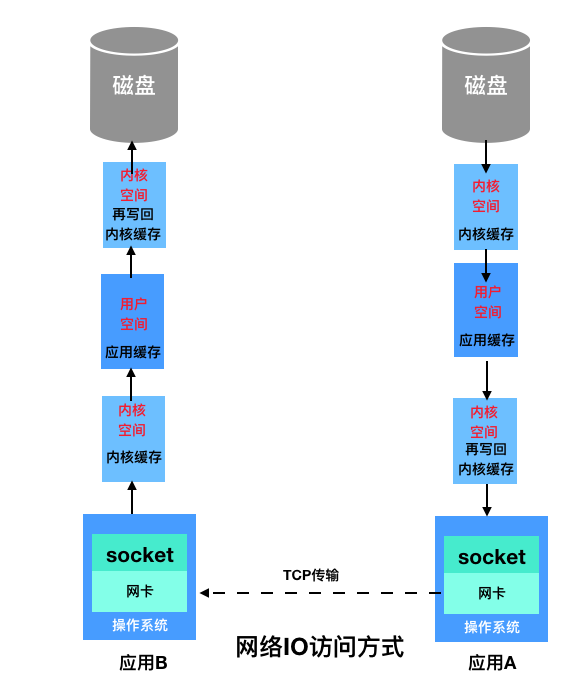
网络IO
执行过程
- 操作系统将数据从磁盘复制到操作系统内核的页缓存中
- 应用将数据从内核缓存复制到应用的缓存中
- 应用将数据写回内核的Socket缓存中
- 操作系统将数据从Socket缓存区复制到网卡缓存,然后将其通过网络发出
网络IO的延时主要由服务器响应、网络带宽等因素决定,网络IO受环境影响很大。
IO类型
同步IO和异步IO
指的是用户空间与内核空间数据交互的方式。
- 同步IO指的是用户进程触发IO操作,等待或轮询去查看IO操作是否就绪。也就是说必须等内核空间给它才可以做其它事情。
- 异步IO指的是用户进程触发IO操作后,开始做自己的事情,等IO操作已经完成的时候,会得到一个IO操作完成通知。内核会异步通知用户进程,并把数据给到用户空间。
阻塞IO和非阻塞IO
指的是用户空间和内核空间IO操作的方式。
- 阻塞IO:用户通过系统调用(system call)和内核空间发送IO操作时,该调用是阻塞的。
- 非阻塞IO:用户空间通过系统调用(system call)和内核空间发送IO操作时,该调用不阻塞,直接返回一个状态。
IO经典设计模式——Reactor
Reactor设计模式是一种为处理并发请求,将请求提交到一个或者多个服务进行处理的事件设计模式。当客户端的请求达到后,使用多路分配策略,由一个非阻塞线程来接收所有的请求,然后将这些请求派发到相关线程进行处理。
Reactor模式的好处
并发系统中常用Reactor模式来代替多线程处理方式,更节省资源,提高系统的吞吐量。
服务器会启动一个线程来轮询IO操作是否就绪,有就绪才进行相应的读写操作,这样就减少了服务器产生大量的线程,也不会出现线程切换产生的性能消耗。
多线程处理方式,每一个请求来都会起一个线程进行处理,造成系统开销很大。
IO模型
同步阻塞IO(Blocking IO)
即传统的IO模型,执行IO操作时会被阻塞。
举例:线程A查询数据,然后一直等数据库返回数据给它,在等的期间什么事也不干,就死等,直到数据返回才继续往下干。
同步非阻塞IO(Non-Blocking IO)
默认创建的socket都是阻塞的,非阻塞IO要求socket被设置成为NONBLOCk。
举例:线程A查询数据,然后一直等数据库返回数据给它,并且每隔一段时间就去看看数据有没有回来。
IO多路复用(IO Multiplexing)
即经典的Reactor设计模式,也称为异步阻塞IO,Java中的Selector和Linux中的epoll都是这种模型。跟同步阻塞类似,不过是在这基础上,添加了监听机制。优势是一个线程可以执行多个IO操作。
举例:线程A查询数据,被阻塞,但它可以干其它事情,一旦监听到数据返回,继续执行刚才的操作
该模式又有三种不同的实现方式:
- select,监听的数量有限,监听用的是轮询来判断数据是否返回
- poll,监听的数量没有限制,监听用的是轮询来判断数据是否返回
- epoll,监听的数量没有限制,监听用的事件回调机制
异步IO(Asynchronous IO)
即经典的Proactor设计模式,也称为异步非阻塞IO。执行IO操作立即返回,可以干其它事情,等数据返回了,内核会通知它。用的比较少的原因是实现复杂且需要操作系统的支持。
举例:线程A查询数据,立即返回,可以干其它事情,等数据都读到内核了,再通知它
参考资料
请你相信我所说的都是错的

若有收获,就点个赞吧
0 人点赞
