————-
更新:2020-07-07
更新JVM内存详细描述
————-
前言
站在巨人的肩膀上:
- 周志明《深入理解Java虚拟机》
- 火币大佬文章
- 也是大佬的文章
- 这也是一位大佬的文章
本文 JDK 版本是 JDK 1.8。
JVM模块知识
学习 JVM 可以用分而治之的思想,先拆解很多个模块,然后对某一个模块系统的学习,在学习的过程中,将各个模块连贯起来,由点成线,这样不仅系统学习了而且记得牢。
- 类加载机制
- JVM内存分布
- 垃圾回收机制
- 参数调优
- JDK工具使用
- 案例分析
学习JVM的好处
了解了 JVM 的内存机制,在开发中会注意到编码细节;再高级一点的编程中可能会用到类加载知识;当生产环境中遇到特殊问题时会想到垃圾回收机制是否合理;使用 JDK 自带的工具进行问题排除和定位;根据业务的具体情况进行适当的参数调优。
最后还有一点 JVM 几乎是面试必问的内容。
JVM 番外
其实不仅是 Java 语言可以使用 JVM,Scala、Kotlin、Groovy 这些语言,编译后就是字节码也可以使用。关于历史可以参考:公众号 【码农翻身】的这篇趣文。
字节码
编译型还是解释型?
Java 本身是解释型语言,但是有一个 JIT(即时编译)编译器,可以将热点代码(频繁调用的代码)编译成机器码,以提高执行效率。在 Client 模式下,默认是 1500 次,在 Server 模式下,默认是 10000 次就是热点代码,可以通过 -XX:``CompileThreshold来设置。另外 Java 从 .java 文件到 .class 文件这个过程也是编译。所以 Java 是两者共存的。
字节码
一个 *.java 文件经过编译后会生成一个 *.class 字节码文件,是以二进制形式存储的。字节码,可以看做是是 JVM 的指令集。
操作码
由指令和类型前缀组成,例如: iadd = i + add,i 就是 Interger 类型,add 就是加法运算。
根据指令性质分为四大类:
- 栈操作指令,包括与局部变量交互指令;例如:pop 删除栈顶元素、swap 交换栈顶两个元素的值
- 程序流程控制指令;例如:if_icmpge
- 对象操作指令,包括方法调用指令 ;例如:invokespecial
- 算术运算以及类型转换的指令;例如:i2d
还有一些指令是专门处理某种任务的。
类加载机制
类的生命周期
JVM 执行的 *.class文件,调用指令去执行字节码。类的生命周期就是一个 class 文件被 JVM 加载到卸载的过程。
类的唯一性判断
判断一个类的唯一性需要满足类命名空间和加载器这两个条件。
五个阶段
一个类的生命周期分为五个阶段,其中链接又分为三个部分:
- 加载
- 链接
- 验证
- 准备
- 解析
- 初始化
- 使用
- 卸载
加载
通过一个完整的类路径,将 .class 文件以字节数组的形式读入内存,创建相应的 class 对象,如果找不到就会报 NoClassDefFound 错误。
链接
验证:确保这个类是合法的符合规范条件的。
准备:为类中静态字段分配内存,代码中静态字段的初始化,并设置系统默认值,基本数据类型为 0,引用类型为 null,但如果是 final 修饰的就会直接赋值。
解析:class 文件被Java虚拟机加载之前,这个类不知道它的方法、字段地址,Java编译器会生成一个符号引用定位到具体的目标上,解析就是将符号引用解析成实际引用。
初始化
是类加载的最后一步,为常量值的字段赋值,执行构造方法,static 加载,只有初始化完成,一个类才正式成为可执行状态。
使用
类的使用分为主动使用和被动使用。主动使用指的是必须对类进行初始化,被动使用指的是引用类的方式而不会触发初始化。
主动使用:
- 创建类的实例,使用了 new 关键字
- 访问类或者接口的静态变量或对该静态变量赋值
- 调用一个类的静态方法
- 对类进行反射调用
- 初始化一个类,一定会先初始化它的父类
- JVM 启动时被标明为启动类的类,例如包含 main 方法的那个类
- 使用动态语言支持
被动使用:
- 引用父类的静态字段,只会引起父类的初始化,而不会引起子类的初始化
- 定义类数组,不会引起类的初始化
- 引用类的常量,不会引起类的初始化
卸载
当程序中不再有该类的引用,该类也就会被 JVM 执行垃圾回收,对象就不再存在,对象的生命也就走到了尽头,从此生命周期结束。
对象创建过程
当 JVM 遇到一个 new 指令,先去常量池中检查是否有这个类的符号引用,并检查这个符号引用的类是否已经被加载-解析-初始化,如果未加载,需要先加载,加载完成后给对象分配内存,对象需要多大内存在加载时就可以确定,然后给对象做一些参数设置。
类加载过程
加载->链接->初始化
类加载器
启动类加载器(Bootstrap ClassLoader)
扩展类加载器(Extension ClassLoader)
应用程序类加载器(Application ClassLoader)
线程上下文加载器(Thread Context ClassLoader)
父类加载器请求子类加载器完成一些类的加载
如果我们想加载指定class文件时,可以自定义一个类加载器来实现,具体网上很多教程。自定义类加载器都以应用程序类加载器为父类
双亲委派模型
如果一个类加载器收到了加载类的请求,它首先将请求交由父类加载器加载;若父类加载器加载失败,当前类加载器才会自己加载类。
优点:
- 避免重复加载,如果父类加载了,子类就没有必要加载了
- 安全原因,防止Java核心类库被篡改
JVM内存
运行时数据区
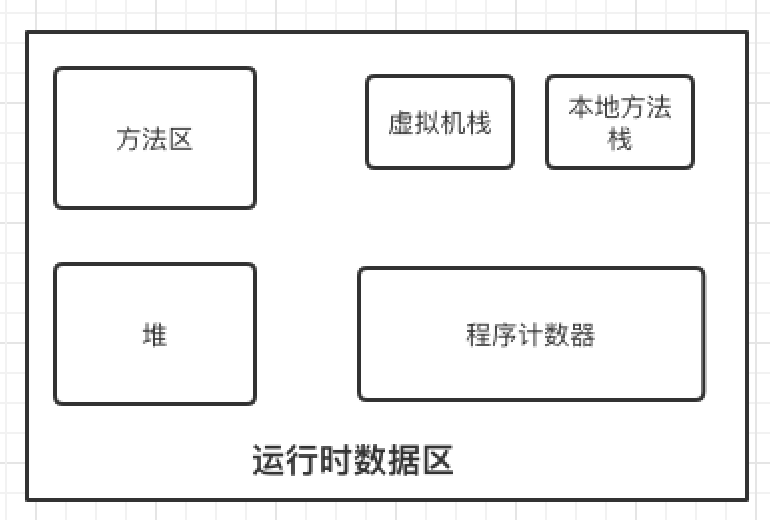
程序计数器
程序计数器是一块较小的内存空间,标记线程执行位置,会存储当前线程正在执行的 Java 方法的 JVM 指令地址。但是,如果当前线程正在执行的是一个本地方法,则是未指定值(undefined)。
该区域线程私有。
虚拟机栈
每个线程在创建时都会创建一个虚拟机栈,其内部保存一个个的栈帧(Stack Frame),对应着一次次的 Java 方法调用。用来存放局部变量表,操作数栈,动态链接,方法出口等信息,当抛出异常信息时,抛出来的就是栈信息,因此要少打印异常栈信息,消耗资源。当方法执行完毕,该栈帧会被出栈,会释放内存空间。可以通过 -Xss1m 来设置大小为 1m。
该区域线程私有。
本地方法栈
和虚拟机栈类似不过运行的是 Native 方法,由c,c++编写的方法。
堆
几乎所有的对象都存放在堆中(也可以存放在栈中),堆被分为新生代和老年代,新生代又分为 Eden 区和两个大小相同的 Survivor 区,Eden 和 Survivor 默认是 8:1:1。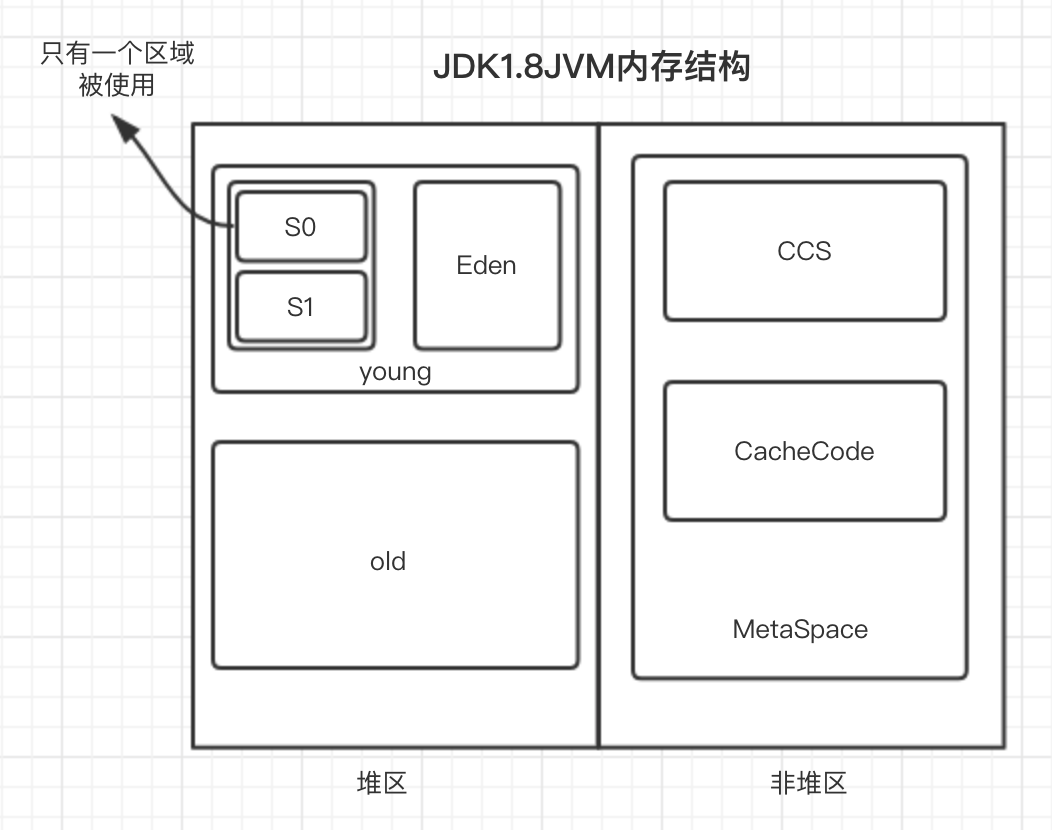
新生代
新生代中又划分为一块 Eden,和两个 Survivor。当 new 一个对象的时候会在 Eden 区划分一段内存,当 Eden 区内存不够用的时候会触发一次 Minor GC,存活下来的会被送到 其中一块 Survivor 区中。如果一个对象在 Survivor 区被复制多次(默认15)会被送到老年区。当单个 Survivor 占用 50% 的时候复制次数较多的对象也会被送到老年区。
1、大部分对象创建都是在Eden的,除了个别大对象外。 2、Minor GC开始前,to-survivor是空的,from-survivor是有对象的。 3、Minor GC后,Eden的存活对象都copy到to-survivor中,from-survivor的存活对象也复制to-survivor中。其中所有对象的年龄+1
4、from-survivor清空,成为新的to-survivor,带有对象的to-survivor变成新的from-survivor。重复回到步骤2
Eden 区还有一块叫做 Thread Local Allocation Buffer(TLAB)区域,这是 JVM 为每个线程分配的一个私有缓存区域,否则,多线程同时分配内存时,为避免操作同一地址,可能需要使用加锁等机制,进而影响分配速度。从图中可以看出 TLAB 中有 start 起始地址,top 当前分配指针,end 末尾地址,当 top 和 end 相遇表示已经分配完了,再申请一个 TLAB。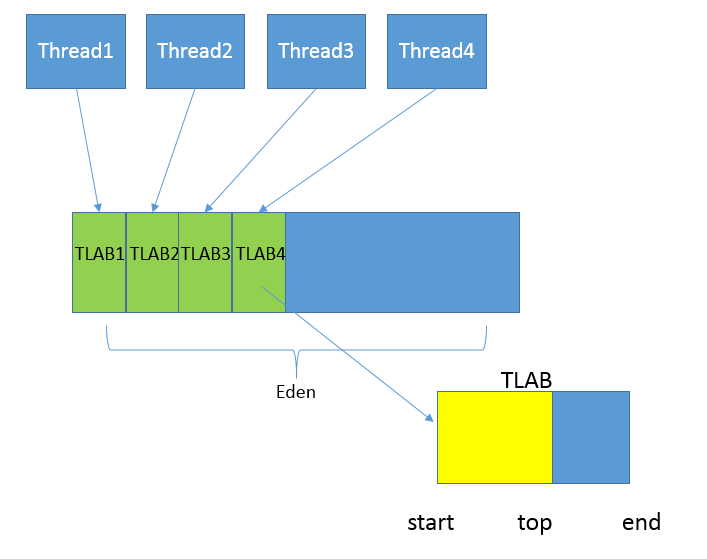
老年代
放置长生命周期的对象,通常都是从 Survivor 区域拷贝过来的对象。当然,也有特殊情况,我们知道普通的对象会被分配在 TLAB 上;如果对象较大,JVM 会试图直接分配在 Eden 其他位置上;如果对象太大,完全无法在新生代找到足够长的连续空闲空间,JVM 就会直接分配到老年代。
JVM 会大概根据检测到的内存大小,设置最初启动时的堆大小为系统内存的 1/64;并将堆最大值,设置为系统内存的 1/4
该区域线程共享。
方法区
用于存储所谓的元(Meta)数据,例如类结构信息,以及对应的运行时常量池、字段、方法代码等。
1.7 版本是被永久代实现的,1.8 版本是被元空间实现的。
该区域线程共享。
运行时常量池(Run-Time Constant Pool),这是方法区的一部分。如果仔细分析过反编译的类文件结构,你能看到版本号、字段、方法、超类、接口等各种信息,还有一项信息就是常量池。Java 的常量池可以存放各种常量信息,不管是编译期生成的各种字面量,还是需要在运行时决定的符号引用,所以它比一般语言的符号表存储的信息更加宽泛。
非堆区域中,其实也是堆,只不过不归GC管,metaspace 存的是方法区的内容,Java8 默认无限大;Compressed Class Space、 存放class信息;Code Cache 存放JIT编译后的信息
JMM
Java 内存模型
CPU 会对代码进行重排序,有时会导致代码与预期的不一样,内存屏障机制就是为了解决这个问题。
垃圾回收机制
对象已“死”的判断
引用计数法
每个对象都有一个计数器,当这个对象被一个变量或另一个对象引用一次,该计数器加一;若该引用失效则计数器减一。当计数器为0时,就认为该对象是无效对象。
优点:简单
缺点:容易造成A引用B,B引用A,造成内存泄漏(无法被回收)
可达性分析算法
从一系列GC Roots开始搜索,搜索所走过的路径称为引用链。当一个对象到Gc roots没有任何引用链时,说明该对象没被引用。
一系列GC Roots指的是:
- Java虚拟机栈所引用的对象
- 方法区中静态属性引用的对象
- 方法区中常量所引用的对象
- 本地方法栈所引用的对象
优点:可以解决引用计数法的缺点
对象引用
根据对象的生命周期,将引用分为4类:
- 强引用,new 出来的对象之类的引用,只要强引用还在,永远不会回收
- 软引用,还会被引用但非必须的对象,内存溢出异常之前,回收
- 弱引用,非必须的对象,对象能生存到下一次垃圾收集发生之前
- 虚引用,一个对象是否有虚引用,对生存时间无影响,它的目的是在垃圾回收时得到一个通知
垃圾收集算法
标记-清除法
新生代的算法,将死亡对象进行标记,然后进行清除,但是容易造成内存碎片。造成大对象无法被分配,导致提前 GC。
标记-整理法
新生代的算法,让所有存活的对象都向一端移动,然后直接清理掉该端边界以外的内存;解决了内存碎片的问题,但是移动对象的成本过高。
复制法
老年代的算法,将内存分为两等分,只使用一半的内存,当发生垃圾回收时,把存活的对象copy到另外一半中,但是对内存的使用率非常低,只能用一半(空间换时间的思想)
垃圾收集器
前面介绍了,对象存放在堆中,堆中又分为新生代和老年代,垃圾收集器也分为新生代垃圾收集器和老年代垃圾收集器。
Serial
是单线程收集器,用于新生代,使用复制算法,进行垃圾回收时,必须暂停其它的工作线程,会出现Stop The World现象,优点是简单高效。
Serial Old
ParNew
Parallel Scavenge
Parallel Old
是Parallel Scavenge的老年代版本,使用标记整理算法
CMS
用于老年代,使用标记清除算法,特点是垃圾收集时让停顿的时间达到最短
G1
用来替换老年代的CMS收集器,在新生代和老年代中都可以用,特点是注重停顿时间和吞吐量,使用了多种算法,并且对堆的内存布局进行了重新的定义
GC类型
Full GC
新生代,老年代,元空间的全部回收,老年代空间不足,方法区空间不足会触发Full GC
Major GC
Minor GC
回收新生代内存
参数调优
参数设置
使用命令启动 Java 程序一般格式为:
#1java [options] classname [args...]#2java [options] -jar jarfile [args...]
[options] 就是系统参数,在 IDEA 中的 VM options 配置,例如:
# 使用 jps -v 可以看到该程序所有的 [options]java -jar -DlogPath=/mnt/log/log-info.log -Xmx1g test.jar
[args] 就是程序启动参数传给 main 入口的,在 IDEA 中的 Program arguments,例如:
# 使用 jps -m 可以看到所有的 [args]java -jar test.jar Hello World
- 标准选项,适用于所有 JVM,该类型选项前缀是 “-”
- 非标准选项,适用于部分 JVM,该类型选项前缀是 “-X”
- 运行时高级选项,适用于部分 JVM,该类型选项前缀是 “-XX”
- 布尔类型选项用“+”表示开启
-XX:+optionName,用“-”表示禁止-XX:-optionName key-value形式指定对应的值,如:-XX:key=value
- 布尔类型选项用“+”表示开启
- JIT编译高级选项,
- 运维高级选项
- 垃圾收集高级选项
总的来说这些选项都需要一个参数,选项和参数之间用冒号“:”或是等号“=”分隔,也可以不用前缀直接跟所需的值就行,参数的值也可以根据百分比来设置,例如0.25表示25%。
| 参数 | 说明 | 举例 |
|---|---|---|
| -Xms | JVM堆的初始值,要求是1024的整数倍且大于1 MB,如果不设置这个值,那么它将是年轻代和老年代大小之和,一般和-Xmx一样大。 | -Xms6m,设置堆大小最小为6m |
| -Xmx | JVM堆的最大值 | -Xmx2g,设置堆最大为2G |
| -Xmn | 设置年轻代的大小,等同于-XX:NewSize | -Xmn256m,-XX:NewSize=256m,设置年轻代为256m |
| -Xss | 线程虚拟机栈的大小 | -Xss1m,栈的大小设置为1m,和-XX:ThreadStackSize=1m等价 |
| -XX:NewRatio | 设置年轻代和老年代的比例,默认是2 | -XX:NewRatio=3,表示年轻代和老年代比例为1:3 |
| -XX:SurvivorRatio | Eden区和Survivor的比例,默认是8 | -XX:SurvivorRatio=8,表示Eden区和两个Survivor区比例为8:1:1 |
| -XX:MaxMetaspaceSize | 元空间最大大小,默认是不限制的 | -XX:MaxMetaspaceSize=256m,设置元空间大小为256m |
| -XX:+PrintGC | 打印GC简要信息 | |
| -XX:+PrintGCDetails | 打印 GC 详细信息 | |
| -XX:+HeapDumpOnOutOfMemoryError | 发生OOM打印日志dump文件,和 -XX:HeapDumpPath配合使用 |
|
| -XX:HeapDumpPath | dump路径 | -XX:HeapDumpPath=/home/log/ java_pid.hprof |
| -XlogGC | gc日志路径 | -XlogGC:/home/user/log/GC.log,设置gc文件路径 |
| -verbose:gc | 显示每次gc事件信息,和其它gc参数配合使用,支持动态设置 | |
| -D | 设置系统属性 | -Djava.serurity.egd |
| -XX:+UseG1GC | 使用G1垃圾收集器 | 类似的还是+UseParallelGC等等 |
| -XX:+UseConcMarkSweepGC | 使用CMS垃圾收集器 | 类似的还是+UseParallelGC等等 |
例如在 Tomcat 中$TOMCAT_HOME/bin/catalina.sh 中配置 JAVA_OPTS:
# 在最上面定义JAVA_OPTS="-Xms6g -Xmx6g -verbosegc -XX:HeapDumpPath=/usr/local/"
你启动了 IDEA,也可以通过jps -v来查看它的启动参数是怎么设置:
以上是一些常见的,更多选项功能还是参考官方文档。
配置建议
如果不知道配置多少,建议配置为该服务器或容器可用容量的 70%-80%,例如总共就 8G,系统占用了一些,还剩 7.5G,那么堆可以配置为:7.5 * 0.8 = 6G 也就是说 -Xmx6g。如果知道堆外内存的使用量,还需要预留一些给堆外内存使用,例如 Netty 之类的框架。
还有一点就是 JVM总内存=堆+栈+非堆+堆外内存 所以,你配的是 6G,但是发现这个进程超过了 6G 也是正常的,因为那仅仅是堆的大小。
还有就是一般都会配置 GC 信息,方便后续监控:
-verbose:gc-XX:+PrintGCTimeStamps-XX:+PrintGCDetails-Xloggc:/home/test/logs/gc.log
JDK工具使用
JDK提供了非常多的工具,详情可以参考官方文档工具篇。它们都有-help帮助命令。
jps
查看进程信息,一般我们看Java进会用ps -ef | grep java命令来查看,但是用jps也可看到pid,例如:jps -l
liuziqing@liuziqingdeMacBook-Pro$ jps -l54769 sun.tools.jps.Jps37058 org.jetbrains.jps.cmdline.Launcher27139 kafka.Kafka25591 org.apache.zookeeper.server.quorum.QuorumPeerMain
- jps: 显示进程id
- jps -l: 显示路径
- jps -v: 查看配置参数
-
jstat
统计JVM状态信息,更多信息,参考文档。
-gc GC相关的堆内存信息. 用法:
jstat -gc -h 10 -t 进程id 1s 20
各参数解释:
Timestamp 列: JVM 启动了1425万秒,大约164天。S0C: 0 号存活区的当前容量(capacity), 单位 kB.S1C: 1 号存活区的当前容量, 单位 kB.S0U: 0 号存活区的使用量(utilization), 单位 kB.S1U: 1 号存活区的使用量, 单位 kB.EC: Eden 区,新生代的当前容量, 单位 kB.EU: Eden 区,新生代的使用量, 单位 kB.OC: Old 区, 老年代的当前容量, 单位 kB.OU: Old 区, 老年代的使用量, 单位 kB. (!需要关注)MC: 元数据区的容量, 单位 kB.MU: 元数据区的使用量, 单位 kB.CCSC: 压缩的 class 空间容量, 单位 kB.CCSU: 压缩的 class 空间使用量, 单位 kB.YGC: 年轻代 GC 的次数。YGCT: 年轻代 GC 消耗的总时间。 (!重点关注)FGC: Full GC 的次数FGCT: Full GC 消耗的时间. (!重点关注)GCT: 垃圾收集消耗的总时间。
jmap
dump 堆快照。
jmap -heap pid:查看堆内存信息,例如:
# 查看进程 30900 堆信息jmap -heap 30909
jmap -dump:format=b,file=xxx.hprof pid: dump 堆内存文件,例如:
# dump 进程30909快照jmap -dump:format=b,file=30909.hprof 30909
jstack
查看调用栈信息。
jstack -l 进程id: 查看线程相关的锁信息,所以要给线程池的线程命名
jinfo
用来查看具体生效的配置信息和系统属性。
jinfo 进程id:查看属性配置,依赖了哪些 jar
JMC
官方教程。这是一个非常强大的工具,不仅仅能够使用JMX进行普通的管理、监控任务,还可以配合Java Flight Recorder(JFR)技术,以非常低的开销,收集和分析 JVM 底层的 Profiling 和事件等信息。
JConsole
官方教程。这个图形界面,好用。有内存、线程、类等几个维度,非常方便,相当于把上面几个命令结果图形化了。安装 JDK 后直接在命令行输入:jconsole 可以启动。长这个样:
VisualVM
图形工具,支持插件,可以看到各种参数,命令行中输入:jvisualvm 即可启动。长这个样:
GCViewer
图形工具,可以用来分析GC日志,下载,它本身就是个jar文件,使用很简单:
java -jar gcviewer_1.3.4.jar gc.log
MAT
图形工具,可以用来分析内存,下载
Arthas
阿里巴巴的一款工具,下载
案例分析
Java 进程无故挂掉
可以查看下该文件是否有被 Linux kill 到的信息:cat /var/log/messages | grep kille
CPU居高不下,Full GC次数过多排查
- 文章链接
Tomcat 远程Debug
Java 平台调试体系(Java Platform Debugger Architecture,JPDA)
在远程主机,${tomcat}/bin/startup.sh文件末尾添加jpda
# 在start前面添加exec "$PRGDIR"/"$EXECUTABLE" jpda start "$@"
修改远程主机${tomcat}/bin/catalina.sh文件监听端口(可选)
# 在启动脚本中找到localhost:8000大概在334行,修改如下JPDA_ADDRESS="54321"
在本地idea中配置,然后启动Debug
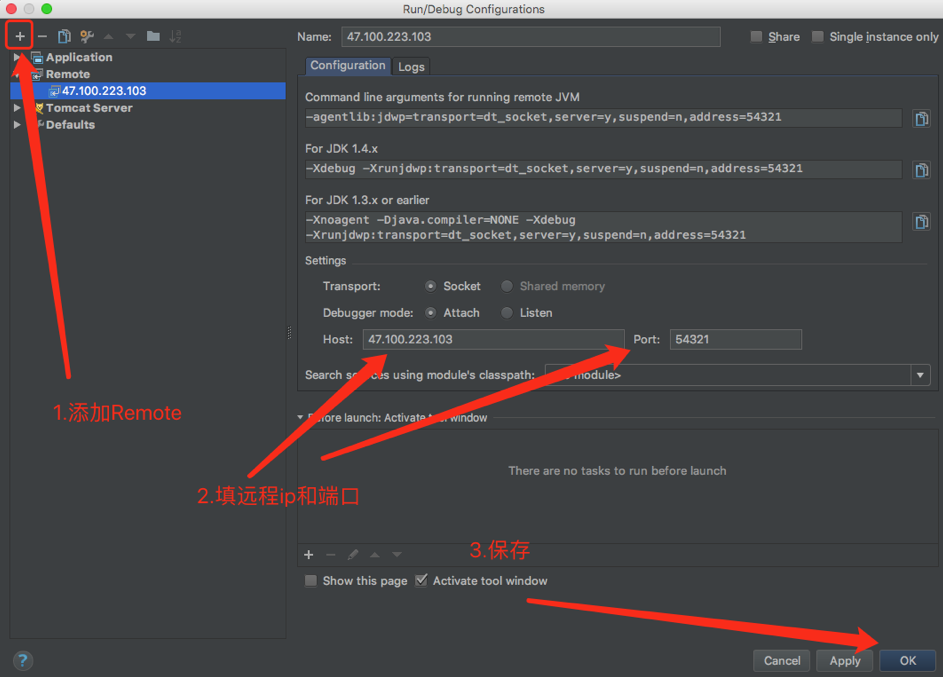
GC日志分析
在idea中Edit Configurations… -> vm options选项加上参数:
-verbose:gc-XX:+PrintGCDetails-XX:+PrintGCDateStamps-XX:+PrintGCTimeStamps-Xloggc:/temp/log/pid.gc
看看这个日志可以看出哪些信息:
2019-07-14T14:45:37.987+0800: 151.126:[GC (Allocation Failure) 151.126:[DefNew: 629119K->69888K(629120K), 0.0584157 secs]1619346K->1273247K(2027264K), 0.0585007 secs][Times: user=0.06 sys=0.00, real=0.06 secs]---手动分割线---2019-07-14T14:45:59.690+0800: 172.829:[GC (Allocation Failure) 172.829:[DefNew: 629120K->629120K(629120K), 0.0000372 secs]172.829: [Tenured: 1203359K->755802K(1398144K), 0.1855567 secs]1832479K->755802K(2027264K),[Metaspace: 6741K->6741K(1056768K)], 0.1856954 secs][Times: user=0.18 sys=0.00, real=0.18 secs]
- 2019-07-14T14:45:37.987+0800 GC事件开始的时间点
- 151.126 GC开始时间,相对于JVM的启动时间,这里是启动后151秒
- GC 用来分区是Minor GC还是Full GC,这里是Minor GC
- Allocation Failure 引起GC的原因,这里是年轻代没有足够的分配区域
- DefNew 使用垃圾收集器的名字,这里是Serial
- 629119K->69888K 收集前和收集后的年轻代内存使用情况
- (629120K) 年轻代总体大小
- 0.0584157 secs GC持续时间
- 1619346K->1273247K 收集前和收集后堆内存使用情况
- (2027264K) 总的可用堆大小
- 0.0585007 secs GC持续时间
- [Times: user=0.06 sys=0.00, real=0.06 secs] GC持续时间,通过多个分类来衡量,user各个垃圾收集器线程消耗cpu总时长,sys操作系统调用以及等待系统事件的时间,real总共暂停时间
总结:
一般看GC日志,如果老年代在Full GC后仍然接近全满,那么GC就称为了性能瓶颈,可能是内存太小了或是内存泄漏。
收集的面试题
对象可以存放在哪里?
堆、方法区、栈。
堆:几乎所有对象都存放在堆中
方法区:String 对象可以放在方法区的常量池中
栈:如果该对象是线程私有(例如在某个方法中的对象)为了性能有可能会分配到栈中,具体分配如下图: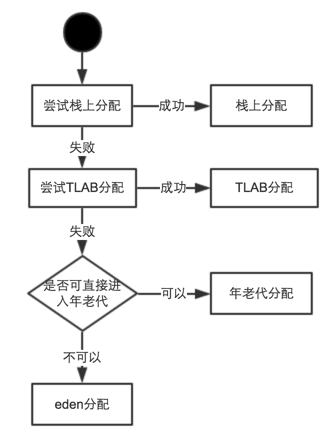
相关资料
请你相信我所说的都是错的

若有收获,就点个赞吧
0 人点赞
