————-
更新:2022-02-28
索引失效场景
————-
前言
本篇记录MySQL的一些知识点,用于复习、快速查看,本篇除非特殊注明,否则默认是MySQL版本5.7。持续更新ing😉😉😉
最初只想作为个人总结,后来越写越多,加上个人能力有限,有些知识点可能描述不当,有错漏,希望你能一起参与🎉🎉🎉,提Issues,补内容,一起添砖加瓦,让它变的更好💪💪💪。
GItHub仓库👉👉👉地址
参考
- 官方文档—— https://dev.mysql.com/doc/refman/5.7/en/
- 极客时间——《MySQL实战45讲》
- 好用的在线画图工具—— ProcessOn
- 数据结构可视化工具—— Data Structure Visualizations
- 公众号 【架构师之路】—— MySQL 系列文章
- 阿里何大的博客 —— MySQL 系列文章
- 公众号【我们都是小青蛙】—— 《从根儿上理解MySQL》
贡献者
- 十一
SQL语言分类
数据定义语言
数据定义语言,Data Definition Language(DDL),用来定义数据库、表、列,主要是对表进行操作,关键字create、alter、drop等。
数据操作语言
数据操作语言,Data Mainpulation Language(DML),主要是对数据进行操作,关键字insert、delete、update等。
数据控制语言
数据控制语言,Data Control Language(DCL),用来定义数据库的访问权限和安全级别,关键字grant等。
数据查询语言
数据查询语言,Data Query Language(DQL),用来查询数据库中的数据,关键字select、from、where等。
MySQL思想
- 能在内存中操作就不走磁盘
- 执行成本决定了一条SQL的执行计划
- 空间换时间、时间换空间
MySQL架构
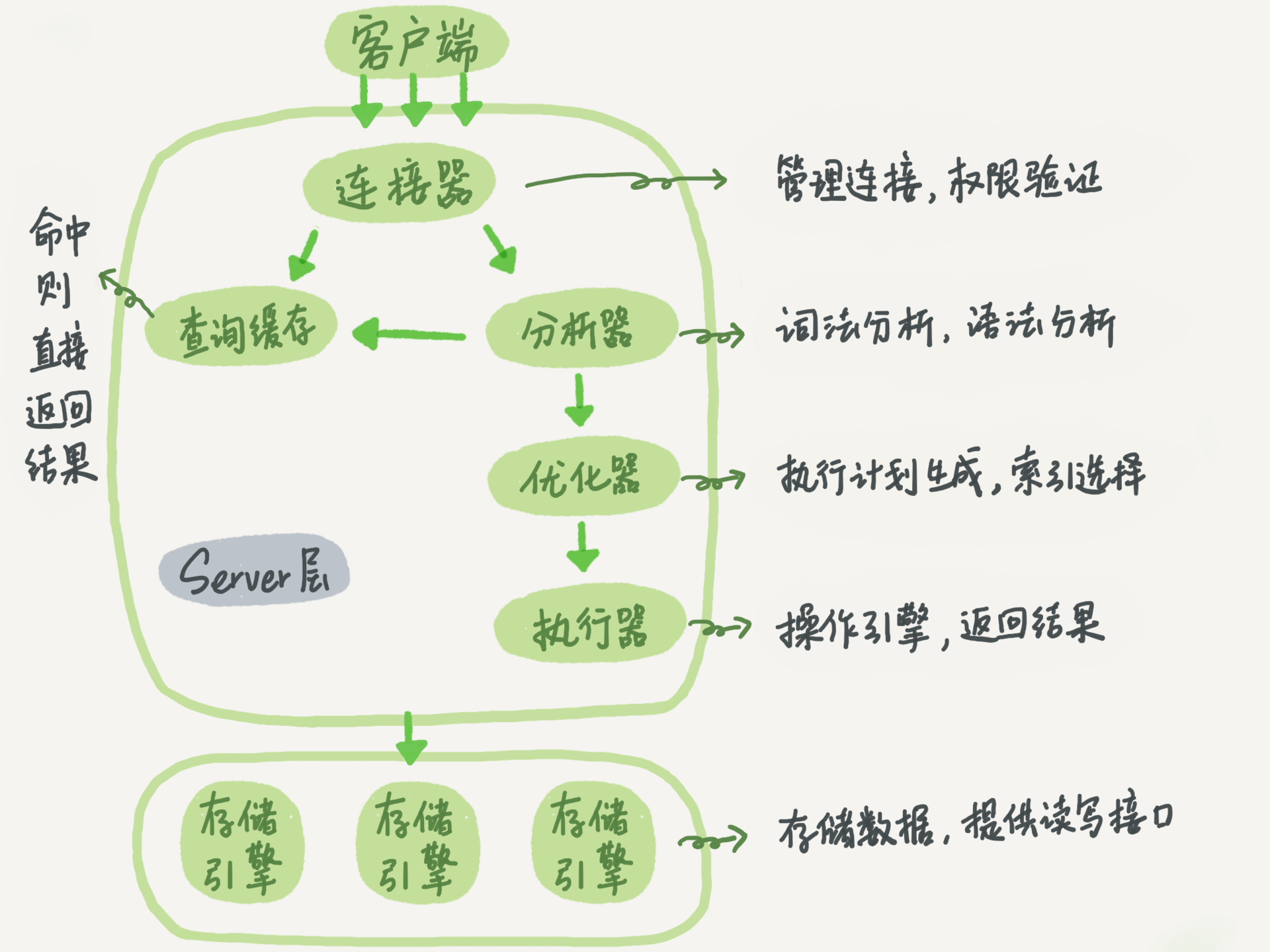
(MySQL架构图) 图片来源:《MySQL实战45讲》
Server层
大多数核心服务功能在该层。
连接器
负责和客户端建立连接、获取权限、维持和管理连接。
查询缓存
将一条SQL进行hash处理,类似Map结构,hash为key,结果集是value,hash相同直接返回value。
缓存系统会监测每张表,表发生写操作或表结构变更,该表缓存全部失效。MySQL8.0后没有该功能了。
分析器
分析每个单词字符串代表什么意思。
优化器
决定使用哪个索引,计算全表扫描的代价,确定执行方案。也会适当的优化 sql,例如联合索引 idx_a_b 但是你写的是 where b = ? a = ?; 优化器也会优化为 where a = ? b = ?;
执行器
权限校验,调用该表引擎提供的接口,返回结果。
存储过程
是一个 SQL 语句集合,你可以理解为一个函数方法,一次编译后,后面只要调用就行。具体使用和 demo
演示参考该文章。
存储引擎层
负责数据存储和提取,模式是插件式的,可插拔,以表为单位。
InnoDB
5.5.5版本后成为默认存储引擎,支持事务、行锁、崩溃修复和多版本并发控制能力,但处理速度比MyISAM慢一点点。
MyISAM
5.5.5版本前的默认存储引擎,有较高的插入、查询速度,但是不支持事务和行锁,并发性能差。
Memory
内存存储引擎,有极高的插入、更新和查询速度,数据保存在内存上,意味着可能会丢失。
索引
索引的定义
索引是可以帮助 MySQL 高效获取数据的数据结构,可以加快查询数据库的速度。
索引的优点
- 加快查询数据库的速度,降低数据库 IO 成本
- 通过索引列对数据进行排序,降低 CPU 的消耗
索引的缺点
- 索引会占用磁盘空间
- 索引会降低表更新的效率
- 增添 MySQL 复杂性,索引是需要维护的
索引模型
哈希表
key通过哈希函数换算成一个确定的位置,然后把value放在数组中对应的位置。
优点:key-value模型等值查询场景下非常快
缺点:由于不是有序,范围查询要全表扫描,慢
有序数组
有序,递增的。
优点:由于是有序的,查询效率高,适用于静态存储引擎
缺点:插入、删除成本非常高
N叉树
存在一个N叉树中,查找和更新都是 O(log(N))。
优点:读和写相对来说比较快
索引分类
二级索引
也是普通索引,由单独的列组成。
组合索引
也叫联合索引,一棵索引树上的节点有多个字段,组合索引的优点是节省空间,并且容易形成覆盖索引, 组合索引遵循最左前缀原则;要使用上组合索引索引上的所有索引,必须按顺序且中间不能漏,进行查询。
全文索引
非聚簇索引
MyISAM 存储引擎是非聚簇索引,数据和索引是分开存储的,数据存在.myd文件中,索引存在.myi文件中。
对于非聚簇索引来说,主键索引和二级索引下存的都是地址,再通过地址去找数据,因为索引和数据是分开存储的。
这里的 id 是主键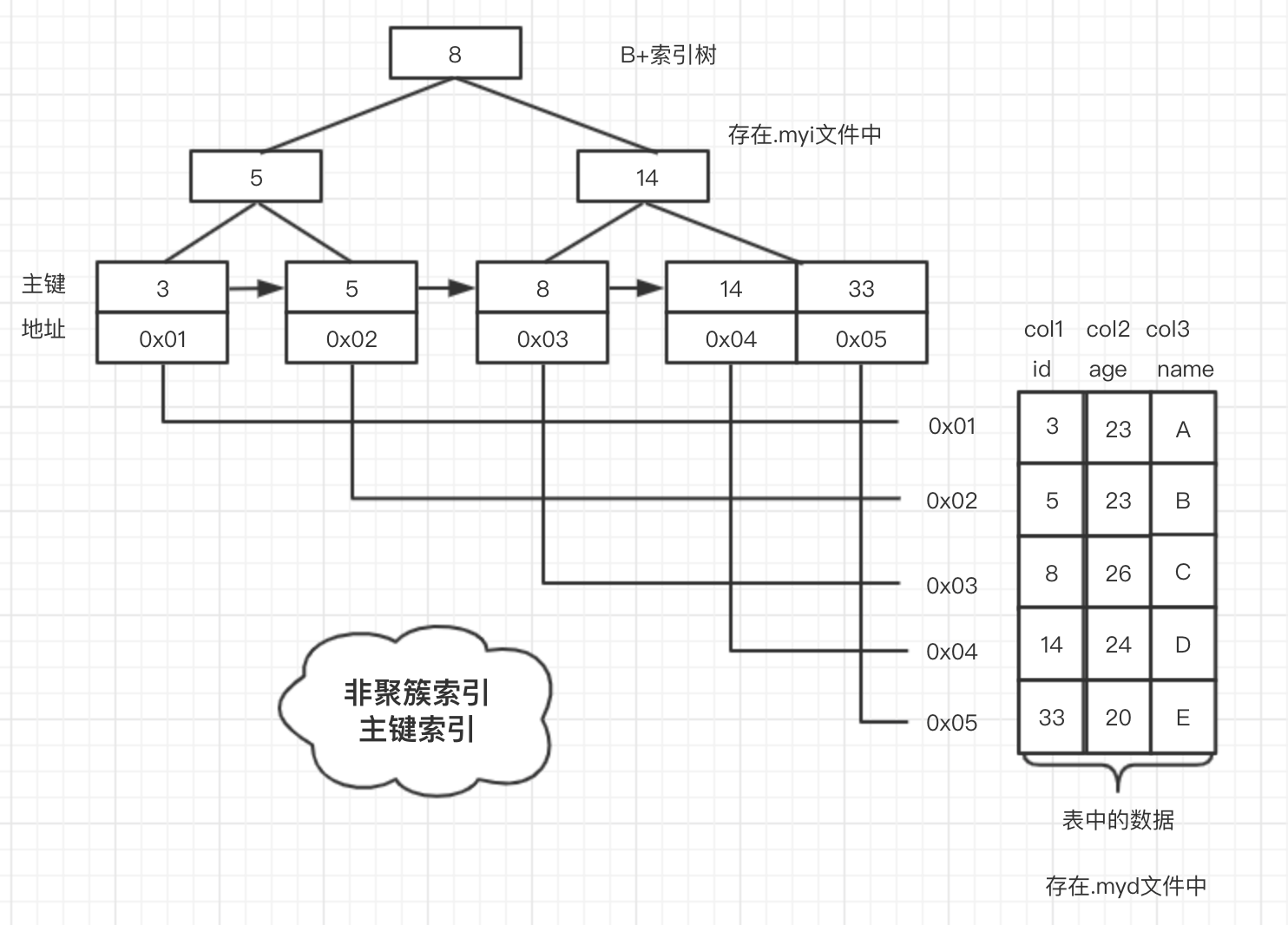
图片来源:画的我手疼的右臂
这里的 age 是一个二级索引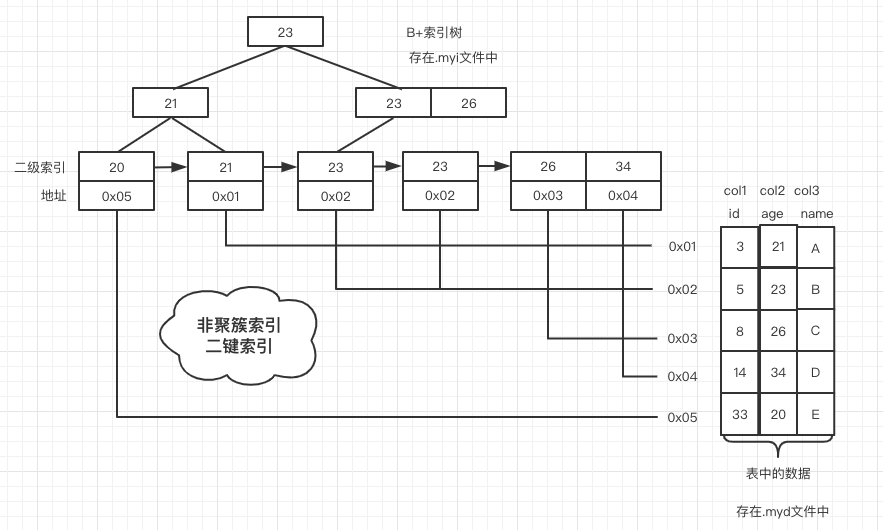
图片来源:画的我手疼的右臂
聚簇索引
InnoDB 是聚簇索引,数据和索引是在同一个.ibd文件中,也就是说在一棵树上。所有的数据直接存在叶子节点,节点只有索引,例如下图索引就是一些整数数字,这里的 id 是主键
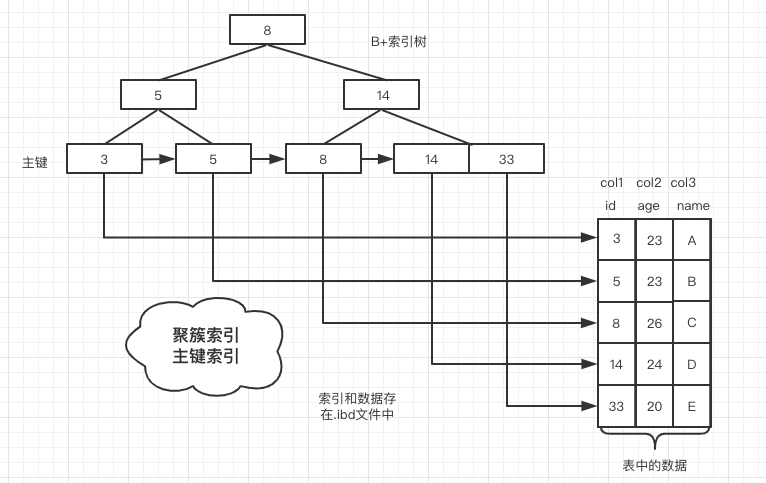
图片来源:画的我手疼的右臂
普通索引,非主键索引,在二级索引中,叶子节点存的是主键索引,这里 age 是一个普通索引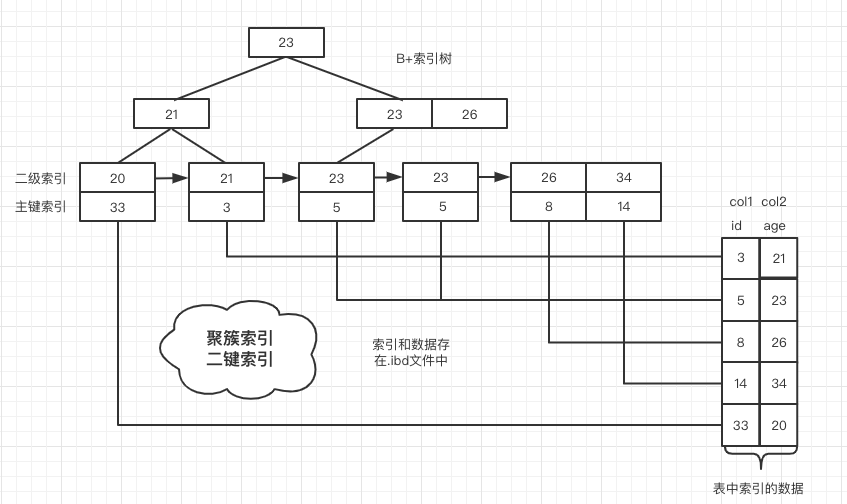
图片来源:画的我手疼的右臂
索引小结
- 尽量不要创建联合主键
- 一个索引就是一棵索引树
- 通过主键查找,主键下就是数据,所以查询速度快
- 通过二级索引查找其它数据,会发生回表操作
- 建好联合索引,利用覆盖索引,减少回表操作,常用的列放在左边
- 根据主键索引原理,删除主键索引,普通索引都会失效;修改主键索引的同时也会去修改所有普通索引,性能消耗大;而修改普通索引影响不大,但也还要在业务低谷期操作
- 如果用到自增主键索引,建议加上 unsigned
- 由于 change buffer 的关系,尽量使用普通索引
- 范围查询会使联合索引失效
- 不要使用 SELECT * ,要写具体的字段
- 建议使用 count(*),具体原因见文档
- 有索引不一定就会走索引,当二级索引+回表的代价比全表扫描代价小,才会使用索引。
- 这是一个查询的建议,在阿里mybatis查询的时候,即时是查询表中所有字段,也不能用 * 号返回,需要列出指定的列(具体原因暂时未了解)。
补充一些美团的使用经验:
1.最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。 2.=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式。 3.尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录。 4.索引列不能参与计算,保持列“干净”,比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create_time = unix_timestamp(’2014-05-29’)。 5.尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
索引存储结构
索引是在存储引擎中实现的,也就是说不同的存储引擎会使用不同的索引。MyISAM 和 InnoDB 存储引擎只支持 B+TREE 索引,Memory 存储引擎支持 HASH 和 BTREE 索引。
B+Tree 的高度一般为2-4,树的高度直接影响IO读写的次数,因此树的高度要尽量低。三层树就可以支持20G的数据,四层则可达到几十TB。
为什么三层树,而且只有叶子节点有数据(叶子节点以数据页为单位存的),就可以存放那么多条的记录呢?我们知道记录是存放在数据页中的(InnoDB中页是磁盘和内存交互的基本单位,一页大小是16KB,规定一页最少两条记录),然后又抽象出了目录项来存放存放数据页。假设一个B+tree的高度是3,假设一个数据页有100条记录,假设一个目录项有1000个数据页,那么就有 100 x 1000 x 1000 = 100,000,000 这样就可以存这么多了,然而实际上一个数据页可以放很多记录,或者再加一层呢!
B树和B+树的区别
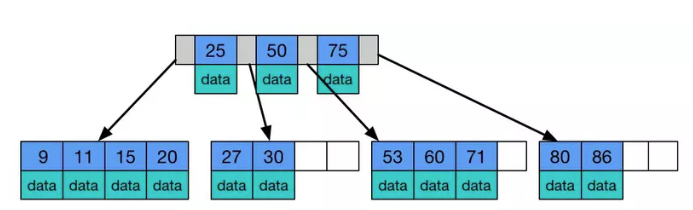
(B树)图片来源:网络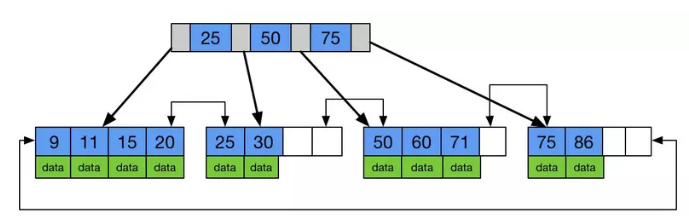
(B+树)图片来源:网络
B Tree 和 B+Tree 最大的区别在于非叶子节点是否存储数据,B树的叶子和非叶子节点都会存储数据,B+树只在叶子节点上存储数据,且存储的数据都在一行上,且数据是有序的。
EXPLAIN执行分析
可以通过 explain 关键字来分析 SQL 执行计划,然后进行适当的分析调优。
使用:
explain select * from tuser where age = 10;# 执行结果+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+| 1 | SIMPLE | tuser | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | Using where |+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
各字段注释
id
查询标识,每个查询都会分配一个唯一值;如果是null表示这是一个结果集,不会用来查询。
select_type
查询类型,有以下几种类型:
- SIMPLE,表示单表查询
- PRIMARY,表示此查询是最外层的查询
- SUBQUERY,子查询中的第一个select
- UNION,连接查询中,第二个查询是union类型
- DEPENDENT UNION, UNION 中的第二个或后面的查询语句, 取决于外面的查询
- UNION RESULT, 是UNION 的结果
- DEPENDENT SUBQUERY: 子查询中的第一个 SELECT, 取决于外面的查询. 即子查询依赖于外层查询的结果。
table
查询的表名,如果用了别名就显示别名;不涉及表就显示null;如果用<>括起来说明是临时表,里面的参数表示该结果来自某个id。
type
判断查询是否高效的重要依据,查询效率从高到底,只会用到其中一个索引,优化器会选出最优索引, 有以下几种类型:
- system,表中只有一行数据或者是空表
- const,使用了唯一索引或主键,代价可以忽略不计
- eq_ref,关联查询,连接字段是主键或是唯一索引
- ref,针对非唯一索引,使用等值“=”查询,或是使用了最左前缀规则索引的查询
- fulltext,全文搜索
- ref_or_null,
- unique_subquery
- index_subquery
- range,范围索引
- index_merge,k1和k2两个二级索引,select * from t where k1=1 and k2 = 2;这条sql会返回主键id,其中k1索引树找到符合条件的主键(1,2,3),k2索引树找到符合条件的主键(2),mysql会将这两个索引的主键id合并取交集得到主键(2),再去聚簇索引查找结果。这个过程称为index_merge;
- index,覆盖索引,不需要回表
- ALL,该类型不会使用索引,且数据是放在server层进行处理的,比存储引擎层处理慢
possible_keys
可能用到的索引
key
优化器最终选择的索引
key_len
看组合索引的使用情况,可以估算出大概用到了组合索引的多少个
ref
- 如果是常数等值查询,显示const
- 如果是连接查询,显示驱动表的关联字段
- 如果是条件使用了表达式或函数,或者发生了隐身转换,可能会显示func
rows
执行计划扫描行数,InnoDB不是精确的值,MyISAM是精确的值,这是因为InnoDB使用了MVCC机制。
Extra
显示额外一些重要信息,常见的有:
- null,出现这个效率最高
- distinct,表示select使用了distinct关键字;效率很低
- using filesort,排序时无法使用索引会出现;MySQL使用了外部文件排序;效率很低
- using index,查询时不需要回表查询,直接通过索引就可以获得数据;如果同时出现了using where表示索引用来执行查找值,没有出现using where说明索引是用来读取数据的;效率不错
- using where,出现这个表示数据在server层过滤,反之是存储引擎存过滤;效率较低
- using index condition,使用到了 索引下推,
连接查询
在连接查询中,左边的称为驱动表,右边的称为被驱动表。一般我们会用查询结果数据量小的那张表为驱动表,这样整体的查询次数就少了,这种也称为小表驱动大表。
一次查询中,驱动表只会返查一次,而被驱动表要查好几次,具体多少次要取决于驱动表查询了多少条记录。
连接有以下几种类型:
- 内连接
- 外连接
- left join
- right join
内连接和外连接一个较大的区别就是在内连接中如果驱动表 ON 条件不符合的记录不会放在结果集中。
内连接
格式:
- select * from t1,t2 on xxx
- select * from t1 inner join t2 where xxx
在内连接中 on 中的字句和 where 字句是一样的,所以一般不写 on。而且内连接中驱动表和被驱动的位置是可以互换的不影响结果。
外连接
格式:
- select * from t1 left join t2 on xxx
- select * from t1 right join t2 on xxx
锁
MySQL 提供了实现,InnoDB 引擎也提供了实现,InnoDB 的锁大多是基于索引的.
乐观锁
在程序中用版本号或时间戳来实现
悲观锁
表锁
可以自己手动加
意向锁
- 共享读锁,简称 S
- 排他写锁,简称 X
意向锁是为了解决表锁和行锁之间的矛盾,减少资源的浪费,提升性能。具体可以看何大举的这个例子:
举个例子,如果表中记录1亿条,事务A把其中有几条记录上了行锁了,这时事务B需要给这个表加表级锁,如果没有意向锁的话,那就要去表中查找这一亿条记录是否上锁了。如果存在意向锁,那么假如事务A在更新一条记录之前,先加意向锁,再加X锁,事务B先检查该表上是否存在意向锁,存在的意向锁是否与自己准备加的锁冲突,如果有冲突,则等待直到事务A释放,而无须逐条记录去检测。事务B更新表时,其实无须知道到底哪一行被锁了,它只要知道反正有一行被锁了就行了。
行级锁
InnoDB行锁是通过给索引项加锁来实现的,这意味着只有通过索引来检索的记录才会被加上行锁
共享读锁
需要我们手动加
select … lock in share mode
排他写锁
- MDL
元数据锁(meta data lock,MDL),该锁是自动加的,所有的CRUD都要先获取MDL锁,保证读写的正确性。释放则必须等一个事物提交后才会释放
- 读锁互不相斥
- 写锁,写锁互斥,一定要等另一个操作完成才可以执行,否则一直阻塞
要给一个表加字段时,为了业务正常运行,可以在alter table语句中添加拿MDL等待时间,拿不到就放弃,这样不会影响正常业务,之后再重复执行这个过程
- select … for update
事务
事物为了保证一组数据库的操作,要么全部成功,要么全部失败。。MySQL的事务是由存储引擎实现的,MyISAM不支持事务,InnoDB支持事务。
事务操作
事务的四大特性
- A(atomicity):原子性,事务最小工作单元,要么全成功,要么全失败。
- C(consistency):一致性,事务开始和结束后,数据库的完整性不会被破坏
- I(isolation):隔离性,不同事务之间互不影响
D(durability):持久性,事务提交后,对数据的修改是永久性的,即使系统故障也不会丢失
<br />隔离性是通过多版本控制机制和锁实现的的;原子性、一致性、持久性是通过InnoDB的 [redo log](#3GJrm)、[undo log](#4riYr) 和 [Force Log at Commit](#jDVHC) 来实现的
事务并发问题
事务并发操作会出现的一些问题:
- 脏读:读未提交隔离级别下,一个事物修改了还未提交或回滚,数据被另一个事物读取并修改提交了
- 不可重复读:在读未提交/读提交隔离级别下,事物A修改了数据未提交,事物B也修改了数据但提交了,这会导致事物A操作的数据与事物启动时的不一样
- 幻读:一个事务因读取到另一个事务已经提交的数据,导致对一张表读取两次以上的结果不一致,这里读专指新插入的数据
事务隔离级别
事务的隔离级别就是用来解决事务并发问题的。有以下四种隔离级别,隔离级别从低到高,越高性能越差:
- 读未提交(Read Uncommitted):一个事务还未提交,它的操作就能被其它事务看到;什么都解决不了
- 读提交(Read Committed):一个事务提交之后,它的操作才允许被其它事务看到;可以解决脏读
- 可重复读(Repeatable Read):这是默认隔离级别,一个事务执行过程中和这个事务启动时数据一致;可以解决脏读,不可重复度;(InnoDB 的 RR 隔离级别还可以解决幻读,这是因为 Gap Lock,只有 RR 级别才可以使用 Gap Lock)
- 串行化(Serializable):读和写都会加锁,排队执行;**
| 读未提交(Read Uncommitted) | 一个事务还未提交,它的操作就能被其它事务看到;什么都解决不了 |
|---|---|
| 读提交(Read Committed) | 一个事务提交之后,它的操作才允许被其它事务看到;可以解决脏读 |
| 可重复读(Repeatable Read) | 这是默认隔离级别,一个事务执行过程中和这个事务启动时数据一致;可以解决脏读,不可重复度;(InnoDB的RR还可以解决幻读,这是因为间隙锁,只有RR级别才可以使用间隙锁 |
| 串行化(Serializable) | 读和写都会加锁,排队执行;可以解决脏读、不可重复读、幻读 |
MVCC
多并发版本控制。只有在RR和RC隔离级别下才有MVCC,在MVCC并发控制中,读操作可以分为两类:
快照读:读历史版本(历史版本存在undo log),select,不加锁
当前读:特殊的读操作,update、delete、insert,需要加锁
也就是说:读不加锁,读写不冲突。
Read View是事务开启时,当前所有事务的一个集合,存储了最大事务ID和最小事务ID。
InnoDB 架构图
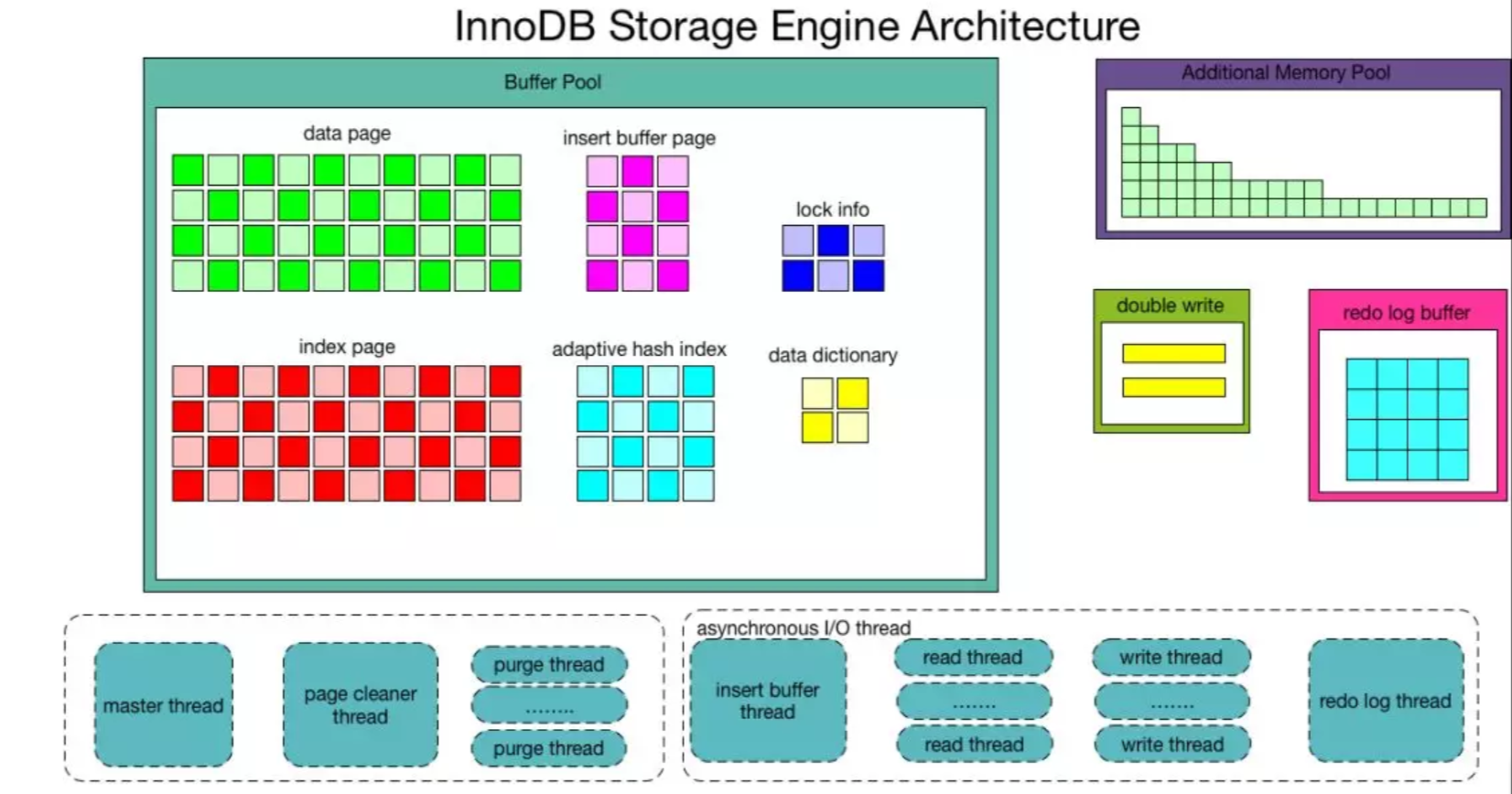
(InnoDB内部架构图)图片来源:网络
Buffer Pool
缓冲池,对数据进行缓存,默认是128M,理论上可以设置为内存的3/4或4/5,在my.cnf中配置,参数Innodb_buffer_pool_pages_free值越小,表示可用buffer空间越少
data page
数据页,是InnoDB存储的基本结构,也是InnoDB磁盘管理的最小单位,大小为 16KB。一个数据页中最少存两条记录。
index page
adaptive hash index
insert buffer page
lock info
data dictionary
redo log buffer
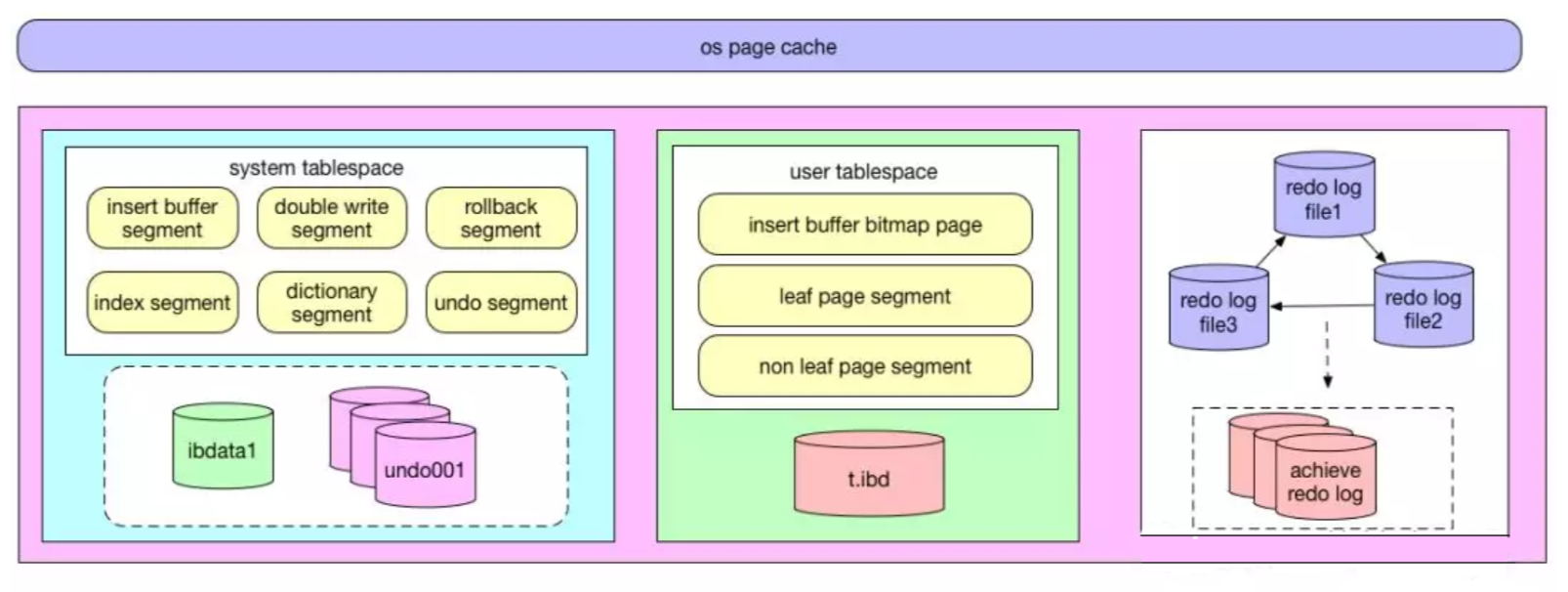
日志系统
错误日志(error log)
默认开启,MySQL运行过程中遇到的所有错误信息,5.7以后只能开启不能关闭。
二进制日志(binlog)
文件名举例:mysql-bin.000001,这个文件 MySQL 重启一次就生成一个 mysql-bin 文件。
该日志 Server 层实现的,binlog 是逻辑日志,所有引擎都可以用,该日志不限大小,会自动分割到新的文件,追加写,是逻辑日志所有引擎都可以用。
记录数据的变化,记录的是 ddl 和 dml 语句,但没有 select 语句,语句是以事件的形式保存,描述了数据的变更顺序,如果是 ddl 语句直接记录到 binlog 日志,而 dml 语句需要通过事务提交才能记录到 binlog 日志。
binlog 有三种模式,一种是 statement 记录 sql 语句;一种是 row 记录行的内容,如果是 update 操作会记录两条,分别是变更前和变更后。另一种是 mixed,是前两种的混合格式;例如删除十万行数据,statement 记录的是一条sql,而 row 记录的是十万行,可以看出 row 更占用空间,如果模式设置为 mixed,那么 MySQL会自己判断这条 sql 是否会引起主备不一致,然后来决定使用哪种模式来记录。
binlog 格式建议设置为 row,虽然占用空间,但是保存的信息更完整,误删数据后可以恢复。
作用
在数据备份、恢复、主从时使用。
写入流程
事务执行过程中,先把日志写到 binlog cache,事务提交的时候,再把 binlog cache 写到 binlog 文件中。
系统给 binlog cache 分配了一片内存,每个线程一个,参数 binlog_cache_size 用于控制单个线程内 binlog cache 所占内存的大小。如果超过了这个参数规定的大小,就要暂存到磁盘。
通用查询日志(general query log)
保存所有记录,耗性能,默认关闭。
慢查询日志(slow query log)
默认关闭,需要配置。
重做日志(redo log)
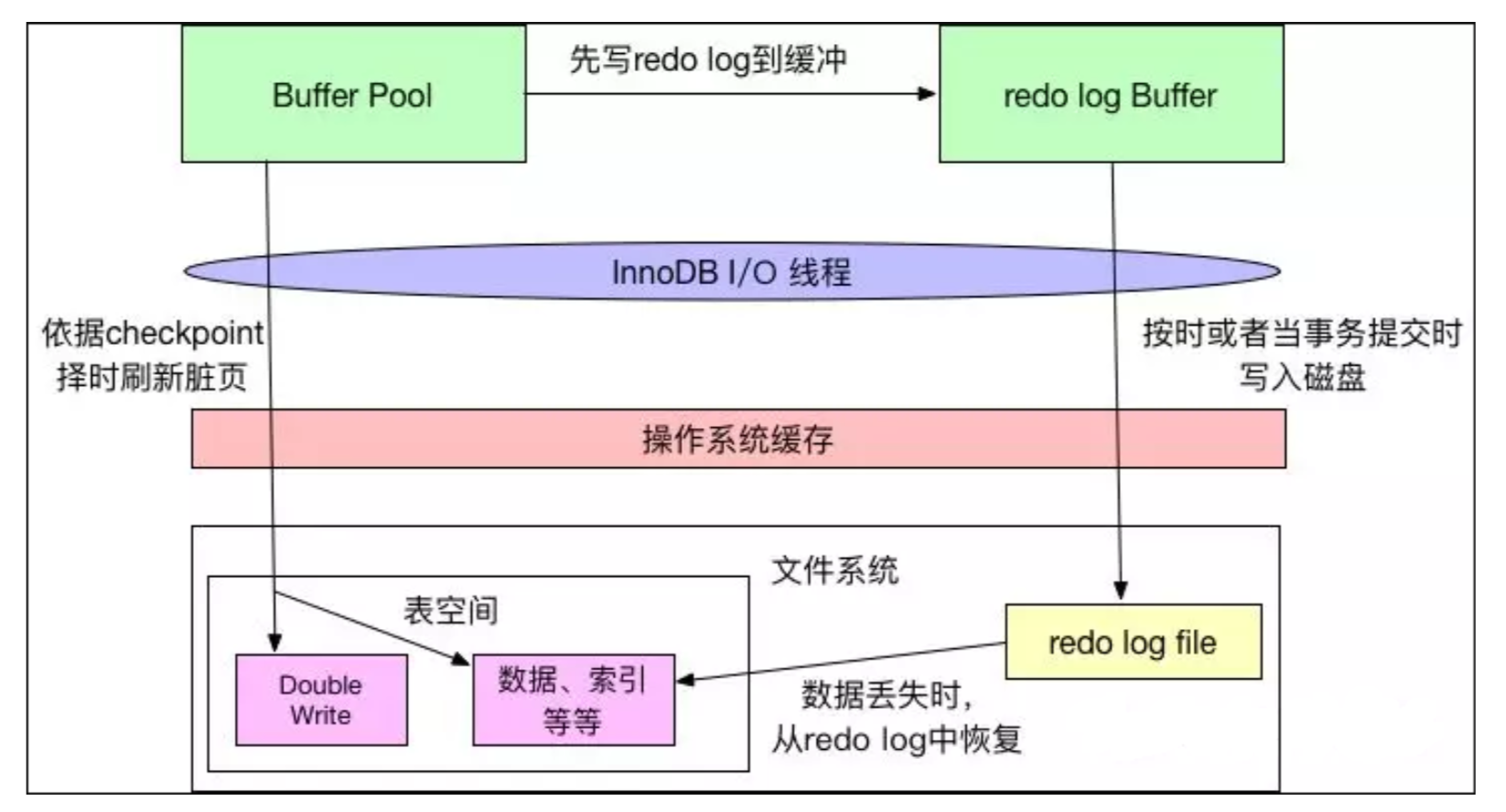
重做日志,redo log 日志是 InnoDB 特有的日志,它是是物理日志。文件名举例:ib_logfile0、ib_logfile1。
当要保存数据时,InnoDB会先把数据写到redo log中,并更新内存,在空闲的时候再更新到磁盘,这是因为redo log写是顺序IO,而写入磁盘是随机IO,因此redo log更快。
redo log日志容量是固定的,从头部开始写,写到尾部如果满了,就清除头部的日志,但是清除之前会写到磁盘中,然后又从头部开始写。
MySQL异常崩溃恢复默认用的是redo log,redo log保证了数据的可靠性。如果是MySQL服务器的磁盘有几个TB,建议将redo log设置为1GB,redo log太小WAL机制的能力就发挥不起来。
可以通过 innodb_log_buffer_size 参数设置 redo log 文件的大小。
innodb_flush_log_at_trx_commit 该参数可以配置刷新到 redo log 策略,默认为1(强烈建议,特殊情况会设置为2),只要发生commit操作就从redo log buffer刷新到redo log文件中,还可以是0和2。0表示发生commit操作先写到redo log buffer中缓存,然后固定时间刷新到redo log文件中;2表示发 commit操作先写到操作系统缓存中,然后固定时间刷新到redo log文件中。
数据库崩溃重启后需要从redo log中把未写入磁盘的脏页数据恢复出来,重新写入磁盘,保证用户的数据不 丢失。当然,在崩溃恢复中还需要回滚没有提交的事务。由于回滚操作需要undo log的支持,undo log的完整性和可靠性需要redo log的支持,所以崩溃恢复先用redo log恢复数据,然后做undo log回滚。
回滚日志(undo log)
undo log用于存放数据修改前的值,可以使用undo log来实现回滚操作,保证事务的一致性。undo log的内容为了保证持久性也要记录到redo log中。文件名举例:ibdata1。
例如:将age=15修改为12,update tb_user set age = 12 where age = 15;
- 事务开始
- 查询待更新数据放到内存,加写锁
- 记录undo log相关的redo log到缓冲
- 记录undo log到缓冲
- 记录数据变更相关的redo log到缓冲
- 内存更新数据形成脏页
- 事务commit触发redo log刷磁盘,InnoDB每秒也会触发redo log刷磁盘
- 在该步骤之前崩溃,恢复后会进行回滚
- 在该步骤之后崩溃,恢复后使用redo log恢复数据
- undo log页和脏页根据checkpoint机制刷盘
中继日志(relay log)
当使用主从复制时,中继日志会记录主库bin log 发送过来的数据性能分析调优
- 慢查询日志
- 借助分析工具
- 减少落盘次数
- 增大buffer pool空间
读写分离
可以使用mysql-proxy、Mycat
分库分表
数据库性能优化,其它都是小打小闹,真正提升性能需要分库分表。
背景:MySQL单表的数据在一千万左右,性能下降非常厉害,这时需要对数据进行拆分,有水平拆分和垂直拆分两种方案。
数据sharding方案
水平切分
水平切分是按行切分,假设单表数据有一千万,将它拆分到3个库中,每个库只有三百多万数据,这样性能提升很明显。
水平切分规则
- 按ID取模
- 按日期
- 按范围
切分规则
- 能不切就不切,需要处理很多问题
- 如果一定要切分,一定要提前规划好,否则后续数据问题很头疼
- 适当的数据冗余来降低跨库join的可能
垂直切分
垂直切分是按字段或按表来拆分,对性能提升不明显,不能从根上解决问题
分库
分表
将一个大表拆分成若干个小表
分库分表带来的问题
- 分布式事务问题,解决的方案较多,常见有补偿事务等
- 主键不冲突问题,解决方案也较多,常见的有uuid、redis incr命令等
- 跨库join问题,常见的有建立全局表(每个库都有一个相同的表,该表数量要小)、代码表;实在要跨库,最低两张表跨库
分库分表技术
Sharding-JDBC分库分表Demo
参考另一篇文章
常用SQL/命令
MySQL登录
# 本登录,默认ip 127.0.0.1,port 3306mysql -u用户名 -p密码# 登录远程mysql -h ip -P port -u用户名 -p密码
表操作
# 案例:创建用户表CREATE TABLE `user` (`id` int(11) unsigned NOT NULL auto_increment,-- 这里的varchar(40)表示40个字节,能存多大取决于字符集格式`username` varchar(40) NOT NULL COMMENT '用户名称',`password` varchar(200) NOT NULL COMMENT '密码',PRIMARY KEY (`id`),UNIQUE key username (`username`),key idx_name_pwd (`username`,`password`)) ENGINE=InnoDB COMMENT='用户表';# 查看所有表show tables;# 查看某个表的详细信息show table status like '表名称';# 查看建表语句show create table 表名;# 查看表结构desc 表名;# 删除表drop table 表名# 添加列alter table 表名 add 列名 类型 约束 comment '描述'# 修改列的长度和约束alter table 表名 modify 列名 类型(长度) 约束;# 修改列名alter table 表名 change 旧列名 新列名 类型 约束;# 删除列alter table 表名 drop 列名;# 修改表名rename table 表名 to 新表名;# 修改表的字符集alter table 表名 character set 字符集;# 重建表,不会写日志truncate table 表名# 更改表的引擎。注意的是这个会很慢,具体原因你懂的,所以一个# 好的方案是新建个表,然后把数据复制过去或者也可以在业务低峰期处理# 还有一个方案:insert into 新表名 select * from 旧表名; 这样也可以alter table 表名 engine = InnoDB;
索引操作
# 查询表的索引show index from 表名;# 删除索引drop index 索引名称 on 表名;# 添加单列索引create index 索引名称 on 表名(列名);alter table 表名 add index 索引名称 (列名);# 添加唯一索引create unique index 索引名称 on 表名(列名);alter table 表名 add unique index 索引名称 (列名);# 添加全文索引create fulltext index 索引名称 on 表名(列名);alter table 表名 add fulltext index 索引名称 (列名);# 添加组合索引alter table 表名 add index 索引名称 (列名1,列名2,...);
授权操作
# 案例一:创建用户名:root,密码:root;ALL PRIVILEGES表示所有权限;*.*表示所有库,所有表;# % 表示任意ip,GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root';# 案例二:创建用户名:test,密码:123456a,只有查询的权限grant select on *.* to 'test'@'%' Identified by '123456a';# 刷新权限FLUSH PRIVILEGES;# 查看用户名test的授权语句show grants for test;
数据库操作
# 创建数据库create database 数据库名 character set 字符集;# 查看所有数据库show databases;# 删除数据库drop database 数据库名称;# 切换数据库use 数据库名称;
查看配置
# 查看当前 MySQL 版本SELECT version();# 查看所有日志文件信息show variables like 'log_%';# 查看数据文件信息show variables like '%datadir%';# 一个sleep线程超过多久后会断开,默认是8小时show variables like '%wait_timeout%';# 一个MySQL实例连接上限,超过会提示Too many connectionsshow variables like '%max_connections%';# 查看系统状态信息# Command列显示当前连接操作信息;# Sleep列表示空闲无任何操作,默认8小时会断开# state列是当前执行状态,如果是waiting for table fulsh要把它kill掉,以免对后面进行阻塞show processlist# 查看线程连接情况show status like 'Threads%';# 设置为1,表示每次事物的binlog都将直接持久化到磁盘,即使Mysql异常重启数据也不会丢失show variables like '%sync_binlog%';# 查看具体一个mysql-bin.000001 binlog日志文件操作信息show binlog events in 'mysql-bin.000001'# 查看是否打开,设置为ON可以让死锁中其中一个事务回滚show variables like '%innodb_deadlock_detect%';# 查看一个线程阻塞的时间,默认是50秒,超过会自动断开show variables like '%innodb_lock_wait_timeout%';# 设置为ON,表示关闭间隙锁,此时一致性会被破坏(所以是unsafe),反之show global variables like "innodb_locks%";# 查看 InnoDB 死锁情况show engine innodb status;# 查看change buffer在buffer pool中的大小,25表示占用25%show variables like '%innodb_change_buffer_max_size%';# 查看buffer_pool大小,默认是128M,单位是Bselect @@innodb_buffer_pool_size;# 查看慢查询的阈值,单位msshow variables like '%long_query_time%';# 查看flush脏页有关,SSD设备建议设置为0,在8.0版本该参数默认为0show variables like '%innodb_flush_neighbors%';# 查看一条SQL执行字符集转换等信息,前提是需要执行完一条explain语句,再执行该命令show warnings;# 从information_schema库中的innodb_trx事物表中查询事物,这里是大于60sselect * from information_schema.innodb_trxwhere TIME_TO_SEC(timediff(now(),trx_started))>60;
锁操作
# 查看表级锁状态变量# Table_locks_immediate产生表级锁的次数;Table_locks_waited争用表级锁等待的次数show status like 'table%';# 添加表读锁,当前session需要释放该表后才可以查其它的表,因为表锁的粒度太大了,占用资源# 加了表读锁后不能加表写锁,会报错或一直阻塞等待读锁释放# -----# 添加表写锁,当前session需要释放该表后才可以查表,因为表锁的粒度太大了,占用资源# 加了表写锁后,其它session不能写,会阻塞等待锁释放lock table 表名称 read/write,表名称2 read/write,...;# 查看表锁情况show open tables;# 释放表锁unlock tables;# 查看行锁状态# Innodb_row_lock_current_waits:当前正在等待定的数量;# Innodb_row_lock_time:从系统启动到现在锁定总时间长度;# Innodb_row_lock_time_avg:每次等待所花平均时间;# Innodb_row_lock_time_max:从系统启动到现在等待最常的一次所花的时间;# Innodb_row_lock_waits:系统启动后到现在总共等待的次数;show status like 'innodb_row_lock%';
事务操作
# 开启事务begin;或start transaction;# 提交事务commit;# 回滚事务rollback;# 查看事务隔离级别show variables like '%transaction_isolation%';# 设置当前会话隔离级别为:读未提交(全局需要在配置文件中修改)# 另外还有三种read committed, repeatable read,serializableset session transaction isolation level read uncommitted;
常用参数
大小写敏感
在my.cnf中配置lower_case_table_names,1不敏感,0敏感
默认字符集
在my.cnf中配置character-set-server=utf8
开启通用日志
在my.cnf中配置general_log_file=文件路径
开启慢查询日志
在my.cnf中配置low_query_log,ON开启,OFF关闭
long_query_time配置慢查询时间,单位秒
slow_query_log_file=文件路径 记录慢查询语句
字符集比较
MySQL 中的 utf8mb4 其实就是 utf8 字符集。然后我们平常设置的 collation 为 utf8_general_ci 表示采用 utf8 通用比较方式, _ci 表示忽略大小写,_cs 区分表示大小写。
collation 字符比较可以设置在列、表、数据库、服务器这4个级别。
varchar(65535) 表示最多能存65535个字节,如果该列没有 not null表示,那么需要消耗1个字节来标识 NULL,而真实的长度用需要消耗2个字节来标识,所以varchar类型最多能用的是65532字节。
到底能存多少?还需要根据字符集来计算,例如utf8能用1、2、3字节来表示一个字符,那么理论上最少能存65532/3等于21844个字符。
名词解释
物理分页
在数据库中就已经分好页了,返回分页结果
逻辑分页
将数据库中的数据查询到内存后,再进行分页
物理日志
物理日志只有自己看得懂。InnoDB的redo log就是物理日志,它记录的每个数据页的修改
逻辑日志
逻辑日志大家都看得懂。Server层的bin log是逻辑日志,它会记录一条sql的原始逻辑,比如给用户A加了多少资产,记录的是具体的一条sql
顺序IO
需要记录首地址和偏移量,只追加,记录速度快,但是浪费空间
随机IO
需要记录地址,速度慢,但是省空间
.frm文件
InnoDB/MyISAM:存放与表有关的数据信息,存放在文件夹为表名的目录下
.ibd文件
InnoDB:使用独享表空间存储数据和索引信息,一张表对应一个ibd文件
MyISAM:主要存储表数据信息
.ibdata文件
InnoDB:使用共享表空间存储表数据和索引信息,即所有的表共用一个或多个ibdata文件
.myd文件
MyISAM:用来存储表数据信息
.myi文件
MyISAM:主要存储表数据文件中所有索引的数据树
回表
普通索引查找其它数据,会先到普通索引树拿到主键索引的值,再根据主键索引的值去主键索引树找,这个过程称为回表,回表发生了两次查询。
覆盖索引
某个索引已经包含了要查询的内容不需要去进行回表操作,这个索引称为覆盖索引,主键就是典型的覆盖索引
前缀索引
MySQL支持将字符串的一部分作为索引,默认是全部。
# 案例:将邮箱147391@qq.com前面6个字节创建索引,可以节省空间,但可能要多扫描行数alter table user add index (email(6))
最左前缀原则
一个组合索引:idx_age_name,最左边的age索引是可以和普通索引一样使用,但是后面的name索引是不起作用的;字符串索引的前N个字符也符合最左前缀原则。因此like '%常量'这样的写法是不会使用索引的;遇到范围查询(>,<,between)会导致索引失效。
# 案例:表t_user有组合索引:idx_a_b_c_d# 这里只会用到索引a和b,d不会用到,因此c这里导致索引失效了# 但实际上优化器会进行优化,可能还是会用到这个联合索引select * from t_user where a = 1 and b = 1 and c < 1 and d = 1;
索引下推
Mysql5.6以后,引入了索引下推优化,在联合索引中对包含的字段先做判断,在存储引擎就可以判断,而不需要返回给 server 端,减少了回表的次数
间隙锁
gap lock,它不会锁记录本身,而是会封锁索引记录中的间隙,只阻塞插入。是为了解决幻读引入了,只在 RR 隔离级别下有用。
那加间隙锁的条件是什么?
首先肯定要在 InnoDB 引擎 RR 隔离级别下。如果 id 是 pk,且有数据为 1,4,10,12
如果条件是范围那么就会在这个范围中加间隙锁 ,例如:
select * from t where id > 10 for update;
间隙锁范围在(10,12)
业务中有一种情况需要注意,当 update/delete 一行记录 where 条件没有索引,就会进行全表扫描不仅会加给每条记录加 X 锁,还会在所有的记录之间加上间隙锁,加锁本身就是消耗资源的,而且会导致该表不能发生 update/delete/insert 操作,这是非常恐怖的,一定要注意!
如何判断一条sql加了哪些锁?
这里以 RR 级别为例,表信息如图。**delete from t where id = 10** ,其中 id 是个普通二级索引,那么这条 sql 的加锁情况如下:
首先扫描 id 这个索引树,找到所有符合条件的,也就是图中有 2 条,普通索引会加上间隙锁,间隙锁的数量是 3 个,然后是 delete 写操作会加 X 锁,也就是 2 个,再根据二级索引找到主键,写操作主键行也会加上 2 个 X 锁,所以总共是 7个锁,3个间隙锁,4个X锁。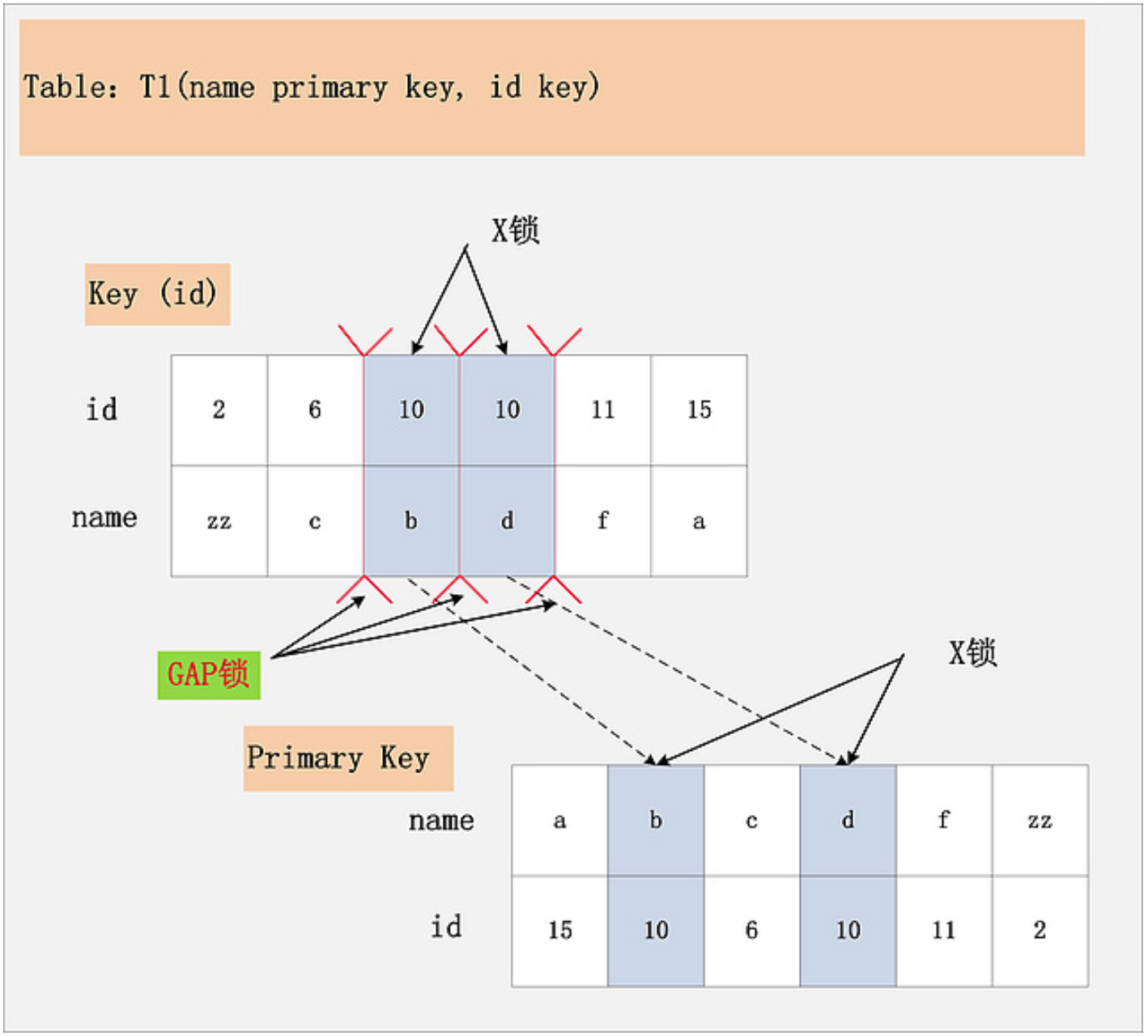
图片来自何大的博客
临键锁
next-key lock,是记录锁和间隙锁的结合。它的封锁范围,既包含索引记录,又包含索引区间。
脏页
页是 InnoDB 存储的基本结构,InnoDB 缓存在页中的数据和磁盘的数据不一致,该页称为脏页。
WAL
Write-Ahead-Logging,预写日志,当事务提交时,InnoDB会先将 数据写入redo log中
MVCC
多版本并发控制,普通读不加锁,读写不冲突
大事务
一个事务的执行过程非常的长,这种情况会影响性能,如果不能避免最好在业务低峰期操作并切分为小事务。例如删除很多的数据。
事物视图
在可重复读中,会为每一个事物生成一个当前表数据的独立视图,只有当事物结束才会删除,如果一个表数据很大,长事物特别的占用内存空间
change_buffer
更新数据页的代价比较大,在不影响数据一致性的情况下,会先缓存到change buffer中,这样就不需要去磁盘中读取数据页了,下次访问这个数据页的时候,再将change buffer中与这个页有关的数据进行merge。所以说change buffer可以减少读磁盘访问,大大提高性能。但是唯一索引要保证唯一性约束所以用不到change buffer。
join_buffer
是在执行连接查询前申请的一块内存。将驱动表的结果放在该内存中,然后从内存取出记录和被驱动表匹配,大大减少了被驱动表I/O次数。默认是256KB,所以在平常使用中驱动表查询结果不要用 *,而是指定具体的列。这样可以节省内存。
数据页
数据页是InnoDB管理数据的最小磁盘单位,因为内存和磁盘的读写差了好几个数量级,所以MySQL使用数据页作为磁盘和内存交互的基本单位。默认页大小是16KB,每页至少存储2条或2条以上的行记录。所以说数据记录不是直接存在内存中的,而是通过页的形式存在于内存中。
数据页与数据页物理上并不是连续的,而是通过上一个页记录下一个页的编号,维持了链表的结构。并且下一页中的记录主键必须大于上一页中的记录主键。
每个数据页都会标记该页所有记录中最小的主键值,如果根据主键来查找记录,可以通过二分法确定该记录是放在哪个页中。然后再去页中通过二分法找记录。
实际上MySQL的CRUD操作,先要找到具体的数据页,然后再找记录,都是发生在数据页中的。
页裂变
数据页与数据页物理上并不是连续的,而是通过上一个页记录下一个页的编号,维持了链表的结构。并且下一页中的记录主键必须大于上一页中的记录主键。如果某个数据页插入一条记录,但是该记录的主键值比下一页的主键值还大,那么需要进行移动来维护这个状态,这个过程叫做页裂变
两阶段提交
两阶段提交是为了保持redo log和bin log两个日志的一致性,事务有两种状态分别是prepared 和 commit,如果崩溃恢复时,对于prepared状态的事务会先判断binlog中是否有写入,如果binlog有就commit,没有成功写入就回滚。
两阶段锁协议
行锁是自动加上去,但是释放要等一个事物提交才会释放。如果在事务开始就锁住,会加大阻塞的可能性,实际应用中应该尽量往后放,减少持有锁的时间。
死锁
多个线程相互之间互相等待对方资源释放,会导致死锁。死锁会消耗大量的CPU资源
Force Log at Commit
该机制实现事务的持久性,即当事务提交时,必须先将该事务的所有日志写入到redo log文件进行持久化,然后事务的提交操作完成才算完成。为了确保每次日志都写入到重做日志文 件,在每次将redo log buffer写入redo log后,必须调用一次fsync函数(操作系统),将缓冲文件从文件系统缓存中真正写入磁盘。
Double Write
双写,为InnoDB的数据源提供了数据页可靠性。
information_schema
这是 MySQL 特殊的一个库,里面存放许多其他数据库表,权限之类的信息。
面试题
一条查询SQL的执行顺序
FROM -> ON -> JOIN -> WHERE -> GROUP BY ->SELECT -> DISTINCT -> ORDER BY -> LIMIT
分页查询从100万条开始查询20条怎么优化
- 可以利用子查询 ```sql
SELECT * FROM log_history WHERE id > (SELECT id FROM log_history LIMIT 1000000,1) LIMIT 100
2. 使用between先选择一个范围```sqlSELECT * FROM log_history WHERE id BETWEEN 1000000 and 1000100 LIMIT 100
- where条件判断 ```sql
SELECT * from log_history WHERE id > 1000000 LIMIT 100 ```
索引失效的场景有哪些
- 使用了范围查找
<、>会导致右边的所有失效 - 使用了
like '%常量', - 关联查询关联字段没有索引【demo演示】
- 在索引列上使用了函数
- 使用了
!=或<> - 主键上使用了
is null,is not null,但普通索引不会失效 - 隐式字符编码转换,主要发生在表关联之间,表的编码不同
- 隐式转换,
where ID=10,id是字符串类型,相当于使用字符串转整型,不用索引;而整数转字符串会用到索引【demo演示】 - 如果查询中没有条件查询,仅仅是
order by create_time,那么create_time有索引也不会用到 - 用
or来连接会导致索引失效 - MySQL 觉得全表扫描的代价比用索引小,那么也不会用索引
- 复合索引不满足最左匹配原则
存储引擎InnoDB和MyISAM的区别,优缺点,使用场景
| 比较类型 | InnoDB | MyISAM |
|---|---|---|
| 存储文件 | .frm 记录表定义文件 .ibd 记录数据文件和索引文件 |
.frm 记录表定义文件 .myd 记录数据文件 .myi 记录索引文件 |
| 锁 | 表锁、行锁 | 表锁 |
| 事务 | 支持 | 不支持 |
undo log和redo log区别
redo log,重做日志,当要保存数据时,InnoDB会先把数据写到redo log中,并更新内存,在空闲的时候再更新到磁盘,这是因为redo log写是顺序IO,而写入磁盘是随机IO,顺序IO更快。
undo log,回滚日志,用于存放数据修改前的值,可以使用undo log来实现回滚操作,保证事务的一致性。
什么是死锁及死锁的排查和解决
多个线程相互之间互相等待对方资源释放,会导致死锁。如果发现死锁,回滚其中一个事务,让其它事务继续执行。
可以通过该命令查看死锁情况:show engine innodb status;
MySQL 避免发生死锁,就需要对加锁规则了解清楚,可以参考该博客了解加锁规则,从而能够预防死锁发生和定位死锁问题。
事务的实现原理
事务有四大特性,分别是:
- 原子性
- 一致性
- 隔离性
- 持久性
原子性:原子性靠的是是 undo log 来实现的,undo log 会保存每条写操作之前的数据,便于回滚。
一致性:
隔离性:隔离性是靠 MVCC 多并发版本来实现的
持久性:持久性是靠 redo log 来实现的,它是顺序 io 刷盘快,但是它容量有限,会循环覆盖。崩溃恢复时先会加载 redo log,把脏页数据写入磁盘中,如果是未提交的会用 undo log 进行回滚。
MySQL索引的数据结构是什么
B+ 树,它的特点是数据只存在叶子节点中,且是有序的。
InnoDB中如果表没创建主键会怎么处理
会找一个非空唯一索引代替,如果没有唯一索引,就自动生成一个伪列 row_id 来当主键
怎么优化select * 查询所有数据
- SQL末尾加
order by id跳过全表扫描,直接从B+树的叶子节点开始获取 - 所有字段建成组合索引(不推荐该做法,可以算是一种思路)
描述下一条SQL的执行流程
- 客户端先通过连接器连接到 MySQL 服务器;
- 连接器权限验证通过之后,进入分析器;
- 分析器会对查询语句进行语法分析和词法分析,判断 SQL 语法是否正确,如果查询语法错误会直接返回给客户端错误信息,如果语法正确则进入优化器;
- 优化器是对查询语句进行优化处理,例如一个表里面有多个索引,优化器会判别哪个索引性能更好;
- 优化器执行完就进入执行器,执行器则开始执行语句进行查询比对了,直到查询到满足条件的所有数据,然后进行返回。
主备延迟如何处理?
- 判断二者硬件设备是否一致
- 备库可以将
innodb_flush_log_at_trx_commit和sync_binlog设置为双非1,例如分别设置为 2 和 1000。 - 看主备库的 CPU 负载压力
- 主备库参数是否一致
主从同步如何处理?
- 主库 DML 并发大,从库 qps 高
- 从库配置差或者 io 资源不够
- 主从参数不一致
- 主库有大事务操作
- 从库空间不足
给一条 SQL 说下在 InnoDB 中的加锁情况 delete from t1 where id = 10;
先要判断是在 RC 还是 RR 隔离级别,然后判断 id 的索引情况。具体可以参考大佬的博客。这道题能回答完整我觉得对索引和锁掌握的不错。

若有收获,就点个赞吧
0 人点赞
