开始接触 ES 还没熟悉它的一些 CRUD,这里记录一下,方便查看
增
删
查
排序
- 对多个字段进行排序
POST /索引/_search{"size": 5,"query": {"match_all": {}},"sort":[{"order_date":{"order":"desc"}},{"_doc":{"order":"asc"}},{"_score":{"order":"desc"}}]}
改
查
查看集群健康状态:GET /_cluster/health
查看所有节点:GET /_cat/nodes
查看文档总数:GET _count
查看所有索引的内容,只返回10条,可以查看文档格式:GET /_search
查看某个索引的内容,只返回10条:GET /{索引名称}/_search
查看所有索引:GET /_cat/indices
查看指定索引名称的内容:GET /索引1,索引2/_search
查看模糊匹配所有索引内容:GET /索引名称*/_search
简单查询某个索引指定字段:GET /索引名称/_search?q=field1:value1
简单查询某个索引不指定字段(泛查询):GET /索引名称/_search?q=value1
查询一个指定的文档id:GET {索引名称}/{类型}/{文档id} ,默认类型是 _doc
简单查询举例:GET /movies/_search?q=2012&df=title&sort=year:desc&from=0&size=10
// 查询movies索引中有 2012 的单词,df不指定就会对所有字段进行查询,sort用来排序// from,size 用来分页,profile 用来查看查询时如何执行的{"profile": "true"}
查询所有:GET /users/_search
{"query":{"match_all":{}},"size":1 // 只返回一条内容}
创建一个文档自动生成id:POST {索引名称}/{类型} ,默认类型是 _doc
{"user" : "Mike","post_data": "2019-10-12 22:23:22","message": "trying out Kibana"}
更新一个指定的文档id:PUT {索引名称}/{类型}/{文档id} ,默认类型是 _doc
{"user" : "Jack","post_data": "2019-10-12 22:23:22","message": "Jack trying out Kibana"}
添加一个指定文档上的字段:POST {索引名称}/_update/{文档id}
{"doc": {"post_date": "2019-10-13 22:23:22"}}
批量更新/添加索引bulk操作:POST /{索引名称}/_bulk ,这里的json格式不能是pretty的
{ "index": {"_id": 1}} // id 是1{ "title": "Father of the Bridge Part II", "year":1995,"genre":"Comedy"} // 内容{ "index": {"_id": 2}} // id 是 2{ "title": "Dave", "year":1993,"genre":["Comedy","Romance"]} // 内容
批量获取mget操作:GET _mget
{"docs":[{"_index":"user", // 获取索引是user,id是1的文档"_id":1},{"_index":"comment", // 获取索引是comment,id是1的文档"_id":1}]}
批量查询 msearch:POST users/_msearch
{}{"query":{"match_all":{}},"size":1}}{"index":"users"}{"query":{"match_all":{}},"from":1,"size":2}}
查询某个字段的范围:GET products/_search
{"query": {"constant_score": {"filter": {"range": {"price": { // 查找价格"gte": 20, // 大于等于20"lte": 30 // 小于等于30}}}}}}
查询包含某个字段:POST /{索引名称}/_search
{"query": {"constant_score": {"filter": {"term": {"genre.keyword": "Comedy" // 查询genre中包含Comedy的文档记录}}}}}
bool多条件查询:POST /{索引名称}/_search
{"query":{"bool": {"should": [{"match": {"title": { // 查询title这个字段"query": "apple,iPad","boost": 1.1 // boost 相关性打 分,该值越高,得分就越高}}},{"match": {"content": { // 查询 content 这个字段"query": "apple,iPad,apple,iPad","boost": 1}}}]}}}
删
删除某个索引:DELETE 索引名称
增
给某个索引批量添加数据:
# articles 是索引POST articles/_bulk{ "index": {}}{ "body":"lucene is very cool"}{ "index": {}}{ "body":"elasticsearch builds on top of lucene"}{ "index": {}}{ "body":"elastic is the company behind ELK stack"}{ "index": {}}{ "body":"ELK stack rocks"}{ "index": {}}{ "body":"elasticsearch is rock solid"}{ "index": {}}{ "body":"elasticsearch is rock solid","title":"test-title"}
简单查询
查询所有
查询某个索引中的
查询多个索引中的
分片查询
from 表示从第几个开始;’size 表示返回数量,默认10。
GET /movies/_search?from=1&size=2
轻量搜索
所有索引为movies下title字段有Them的文档记录
GET /movies/_search?q=title:Them
请求体查询
query 参数
查询 last_name 属性值为 Smith 的文档记录
GET /_search{"query" : {"match" : {"last_name" : "Smith"}}}
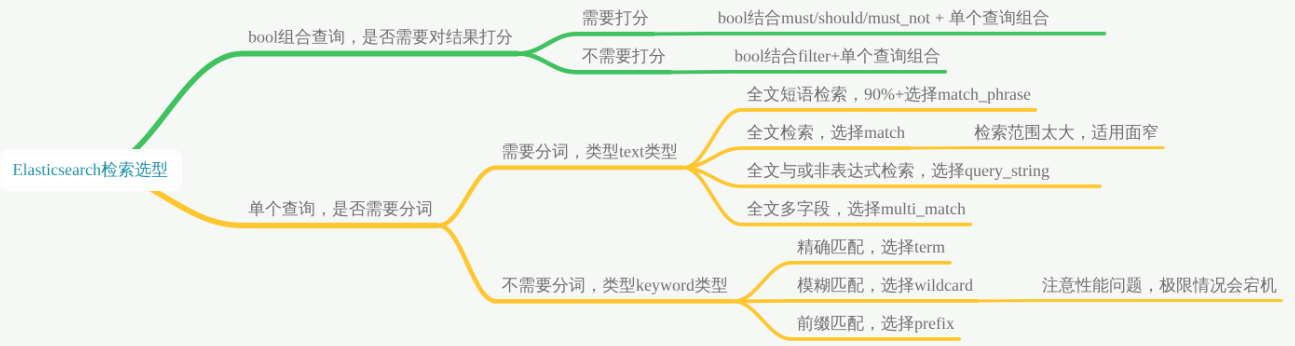
match:精确查询或全文搜索,term 之间是 or 关系
GET /movies/_search{"query" : {"match": {"title": "Werewolf"}}}
match_all:查询简单的匹配所有文档。在没有指定查询方式时,它是默认的查询
match_phrase:term 之间是 and 关系,并且 term 之间的位置也影响查询结果
match_phrase_prefix:
multi_match:
bool 参数
可以组合和嵌套,有4个子句,两种会影响打分,两种不影响打分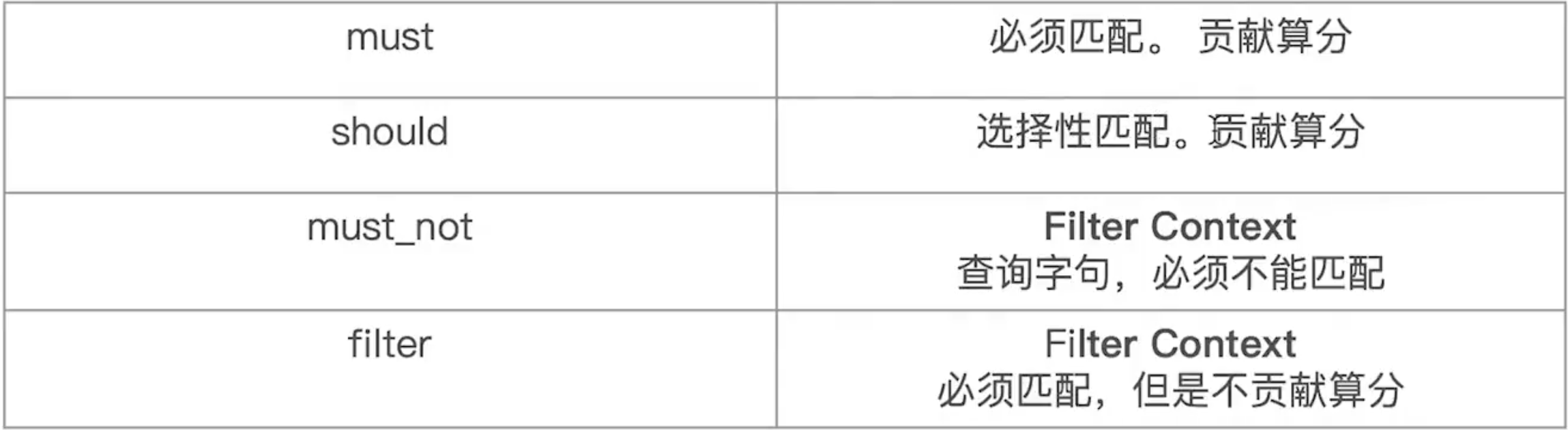
// 子查询的位置可以任意,如果bool查询中,没有must条件,should中必须至少满足一个查询// 每个子查询又可以嵌套bool查询POST /{索引名称}/_search{"query": {"bool": {"must": {"term": {"price":"30"}},"filter": {"term": {"avaliable":"true"}},"must_not": {"range": {"price": {"lte":10} // 小于等于 10}},"should": [ // 数组多个条件{"term": {"produceID.keyword":"a-1-1"}},{"term": {"produceID.keyword":"b-2-2"}}],"minimum_should_match": 1}}}
// 多条件查询POST /{索引名称}/_search{"query": {"boosting": { // 打分机制"positive": { // 正向打分"match": {"content": "apple"}},"negative": { // 逆向打分"match": {"content": "pie"}},"negative_boost": 0.2}}}
filter 参数
使用filter进行查询,其结果可以被缓存
term 参数
term 查询包含关系,并不是完全相等
精确匹配搜索
模糊匹配搜索
分词全文搜索
多条件搜索
高亮
指定关键字返回
scroll 查询
分页查询 from size
默认只能 10000 条,如果要取消这个限制,修改属性:index.max_result_window
但官方更推荐这两个属性来进行分页:scroll 或 search_after
GET /_search{"from": 5,"size": 20,"query": {"match": {"user.id": "kimchy"}}}
聚合查询
添加文档
PUT http://localhost:9200/{索引名称}/{类型}/{文档id}
添加并指定的文档id
{"name": "老人与海","desc": "文学","price": 33.9}
得到如下结果:
{"_index": "book","_type": "out","_id": "1","_version": 1,"result": "created","_shards": {"total": 2,"successful": 2,"failed": 0},"_seq_no": 0,"_primary_term": 1}
或者
POST http://localhost:9200/{索引名称}/{类型}
使用es分配的文档id
POST /website/blog{"name": "老人与海","author": "海明威"}
Bulk 操作
在一次 api 的调用中,对不同的索引进行操作,操作中的单条失败不影响其他操作,其返回结果包括了每一条的操作结果。支持以下四种类型操作:
- index
- create
- update
- delete
修改文档
修改文档会把原来的文档删除,然后再将版本号加1处理
POST http://localhost:9200/{索引名称}/{类型}/{文档id}/_update
{"doc": {"name": "老人与海-2"}}
并发情况下可以使用版本号来控制,只有 version 等于1的时候才修改:
PUT /website/blog/1?version=1{"title": "My first blog entry","text": "Starting to get the hang of this..."}
删除文档
DELETE http://localhost:9200/{索引名称}/{类型}/{文档id}
查询文档
返回文档指定字段:
GET /megacorp/employee/1?_source=age,last_name
返回文档所有字段:
GET /megacorp/employee/1
不返回元数据信息:
GET /megacorp/employee/1/_source
快速查看一个文档是否存在,存在会返回200,不存在返回404:
curl -i -I http://localhost:9200/website/_doc/123
索引创建
创建索引名称为 blogs,分配3个主分片和1个复制分片
PUT /blogs{"settings" : {"number_of_shards" : 3,"number_of_replicas" : 1}}
在索引 megacorp 内创建一个 employee 文档类型,该文档的id是1,文档内容是这个employee个人信息
PUT /megacorp/employee/1{"first_name" : "John","last_name" : "Smith","age" : 25,"about" : "I love to go rock climbing","interests": [ "sports", "music" ]}
索引查询
POST http://localhost:9200/{索引名称}/_search
具体查询和MySQL一样,有很多种姿势,需要多多练习
查看某个索引文档类型下文档id为1的文档记录
GET /megacorp/employee/1
查看该索引文档中所有文档信息:
GET /megacorp/employee/_search
使用简单查询,条件等值查询,last_name等于Smith的文档信息:
GET /megacorp/employee/_search?q=last_name:Smith
使用表达式进行查询,用match匹配,last_name等于Smith的文档信息(表达式查询非常强大):
GET /megacorp/employee/_search{"query" : {"match" : {"last_name" : "Smith"}}}
使用表达式进行复杂条件查询,用match模糊匹配,filter过滤,last_name为smith,age大于30的文档信息:
match:模糊匹配
match_phrase: 等值匹配
GET /megacorp/employee/_search{"query" : {"bool": {"must": {"match" : {"last_name" : "smith"}},"filter": {"range" : {"age" : { "gt" : 30 }}}}}}
全文搜索并将结果高亮显示,查找属性about中和“rock climbing”有关的所有文档信息,查询结果会根据字段_socre(相关性得分)来显示,得分越高越靠前:
GET /megacorp/employee/_search{"query" : {"match" : {"about" : "rock climbing"}},"highlight": {"fields" : {"about" : {}}}}
聚合查询,类似于 MySQL 中的 group by,但是更强大,根据兴趣来聚合查询
GET /megacorp/employee/_search{"aggs": {"all_interests": {"terms": { "field": "interests.keyword"}}}}
得到结果: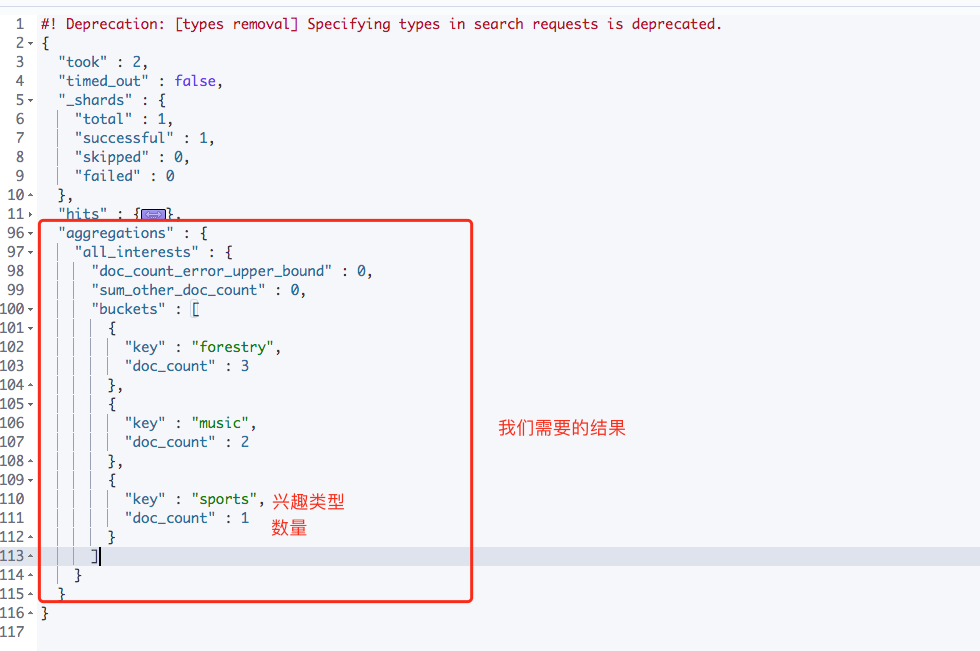
聚合复杂查询,所有 last_name 为 smith 的文档信息:
GET /megacorp/employee/_search{"query": {"match": {"last_name": "smith"}},"aggs": {"all_interests": {"terms": {"field": "interests.keyword"}}}}
聚合复杂查询,根据兴趣类型,并返回该类型下所有的平均年龄:
GET /megacorp/employee/_search{"aggs" : {"all_interests" : {"terms" : { "field" : "interests.keyword" },"aggs" : {"avg_age" : {"avg" : { "field" : "age" }}}}}}
term 查询包含关系,并不是完全相等
prefix 前缀匹配
wildcard 模糊匹配,提供*和?来匹配 keyword类型的文档
match 分词匹配,全文检索,适用于text,但实际很少用,因为匹配范围太广
match_phrase 短语匹配,查询前会将字符串解析为分词列表,然后保留那些包含分词列表的结果,适用于text;这个类型用的很多
multi_match 多组匹配,是对match的升级版本,适用于text
query_string ,支持非常丰富的查询,这个类型用的很多,适用于text
bool 组合匹配,支持多个条件组合查询,有这几种过滤选项:
- must,所有的语句都必须匹配,与AND等价
- must_not,所有的语句都不能匹配,与NOT等价
- should,至少有一个语句要匹配,与OR等价
- filter,必须匹配,运行在非评分和过滤模式
索引删除
DELETE http://localhost:9200/{索引名称}

若有收获,就点个赞吧
0 人点赞
