0x00 描述性统计总结

0x01 使用python实现描述性统计相关指标
读取数据
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom scipy.stats import modefrom collections import Counterfrom scipy import statsimport mathimport seaborn as snspath = "./actual_combat.xlsx"# 读取Excel中的数据data = pd.read_excel(path)# print(data)# 打印前20行数据print(data.head(20))
众数
# 众数# 方式一print("众数为: %d" % data.mode().iloc[0])# 方式二mode_num = mode(data)print("众数为: %d, 众数的个数为: %d," % (mode_num[0][0], mode_num[1][0]))print(mode_num)print(data.mode())
中位数
# 中位数# 法一print('中位数为: ', data.median())# 法二print('中位数为: ', np.percentile(data, 50))# 法三print('中位数为: ', data.quantile(.50))
分位数
# 分位数# 法一print('下四分位数为: ', np.percentile(data, 25))print('上四分位数为: ', np.percentile(data, 75))# 法二print('下四分位数为: ', data.quantile(.25))print('上四分位数为: ', data.quantile(.75))
算术平均数
# 算数平均数print('算数平均数为: ', data.mean())
几何平均数
# 几何平均数s = 1for i in data:s *= iprint('几何平均数为: ', math.pow(s, 1/len(data)))
众数
# 众数count = Counter(data)modeCount = count.most_common(1)[0][1]totalCount = len(data)
异众比率
# 异众比率ratio = (totalCount - modeCount) / totalCountprint(ratio)
四分位差
# 四分位差# 法一print('四分位差为: ', np.percentile(data, 75) - np.percentile(data, 25))# 法二print('四分位差为: ', data.quantile(.75) - data.quantile(.25))
极差
# 极差
print("最大值为: ", data.max())
print("最小值为: ", data.min())
print('极差为: ', data.max() - data.min())
平均差
# 平均差
meanData = data.mean()
s = 0
for i in data:
s += (abs(i - meanData))
print('平均差为: ', s/len(data))
方差
# 方差
print('方差为: ', np.var(data))
标准差
# 标准差
print('标准差为: ', np.std(data))
偏度
# 偏度
print('偏度为: ', stats.skew(data))
峰度
# 峰度
print('峰度为: ', stats.kurtosis(data))
输出data的概括性信息
# 直接输出data的概括性信息
print(data.describe())
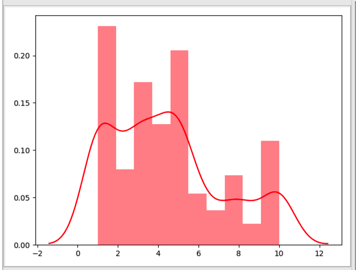
0x02 使用seaborn绘制数据的分布图
# 绘制一下data的分布图
sns.set_palette("hls") # 设置所有图的颜色, 使用hls色彩空间
sns.distplot(data, color="r", bins=10, kde=True)
plt.show()
0xFF 总结
python几个数据处理工具要经常练习达到熟练使用
附 使用的数据文件
actual_combat.xlsx

若有收获,就点个赞吧
0 人点赞
