数据
步骤
第一步读取数据
代码
val spark = SparkSession.builder().config(new SparkConf().setMaster("local[*]").setAppName("text"))// 添加满足 inner join 的配置.config("spark.sql.crossJoin.enabled","true").getOrCreate()import spark.implicits._def parseRating(str: String): Rating = {val fields = str.split("::")Rating(fields(0).toInt, fields(1).toInt, fields(2).toFloat, fields(3).toLong)}// textFile 传入路径val ratings = spark.sparkContext.textFile("data/scala/sample_movielens_ratings.txt").map(parseRating).toDF()ratings.show(false)
一部分结果

第二步 处理分母需要的数据
代码
分母是 向量模开根号 乘积 这里先计算每一个向量的模开根号
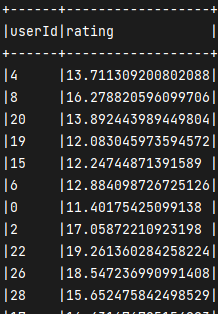
val df_rating = ratings.rdd.map(x => {(x(0).toString, x(2).toString)}).groupByKey().mapValues(/*sqrt 开根号*/score => math.sqrt(score.toArray/*pow 代表一第一个参数为底 第二个参数为幂*/.map(x => {math.pow(x.toDouble, 2)}).reduce(_ + _))).toDF("userId", "rating")
一部分结果
第三步求分子
第一步
- 分子是两个向量点的乘积和
-
代码
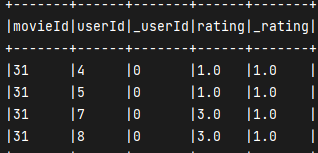
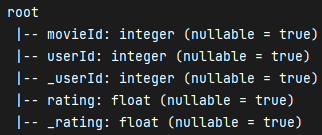
val _ratingScore = ratings.select($"userId".alias("_userId"), $"movieId", $"rating".alias("_rating")).join(ratings, "movieId").where($"userId" =!= $"_userId").select($"movieId", $"userId", $"_userId", $"rating", $"_rating")_ratingScore.show(false)_ratingScore.printSchema()
一部分结果
第二步
思路
先求 rating和_rating乘积
- 按照userId和_userId 分组 对乘积求和得出分子
代码
```java // 求出分子 rating和_rating乘积和 val sumFenMu = _ratingScore.select(
, $”_userId”$"userId"
) .groupBy( $”userId” , $”_userId”) .agg(sum($”score_mo1”).alias(“sumScore”)), ($"rating" * $"_rating").alias("score_mo1")
<a name="ADLXk"></a>#### 一部分结果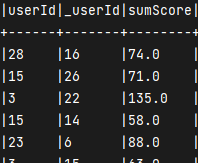<a name="hBfBu"></a>## 整合求余弦相似度并且按照top5输出<a name="nB3O8"></a>### 第一步<a name="hHjBL"></a>#### 思路1. 把分子的表 与 完成一部分分母的表进行联表1. 通过结果表 对 两个分母的一部分进行乘积1. 分子除以分母得出余弦相似度1. 开窗函数保留前五<a name="ZiT40"></a>#### 代码```java// 先复制一份分母表val _df_rating = df_rating.select($"userId".alias("_userId"), $"rating".as("_rating"))// 得到 _userId|userId|sumScore|rating|_ratingval frame: DataFrame = sumFenMu.join(df_rating,"userId").join(_df_rating,"_userId")frame.show(false)frame.createTempView("frame")// 按照公式 sumScore/ (rating * _rating)spark.sql("select * from frame").select(col("userId"), col("_userId"), (col("sumScore")/( col("rating") * col("_rating"))).as("cos"))// 开窗函数求出 余弦相似度最接近的top5.withColumn("top", row_number() over(Window.partitionBy("userId").orderBy($"cos".desc))).where($"top"<=5).drop($"top").show(false)
一部分结果
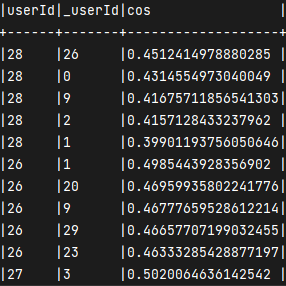
整体代码
import org.apache.spark.SparkConfimport org.apache.spark.ml.recommendation.ALSimport org.apache.spark.sql.expressions.Windowimport org.apache.spark.sql.functions._import org.apache.spark.sql.{DataFrame, SparkSession}object helloBy {case class Rating(userId: Int, movieId: Int, rating: Float, timestamp: Long)def main(args: Array[String]): Unit = {// 机器学习 基于协同过滤推荐系统System.setProperty("hadoop.home.dir", "H:\\winutils\\winutils-master\\hadoop-2.6.0")val spark = SparkSession.builder().config(new SparkConf().setMaster("local[*]").setAppName("text"))// 添加满足 inner join 的配置.config("spark.sql.crossJoin.enabled","true").getOrCreate()import spark.implicits._def parseRating(str: String): Rating = {val fields = str.split("::")Rating(fields(0).toInt, fields(1).toInt, fields(2).toFloat, fields(3).toLong)}val ratings = spark.sparkContext.textFile("data/scala/sample_movielens_ratings.txt").map(parseRating).toDF()ratings.show(false)// 通过余弦相似度计算用户相似度// 分母每个向量模的乘积// 获取独自的每一个用户模开根号//每一个点的乘积和就是模val df_rating = ratings.rdd.map(x => {(x(0).toString, x(2).toString)}).groupByKey().mapValues(/*sqrt 开根号*/score => math.sqrt(score.toArray/*pow 代表一第一个参数为底 第二个参数为幂*/.map(x => {math.pow(x.toDouble, 2)}).reduce(_ + _))).toDF("userId", "rating")df_rating.show(false)// 用户两两匹配val _ratingScore = ratings.select($"userId".alias("_userId"), $"movieId", $"rating".alias("_rating")).join(ratings, "movieId").where($"userId" =!= $"_userId").select($"movieId", $"userId", $"_userId", $"rating", $"_rating")_ratingScore.show(false)_ratingScore.printSchema()_ratingScore.cache()// 求出分子 rating和_rating乘积和val sumFenMu = _ratingScore.select($"userId", $"_userId", ($"rating" * $"_rating").alias("score_mo1")).groupBy($"userId", $"_userId").agg(sum($"score_mo1").alias("sumScore"))sumFenMu.show(false)val _df_rating = df_rating.select($"userId".alias("_userId"), $"rating".as("_rating"))// 得到 _userId|userId|sumScore|rating|_ratingval frame: DataFrame = sumFenMu.join(df_rating,"userId").join(_df_rating,"_userId")frame.show(false)frame.createTempView("frame")// 按照公式 sumScore/ (rating * _rating)spark.sql("select * from frame").select(col("userId"), col("_userId"), (col("sumScore")/( col("rating") * col("_rating"))).as("cos"))// 开窗函数求出 余弦相似度最接近的top5.withColumn("top", row_number() over(Window.partitionBy("userId").orderBy($"cos".desc))).where($"top"<=5).drop($"top").show(false)}}
注意
- 分母是分两步求得 一步到位不好处理(但是可以不用分母 分子 分母) 可以用(分母 分母 分子)这种顺序也是可以得
- 一定要对公式特别熟悉

若有收获,就点个赞吧
0 人点赞
