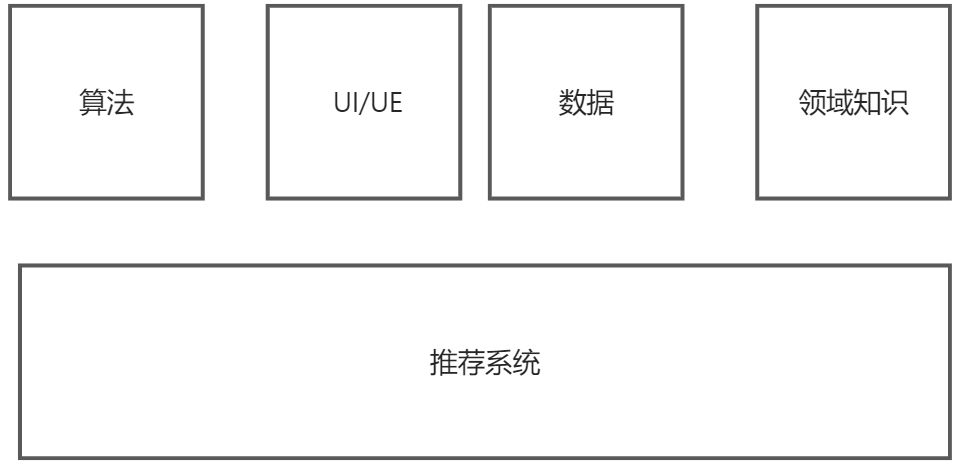
推荐系统的关键元素
数据
数据分类
- 用户
- 用户信息
- 用户行为
- 显式反馈
- 隐式反馈
- 用户关系
- 显式关系
- 隐式关系
-
推荐算法
基于流行度的推荐算法
- 基于协同过滤的推荐算法(重点)
- 基于内容的推荐算法
- 基于模型的推荐算法
-
领域知识
UI
推荐结果的最终呈现给用户的展示位置 提供了哪些信息
-
推荐系统的思维模式
不确定的思维 (概率)
-
推荐算法的分类
大纲
基于关联规则的推荐算法
- Apriori 关联分析算法
- 无监督学习
- 数据量大 运行效率很低
- Fp-Growth 关联分析算法
- 应用场景(购物篮 购物车的分析)
- Apriori 关联分析算法
- 基于内容的推荐算法
- 打标签
- 文本相似度(TF-IDF 算法 提取关键词)
- 分类算法
- knn
- 决策树
- 随机森林
- XGBoost
- 线性分类算法
- 逻辑回归
- SVM
- 朴素贝叶斯算法
- 比如文章推荐
- 基于协同过滤的推荐算法 (通过人与人 物与物)
- 基于用户的推荐(兴趣相近的用户会对同样的物品感兴趣)
- 基于物品的推荐 (推荐用户他们喜欢的物品相似的物品)
- 基于模型的推荐 (要基于用户的方式 不能简单推荐相似物品)
- SVD/SVD++ 模型
- 基于概率的矩阵分解(PMF)
- 隐语义模型(LFM)
- 基于模型的推荐算法
基于协同过滤的推荐算法优缺点
缺点:
-
有点
挖掘用户的潜在兴趣
- 仅需要评分矩阵来训练矩阵分解模型
协同过滤
SVD++ 是最流行的协同过滤模型(解决数据稀疏的问题)
基于概率的矩阵分解PMF(解决SVD过于复杂的问题)
spark内置的推荐算法是基于隐语义模型的协同过滤 (ALS)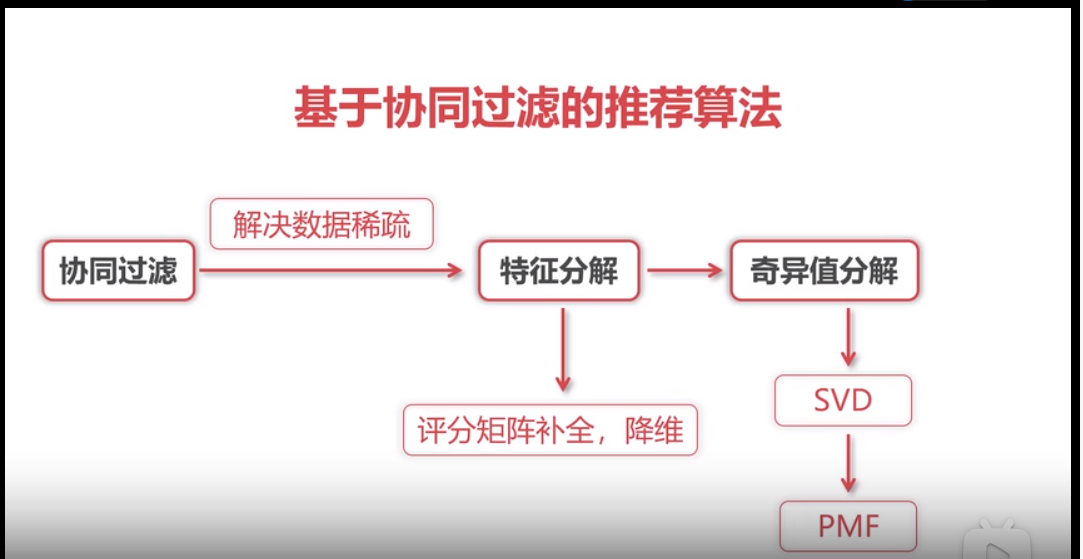
混合推荐算法
- 加权的混合(重新分配权重)
- 分层的混合 多种推荐算法
-
推荐系统常见的问题
冷启动
- 数据稀疏
- 不断变化的用户喜好
-
冷启动
用户冷启动 给新用户做个性推荐
- 物品冷启动 把新的物品推荐个特定的用户
-
冷启动的解决方案
用户冷启动
根据用户的注册信息对用户进行分类
- 推荐热门的排行榜
- 基于深度学习的语义模型
- 引导用户把自己的属性表达出来
-
物品冷启动
文本分析
- 主题模型(训练出模型)
- 给物品打标签
-
数据稀疏解决
降低矩阵维数能降低(奇异值分解 PCA分解)
- 降低矩阵维数会丢失有效数据 但是是主要解决办法
- 假设用户对其感兴趣物品相似的物品也感兴趣(数据填充)
- 固定填充没有考虑到项目的属性 对推荐带来偏差
-
推荐系统效果评测方案
模型离线实验
- A/B Test 在线实验
-
模型离线实验
将数据集分为训练集和测试集
- 训练集训练模型 测试集进行预测
-
优缺点:
- 优点无真实用户参与
-
A/B Test 在线实验
A/B Test 在线实验是以正交分桶为基础
- 根据分桶执行不同的算法得出差异化的指标
-
用户调研
预测准确率高不代表用户满意度高
- 用户调研需要一些真实的用户需要他们完成一些的任务
- 缺点是用户调研成本高 一般情况下很难进行大规模的用户调查
评测指标

覆盖率

若有收获,就点个赞吧
0 人点赞
