基于用户的协同过滤
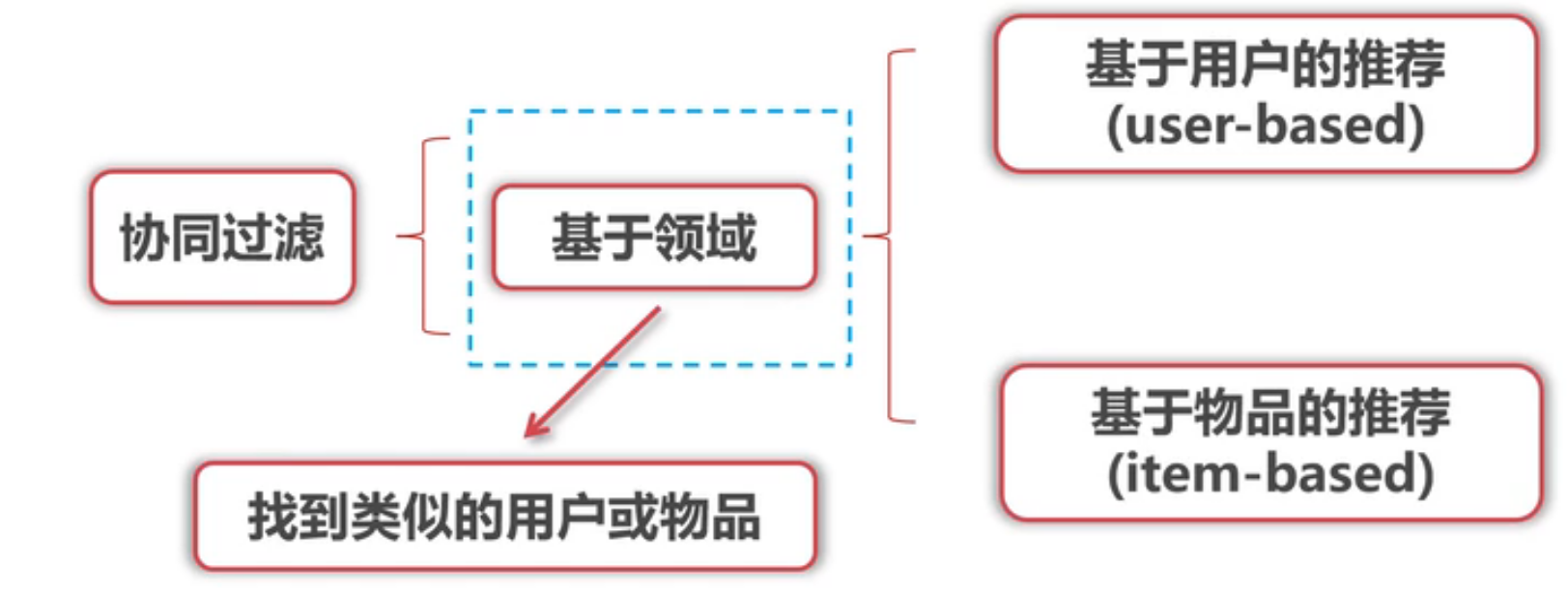 基于用户的推荐
基于用户的推荐

A, C 相似 并且用户B(相似度很低)不一样 C购买了物品D 则可以把物品D推荐给用户A
- 算法思想是对用户进行聚类, 推荐和你相似的用户喜欢的无哦
优点
- 有推荐新信息的能力, 可以返现用户潜在但尚未发现的爱好
- 推荐个性化, 自动化程度高
如何计算用户相似度
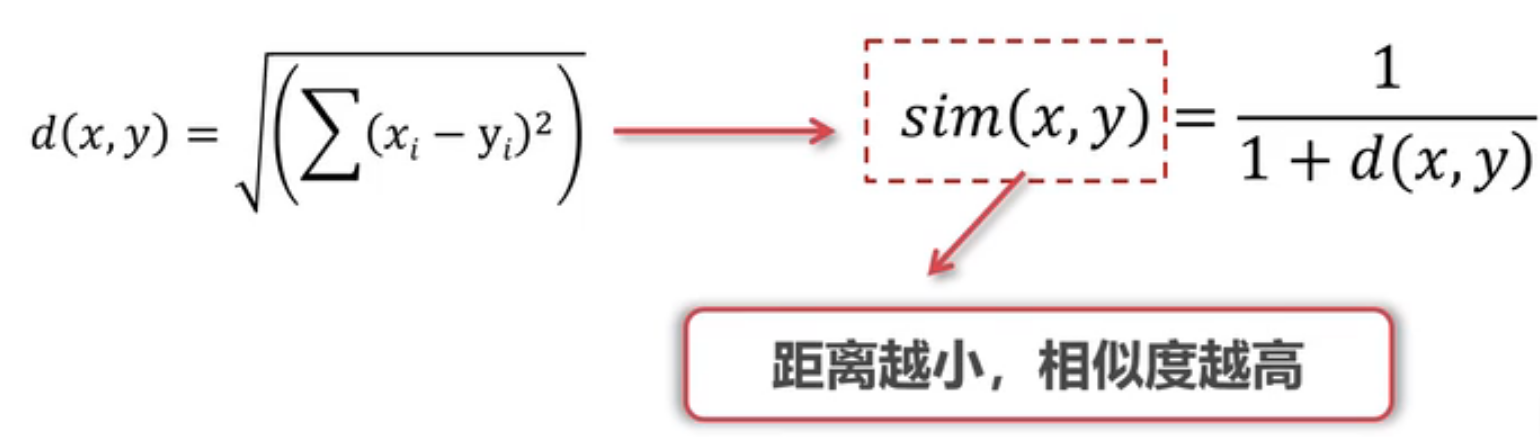
欧氏距离
- 余弦相似度
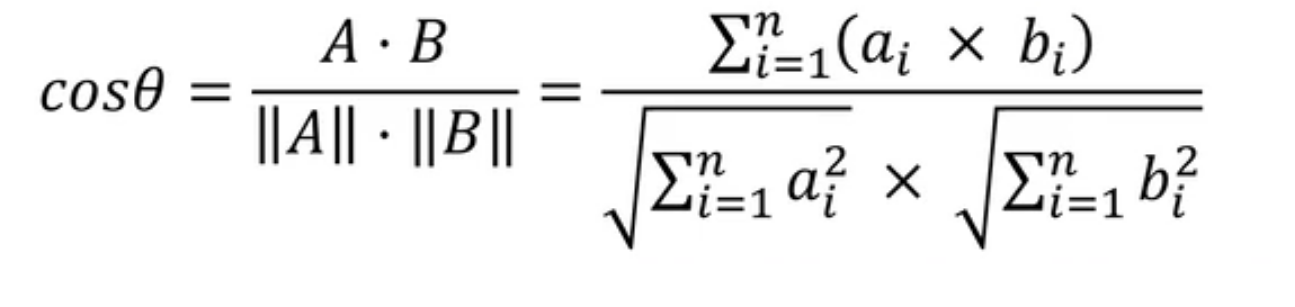
- 皮尔逊相关系数

推荐过程
- 生成用户-物品评价矩阵
- 计算目标用户和所有用户的相似度 找出k个最相似用户集
生成推荐
补充知识点
向量的模
- 空间向量(x,y,z),其中x,y,z分别是三轴上的坐标,模长是 [3]

基于物品得协同过滤(item-based)
基于用户得协同过滤得缺点
- 用户数目较大, 计算用户相似度矩阵越困难
用户-物品评价矩阵数据非常稀疏,难以找到相似用户集
思想理解
实现步骤
用户-物品排序
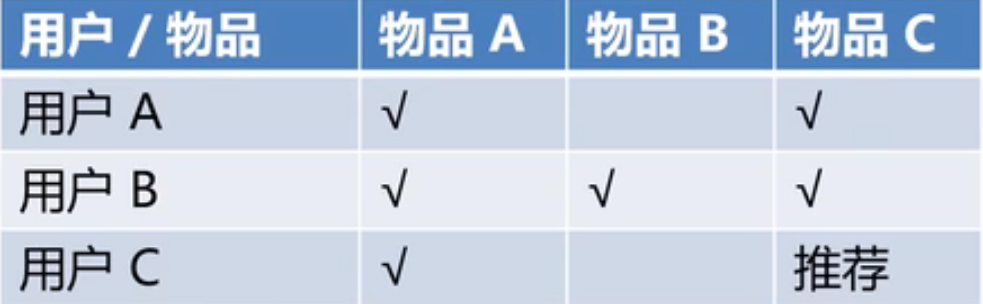
- 构建用户-物品倒排序表
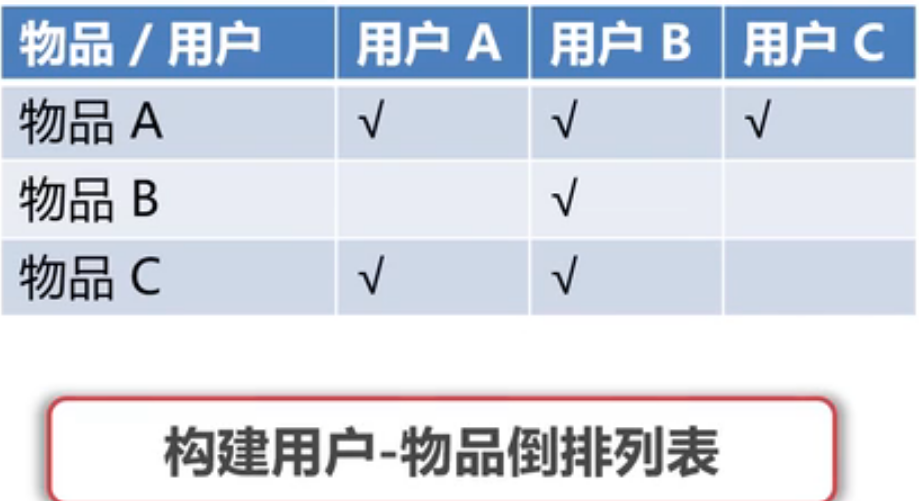
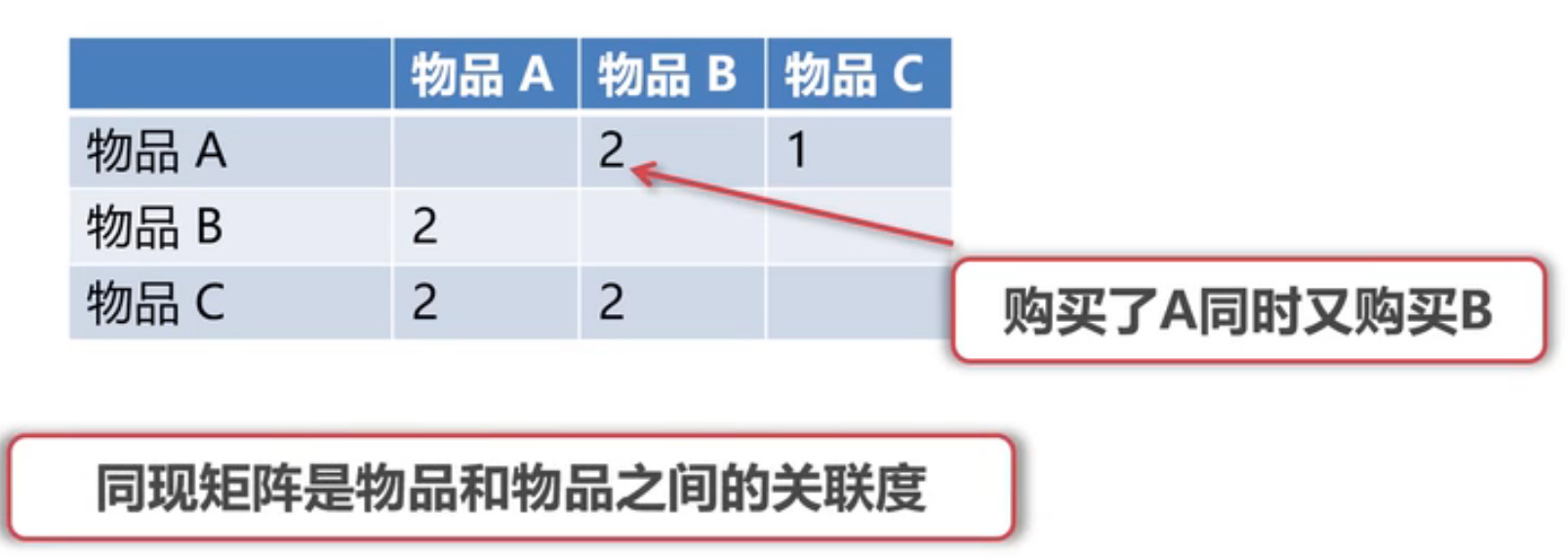
接着构建同现矩阵
- 构建同现矩阵
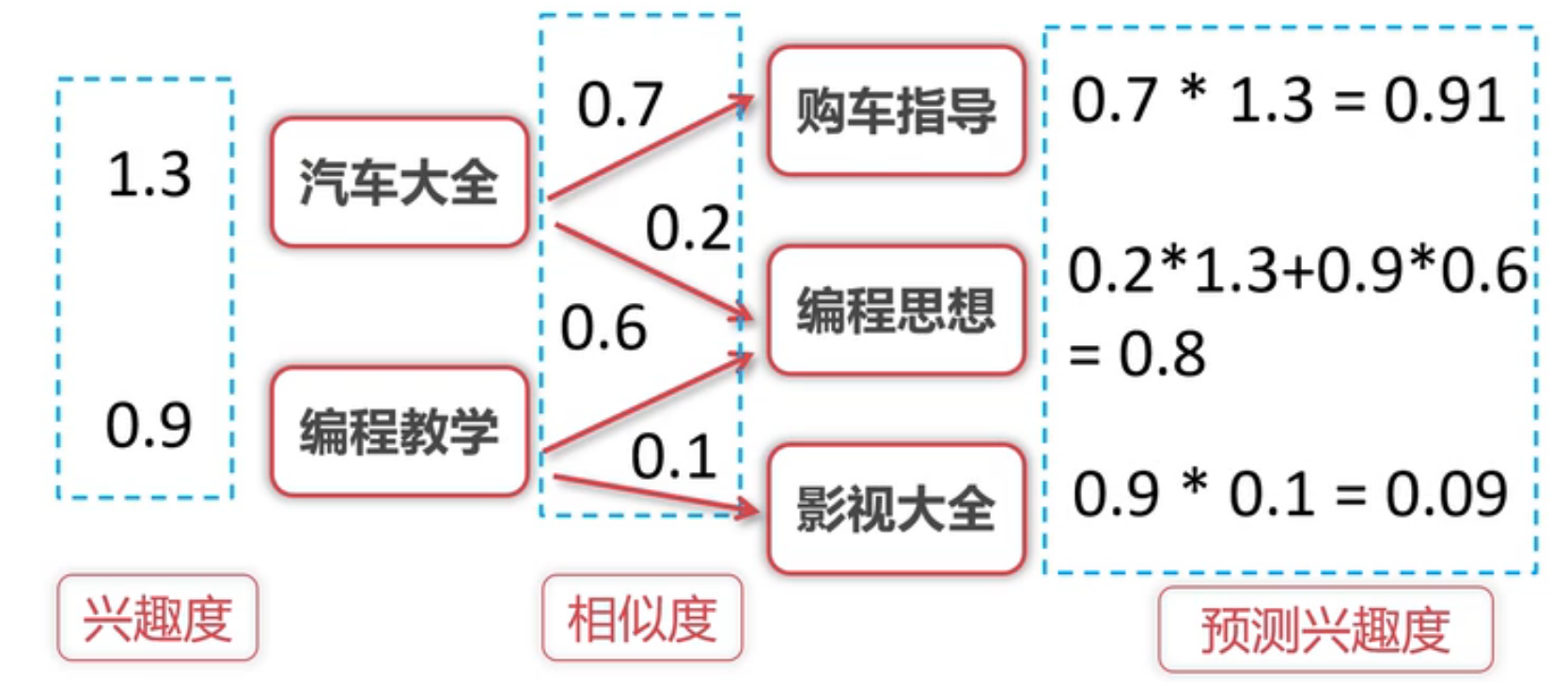
- 兴趣 以C为列子
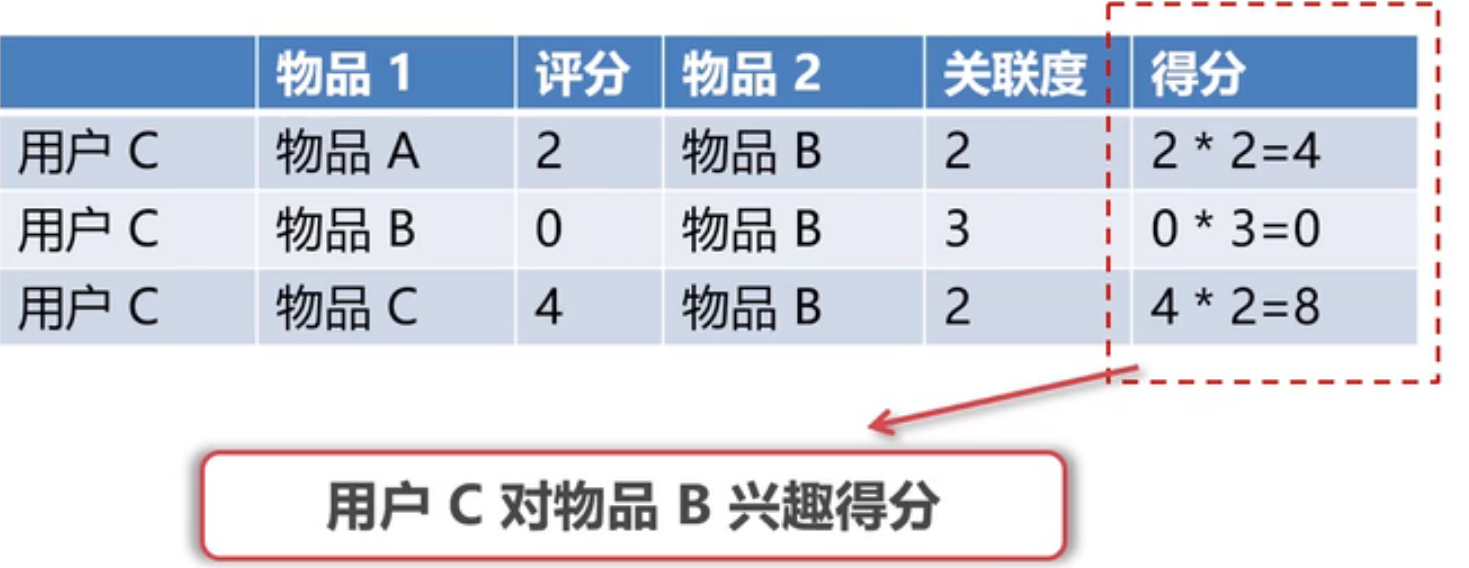
- 计算出兴趣度

计算公式
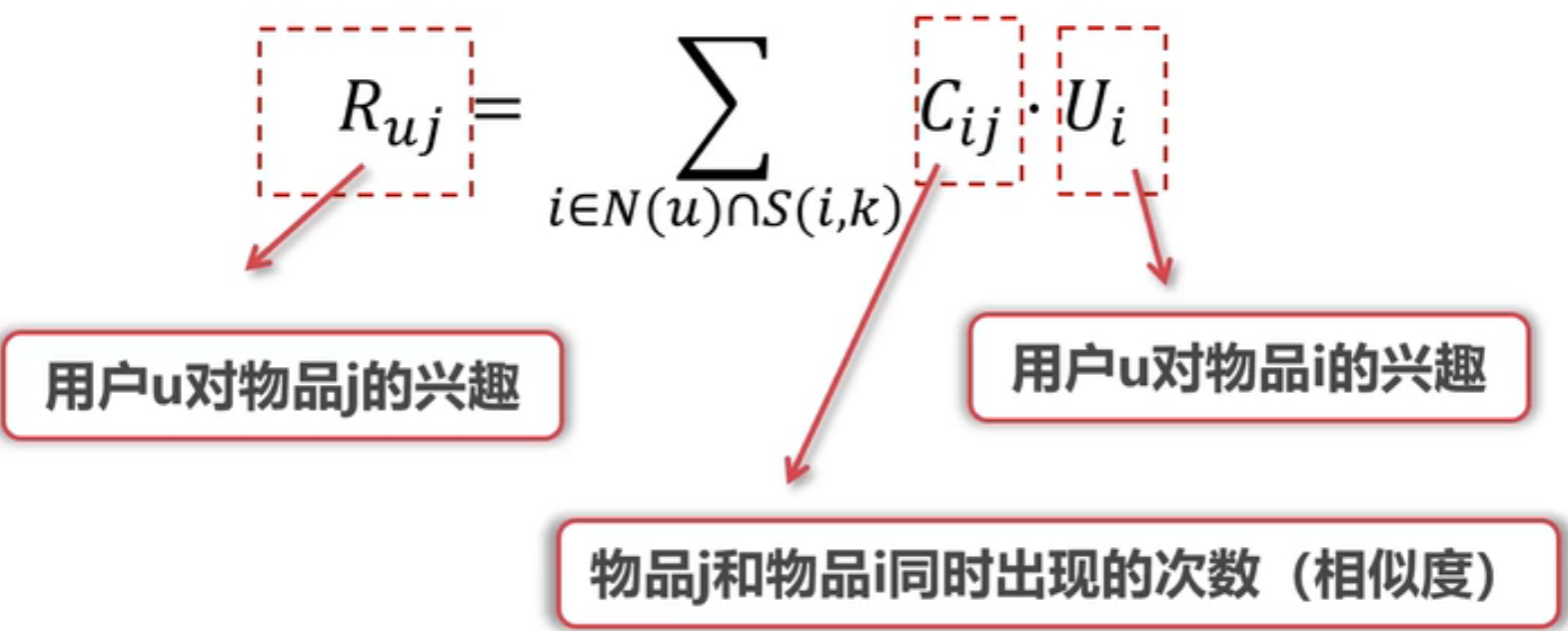
物品相似度
- 两个物品相似度越高 越共同被很多用户喜欢
用户对物品的打分
基于物品的协同过滤算法步骤
计算用户-物品打分矩阵
- 计算物品相似度矩阵
用户-物品打分矩阵*物品相似度矩阵=推荐列表
基于模型的协同过滤
基于模型的协同过滤
基于分解
基于隐语义
1. 基于分解
分解相似度矩阵
特征值分解
- 奇异值分解(a-b-c 准确度提高 复杂度增加 效率降低)
- 缺点
- 需要很大的储存空间
- 特别复杂
- SVD
- SVD++
- 时间敏感模型
基于概率的矩阵分解
- MF矩阵分解模型
- 基本矩阵分解
- 正则化矩阵分解
- 基于概率的矩阵分解
分解评分矩阵
2. 基于隐语义
LFM(FuncSVD)
利用梯度下降法对SVD进行了改进
缺点
无法解决冷启动
- 无法实时推荐

