数据
思路
- 加载数据
- 获取用户-电影-评分
- 获取电影-电影相似度
加载数据
```java val spark = SparkSession.builder() .config( new SparkConf()
) // 添加满足 inner join 的配置 .config(“spark.sql.crossJoin.enabled”,”true”) .getOrCreate() import spark.implicits._.setMaster("local[*]").setAppName("text")
def parseRating(str: String): Rating = {val fields = str.split("::")Rating(fields(0).toInt, fields(1).toInt, fields(2).toFloat, fields(3).toLong)}val ratings = spark.sparkContext.textFile("data/scala/sample_movielens_ratings.txt").map(parseRating).toDF()ratings.show(false)
<a name="QNXXp"></a># 第二步求得 movieId_1 和 movieId_2 的共同个数```java// 物品相似度表(矩阵)val dataFrame: DataFrame = ratings.select("userId", "movieId")val frame: DataFrame = dataFrame.join(dataFrame, "userId").map(x => {(x(0).toString, (x(1).toString, x(2).toString))}).map(x => {(x._2._1, x._2._2, 1)}).groupBy("_1", "_2").agg(sum("_3").as("sim")).withColumnRenamed("_1", "movieId_1").withColumnRenamed("_2", "movieId_2")
部分结果
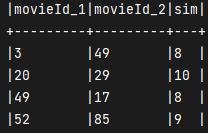
第三步 得出结果
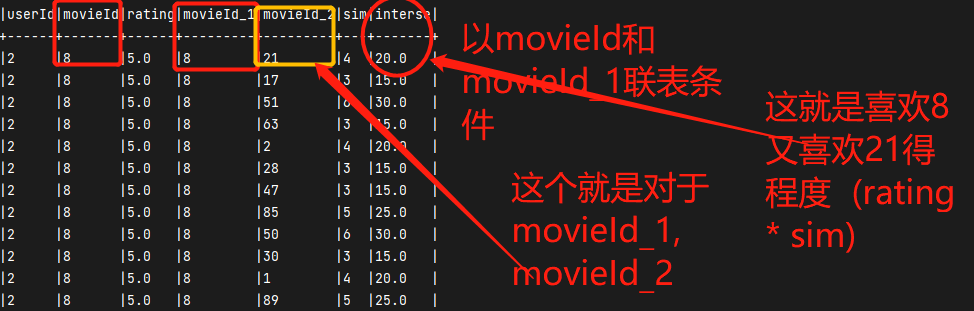
- 形成 userId movieId rating movieId_1 movieId_2 sim
- userId | movieId_2 | interse interse = rating * sim
- 利用开窗函数获得前四
ratings.join(frame, ratings("movieId") === frame("movieId_1"), "inner" )// 获取sim与rating乘积.withColumn("interse", frame("sim")*ratings("rating")).select("userId", "movieId_2", "interse")// 按照用户与movieId_2 分组 求 interse得总和 并且获取top4.groupBy("userId", "movieId_2").agg(sum("interse").as("interse"))// 开窗函数.withColumn("top", row_number().over(Window.partitionBy("userId").orderBy($"interse".desc))).where($"top" < 5).show(false)/*如果推荐的前四电影中 用户没有看过则 这个电影就是推荐给用户得其中之一*/
一部分结果

得出结果中间一部分代码得图片
ratings.join(frame, ratings("movieId") === frame("movieId_1"), "inner" )// 获取sim与rating乘积.withColumn("interse", frame("sim")*ratings("rating")).show(false)
整体代码
import org.apache.spark.SparkConfimport org.apache.spark.ml.recommendation.ALSimport org.apache.spark.sql.expressions.Windowimport org.apache.spark.sql.functions._import org.apache.spark.sql.{DataFrame, SparkSession}object hello {case class Rating(userId: Int, movieId: Int, rating: Float, timestamp: Long)def main(args: Array[String]): Unit = {// 机器学习 基于协同过滤推荐系统System.setProperty("hadoop.home.dir", "H:\\winutils\\winutils-master\\hadoop-2.6.0")val spark = SparkSession.builder().config(new SparkConf().setMaster("local[*]").setAppName("text"))// 添加满足 inner join 的配置.config("spark.sql.crossJoin.enabled", "true").getOrCreate()import spark.implicits._def parseRating(str: String): Rating = {val fields = str.split("::")Rating(fields(0).toInt, fields(1).toInt, fields(2).toFloat, fields(3).toLong)}var ratings = spark.sparkContext.textFile("data/scala/sample_movielens_ratings.txt").map(parseRating).toDF()ratings = ratings.select("userId","movieId","rating").where($"rating" > 0)// val useItemDate = ratings.groupBy("userId")// .pivot("movieId")// .sum("rating")// .na// .fill(0)// useItemDate.show(false)// 物品相似度表(矩阵)val dataFrame: DataFrame = ratings.select("userId", "movieId")val frame: DataFrame = dataFrame.join(dataFrame, "userId").map(x => {(x(0).toString, (x(1).toString, x(2).toString))}).map(x => {(x._2._1, x._2._2, 1)}).groupBy("_1", "_2").agg(sum("_3").as("sim")).withColumnRenamed("_1", "movieId_1").withColumnRenamed("_2", "movieId_2")frame.show(false)ratings.join(frame, ratings("movieId") === frame("movieId_1"), "inner" )// 获取sim与rating乘积.withColumn("interse", frame("sim")*ratings("rating")).select("userId", "movieId_2", "interse")// 按照用户与movieId_2 分组 求 interse得总和 并且获取top4.groupBy("userId", "movieId_2").agg(sum("interse").as("interse"))// 开窗函数.withColumn("top", row_number().over(Window.partitionBy("userId").orderBy($"interse".desc))).where($"top" < 5).show(false)/*如果推荐的前四电影中 用户没有看过则 这个电影就是推荐给用户得其中之一*/ratings.join(frame, ratings("movieId") === frame("movieId_1"), "inner" )// 获取sim与rating乘积.withColumn("interse", frame("sim")*ratings("rating")).show(false)// val frame1: DataFrame = frame.groupBy("movieId_1")// .pivot("movieId_2")// .sum("sim")// .withColumnRenamed("movieId_1", "movieId")// .na// .fill(0)// frame1.show(false)}}
注意
- 一定要注意表的对应列和对应关系
- 联表注意联表的两列不是我们需要的 而是附带的另一列 比如联表是(movieId, movieId_1) 我们需要的是 (movieId_2)

若有收获,就点个赞吧
0 人点赞
