交替最小二乘法是统计分析中最常用的逼近计算的一种算法,其交替计算结果使得最终结果尽可能地逼近真实结果
5.3.1 最小二乘法(LS算法)详解
简单的介绍一下ALS算法的基础,LS算法
LS算法是一种数学优化技术,也是一种机器学习常用算法。他通过最小化误差的平方和寻找数据的最佳函数匹配。通过最小二乘法可以简单地求得未知的数据,并使得这些求得的数据与实际数据之间的误差的平方和最小。最小二乘法还可用于曲线拟合。其他一些优化问题也可通过最小化能量或最大化熵来表达
从这个图可以看到 若干个点一次分布再向量空间中, 如果希望找出一条直线和这些点达到最佳匹配。那么最简单的一个方法就是希望这些点到直线的距离最小 即公式如下: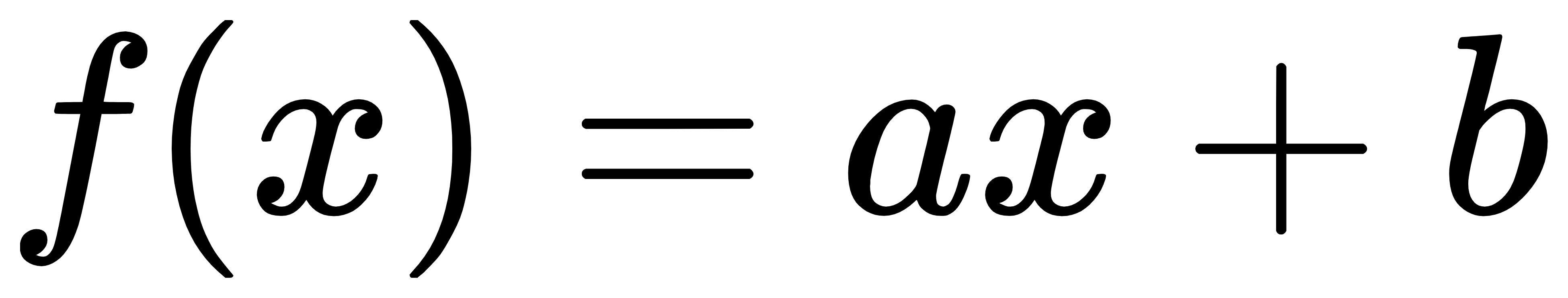

公式中f(x)是直接的拟合公式,也是所求的目标函数。在这里希望各个点到直线的值最小,也就是可以将其理解为其差值和最小,这里可以使用微分的方法求得最小值
5.3.2 MLlib中交替最小二乘法(ALS 算法)详解
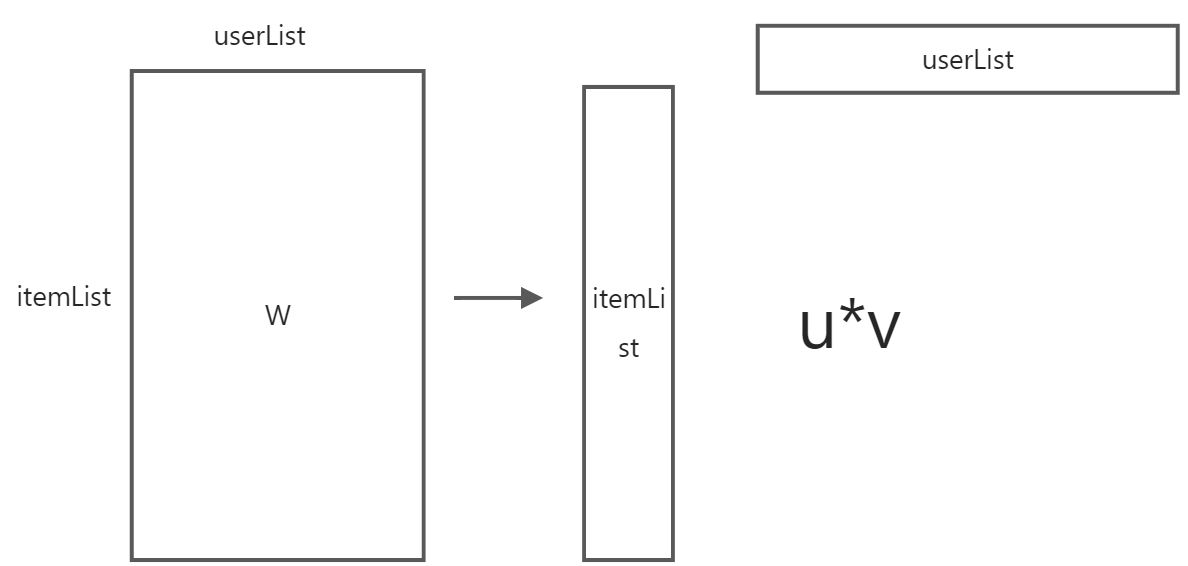
图5-6 ALS 算法矩阵分解图示
可以表达为 W = U x V
这里U和V分别表示用户和物品的矩阵,再Mllib的ALS算法中首先U或者V矩阵随机生成,之后固定某一个特定对象,然后取另外一个未随机变化的矩阵对象,然后利用被求取的矩阵对象去求随机化矩阵独享, 最后两个对象相互迭代计算,求取与实际矩阵差异达到最小 步骤如下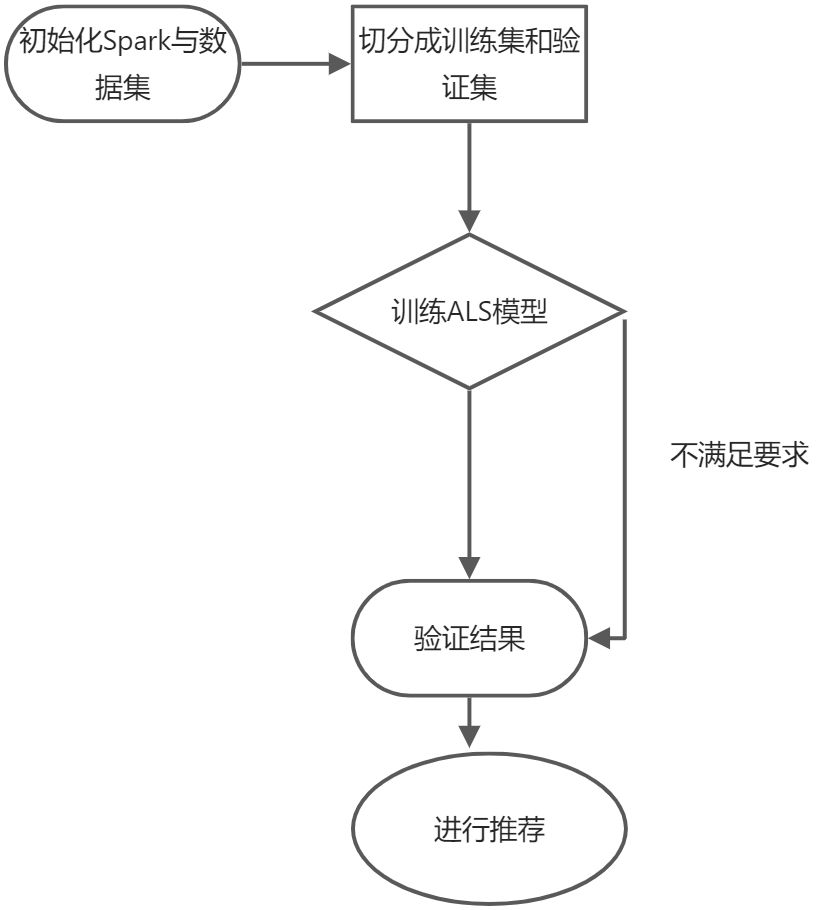
图5-7 ALS算法流程图
5.3.3 ALS算法实战
数据格式: 用户id, itemId, rating
这里需要注意, MLLib中ALS算法有固定的数据格式, 源码如下
:::tips
case class Rating @Since(“0.8.0”) (
@Since(“0.8.0”) user: Int, // 用户
@Since(“0.8.0”) product: Int, // 商品
@Since(“0.8.0”) rating: Double) //评分
:::
从流程图可以看出 接下来就是建立ALS模型 ALS数据模型是根据数据集训练获得, 即ALS.train方法是最重要的方法 源码如下
:::tips
@Since(“0.9.1”)
def train(
ratings: RDD[Rating], // 数据集
rank: Int, // 模型中隐藏因子
iterations: Int,// 算法迭代次数
lambda: Double, //ALS 正则化残花
blocks: Int,
seed: Long
): MatrixFactorizationModel = {
new ALS(blocks, blocks, rank, iterations, lambda, false, 1.0, seed).run(ratings)
}
//参数解释
/*
Train a matrix factorization model given an RDD of ratings by users for a subset of products.
The ratings matrix is approximated as the product of two lower-rank matrices of a given rank
(number of features). To solve for these features, ALS is run iteratively with a configurable
level of parallelism.
* @param ratings RDD of [[Rating]] objects with userID, productID, and rating
* @param rank number of features to use
* @param iterations number of iterations of ALS
* @param lambda regularization parameter
* @param blocks level of parallelism to split computation into
* @param seed random seed for initial matrix factorization model
*/
:::
5.3.4 基于ALS算法的协同过滤推荐
package comKX.sparkMllib.ChapterVimport org.apache.spark.mllib.recommendation.{ALS, MatrixFactorizationModel, Rating}import org.apache.spark.rdd.RDDimport org.apache.spark.sql.SparkSessionimport org.apache.spark.{SparkConf, SparkContext}object CollaborativeFilteringAlgorithm2 {/*ALS算法实战*/// 设置环境变量val testConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Test") //实例化环境val sc = new SparkContext(testConf)val spark: SparkSession = SparkSession.builder().config(testConf).getOrCreate()def main(args: Array[String]): Unit = {System.setProperty("hadoop.home.dir", "H:\\winutils\\winutils-master\\hadoop-2.6.0")// 初始化数据val ratings: RDD[Rating] = sc.textFile("data/ul.txt").map((x: String) => x.split(" ")// 使用match语句 匹配格式 然后转换成Ratingmatch {case Array(user, item, rating)=>Rating(user.toInt, item.toInt, rating.toDouble)})val rank = 2 // 设置隐藏因子val numIterations = 2 // 设置迭代次数// 获取modelval alsModel: MatrixFactorizationModel = ALS.train(ratings, rank = rank, iterations = numIterations, 0.01)// 为用户2 推荐两个商品 转换成dataframe 输出spark.createDataFrame(alsModel.recommendProducts(2,2)).show(false)}}
在程序中, 使用ALS.train建立一个mode,是根据已有的数据集建立的一个协同过滤矩阵推荐模型, 之后使用 recommendProducts 方法为第二个用户推荐一个物品<br />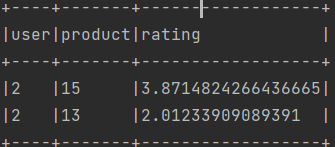<br />根据结果现实,这里为第二个用户推荐了编号为15, 13的物品,同时将评分输出
5.3.5 ALS模型方法补充 (MatrixFactorizationModel)
- 预测用户对物品的评分
predict(int user, int product)
- 预测用户集对物品集的评分
predict(JavaPairRDD
- 推荐用户k个物品
recommendProducts(final int user, int num)
- 对物品推荐k个用户
recommendUsers(final int product, int num)
- 对所有用户推荐物品,物品数量取前k个
recommendProductsForUsers(int num)
- 对所有物品推荐用户,用户数量取前k个
recommendUsersForProducts(int num)

若有收获,就点个赞吧
0 人点赞
