从上一届得内容介绍种可以看到,对于不同形式的协同过滤,最重要的部分就是相似度得求得。如果不同的用户或者物品之间得相似度缺乏有效而可靠的算法定义,那么协同过滤算法就是去了成立得条件
5.2.1 基于欧几里得距离的相似度计算
计算两个点之间的绝对距离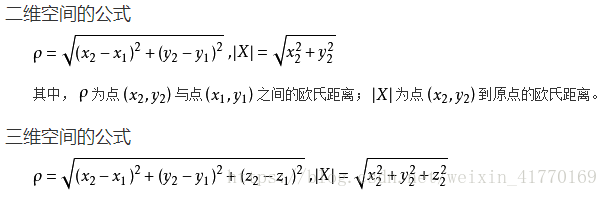
值越大,相似度越低。值越低,相似度越高。
例子
表5-1 用户与物品评分对应表
| 物品1 | 物品2 | 物品3 | 物品4 | |
|---|---|---|---|---|
| 用户1 | 1 | 1 | 3 | 1 |
| 用户2 | 1 | 2 | 3 | 2 |
| 用户3 | 2 | 2 | 1 | 1 |
如果需要计算用户1与用户2之间的相似度, 通过欧几里得距离公式可以得出
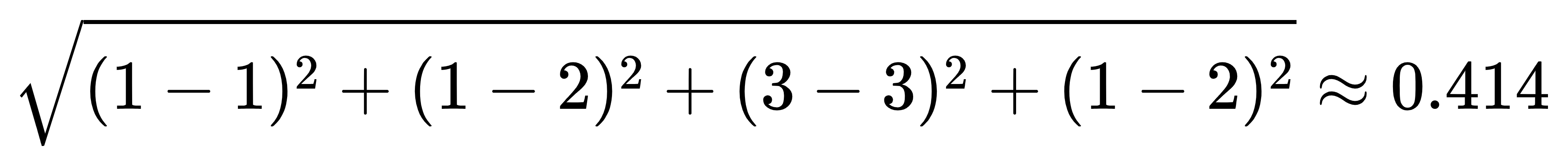
用户1和用户3得欧几里得距离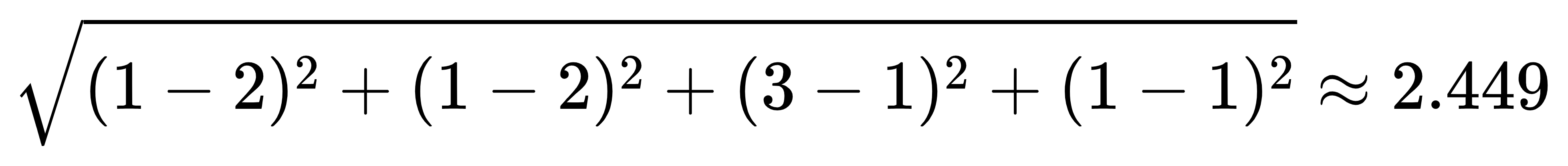
我们可以发现用户1与用户2得分值比与用户3得分值低
说明用户1与用户2得相似度高
5.2.2 基于余弦角度的相似度计算
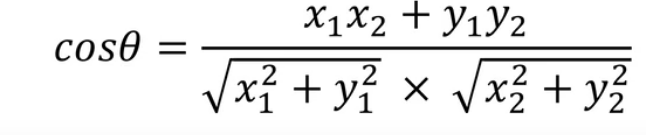
表5-1 用户与物品评分对应表 得余弦相似度就可以计算成
用户1 和 用户2
用户1和用户3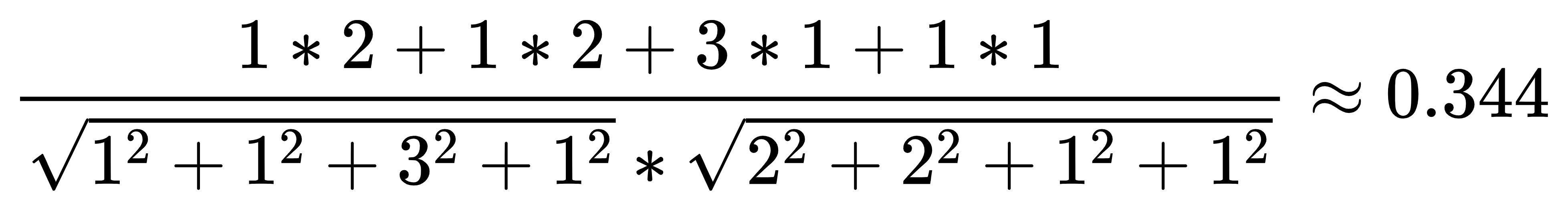
通过余弦相似度也可以得出 用户1和用户2得相似度更高
5.2.3 欧几里得相似度与余弦相似度得比较
- 欧几里得相似度是以目标绝对距离作为衡量的标准, 而余弦相似度是以目标差异得大小作为衡量标准
- 欧几里得相似度注重目标之间的差异,与目标在空间种得位置直接相关。而余弦相似度是不同目标在空间中得夹角,更加哦表现在前进趋势上的差异
欧几里得相似度和余弦相似度具有不同得计算方法和描述特征。一般来说欧几里得相似度用来表现不同目标得绝对查一下,分析目标之间的相似度与差异情况。而余弦相似度更多得是对目标从方向趋势上的区别 对特定坐标数字不敏感
5.2.4 第一个列子——-余弦相似度实战
```java /余弦相似度案列/ // 设置环境变量
val testConf: SparkConf = new SparkConf().setMaster(“local[*]”).setAppName(“Test”) //实例化环境 val sc = new SparkContext(testConf) val user: RDD[String] = sc.parallelize(Array(“aaa”, “bbb”, “ccc”, “ddd”, “eee”)) // 得到一个rdd val films: RDD[String] = sc.parallelize(Array(“smzdm”, “ylxb”, “znh”, “nhsc”, “fcwr”)) var source: Map[String, Map[String, Int]] = MapString, Map[String, Int] // 存放数据
def getSource (): Map[String, Map[String, Int]] ={ /**
* 初始化数据*/val user1FileSource: Map[String, Int] = Map("smzdm"->2,"ylxb"->3,"znh"->1,"nhsc"->0,"fcwr"->1)val user2FileSource: Map[String, Int] = Map("smzdm"->1,"ylxb"->2,"znh"->2,"nhsc"->1,"fcwr"->4)val user3FileSource: Map[String, Int] = Map("smzdm"->2,"ylxb"->1,"znh"->0,"nhsc"->1,"fcwr"->4)val user4FileSource: Map[String, Int] = Map("smzdm"->3,"ylxb"->2,"znh"->0,"nhsc"->5,"fcwr"->3)val user5FileSource: Map[String, Int] = Map("smzdm"->5,"ylxb"->3,"znh"->1,"nhsc"->1,"fcwr"->2)source+=("aaa"->user1FileSource)source+=("bbb"->user2FileSource)source+=("ccc"->user3FileSource)source+=("ddd"->user4FileSource)source+=("eee"->user5FileSource)source
} def getCollaborateSource(user1:String, user2:String): Double ={ /**
* 计算并且返回余弦相似度*/val userSource_1: Vector[Int] = source(user1).values.toVector // 转换成Vector 也可以不用val userSource_2: Vector[Int] = source(user2).values.toVectorval toDouble: Double = userSource_1.zip(userSource_2).map((d: (Int, Int)) => d._1 * d._2).sum.toDouble // 得到分子部分// 得到分母的两个部分val user1Temp: Double = math.sqrt(userSource_1.map((x: Int) => {math.pow(x, 2)}).sum)val user2Temp: Double = math.sqrt(userSource_2.map((x: Int) => {math.pow(x, 2)}).sum)// 得到分母val d: Double = user1Temp * user2Temp// 返回结果toDouble/d
} def main(args: Array[String]): Unit = { System.setProperty(“hadoop.home.dir”, “H:\winutils\winutils-master\hadoop-2.6.0”) // 初始化数据 getSource() val name = “bbb” user.foreach((user: String) =>{ println(s”${name} 相对于 ${user} 的相似分数为: ${getCollaborateSource(name, user)}”) }) } ```

若有收获,就点个赞吧
0 人点赞
