一、数据库瓶颈
不管是IO瓶颈,还是CPU瓶颈,最终都会导致数据库的活跃连接数增加,进而逼近甚至达到数据库可承载活跃连接数的阈值。
1、IO瓶颈
第一种:磁盘读IO瓶颈,热点数据太多,数据库缓存放不下,每次查询时会产生大量的IO,降低查询速度 -> 分库和垂直分表。
第二种:网络IO瓶颈,请求的数据太多,网络带宽不够 -> 分库。
2、CPU瓶颈
第一种:SQL问题,如SQL中包含join,group by,order by,非索引字段条件查询等,增加CPU运算的操作 -> SQL优化,建立合适的索引,在业务Service层进行业务计算。
第二种:单表数据量太大,查询时扫描的行太多,SQL效率低,CPU率先出现瓶颈 -> 水平分表。
二、分库分表
1、水平分表
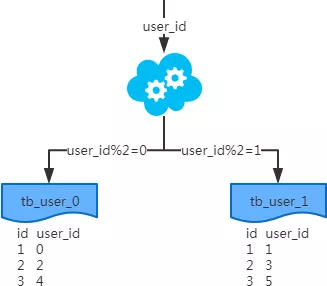
概念:以订单号做(hash、取模),将一个表中的数据拆分到多个表中。
场景:系统绝对并发量并没有上来,只是单表的数据量太多影响了SQL效率和CPU负担,以至于成为瓶颈。
分析:表的数据量少了,单次SQL执行效率高,自然减轻了CPU的负担。
2、水平分库
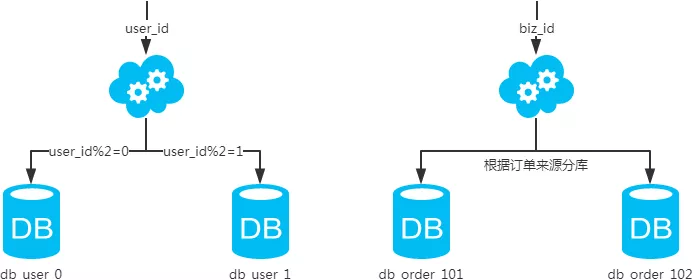
概念:以订单号做(hash、取模),将一个库中的数据拆分到多个库中。
场景:系统绝对并发量上来了,分表难以根本上解决问题,并且还没有明显的业务归属去垂直分库。
分析:库多了,io和cpu的压力自然可以成倍缓解。
3、垂直分表
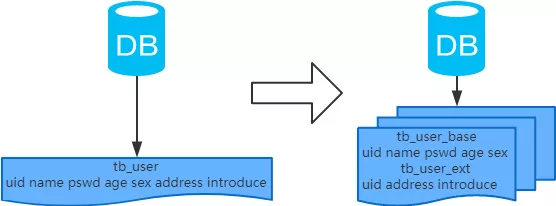
概念:以订单号为依据,创建主订单表和子订单表,子订单表除了记录子订单号,还需要记录主订单号。
结果:
- 每个表的结构都不一样
- 每个表的数据也不一样,一般来说,每个表的字段至少有一列交集,一般是主键,用于关联数据
- 所有表的并集是全量数据
场景:系统绝对并发量并没有上来,表的记录也不多,但是字段多,并且热点数据和非热点数据在一起,单行数据所需的存储空间较大。以至于数据库缓存的数据行减少,查询时会去读磁盘数据产生大量的随机读IO,造成IO瓶颈。
分析:可以设计列表页和详情页。拆分原则是把热点数据放在一起作为主表,非热点数据放在一起作为扩展表。拆了之后,要想获得全部数据就需要关联两个表来取数据。但是千万别用join,因为join不仅会增加Mysql处理压力还会将两个表耦合在一起。所以关联数据的操作尽量放在应用程序层面解决
4、垂直分库
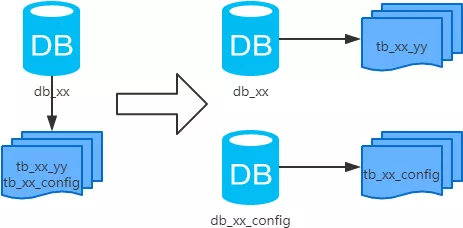
概念:一般到了垂直分库的地步,几乎就可以抽象出来单独的业务模块了,以表为依据,按照不同业务模块,将表拆分到不同的库中。
结果:
- 每个库的结构都不一样
- 每个库的数据也不一样,没有交集
- 所有库的并集是全量数据
场景:系统绝对并发量上来了,并且可以抽象出单独的业务模块。
分析:随着业务的发展一些公用的配置表、字典表等越来越多,这时可以将这些表拆到单独的库中,甚至可以服务化,去孵化出了一套新的业务模式。
三、分库分表工具
- sharding-sphere:jar,前身是sharding-jdbc
- TDDL:jar,Taobao Distribute Data Layer
- Mycat:中间件
注:工具的利弊,请自行调研,官网和社区优先。
四、分库分表步骤
首先应该根据当前容量和增长量评估分库和分表的个数,然后选择一个比较均匀的key,如果使用了雪花算法做订单号主键最好,订单号的后两位是userID,然后根据订单号后两位做hash或取模,查询的时候,就算只知道userID也能快速定位数据存在那张表里了,最后尽量保证数据同步完,再使用旧库提供服务。
五、那分表后的ID怎么保证唯一性的呢?
这里采用雪花方案,全局唯一ID生成由:时间戳+机器ID+自增序列(+userid后两位),可以直接在服务实例中生成订单,在内存中计算,解决性能问题
六、分库分表后的数据分页查询
水平分库分表:
电商系统订单成交后,如果买家需要查询订单,但是只有userid,全部表都遍历一遍不现实。所以还需要改进订单号,之前是【时间戳+机器ID+自增序列】。现在是【时间戳+机器ID+自增序列+userid后两位】。并且订单具体存储到那个数据库也是根据后两位取模而来,所以同一个买家的所有订单都会存入同一个表中,只需要去这表中查找就可以了。
- 卖家的订单可能分散在各个表中,查询起来很费劲,所以订单存储的同时,还需按照卖家维度再存入到别的库和表中,这个表专门提供卖家查询订单。
- 最耗费性能的一种,数据量不是很大的话,因为不清楚按照时间排序之后的第三页数据到底是如何分布在数据库上的,所以必须每个库都返回3页数据,再把得到的数据排序,得到全局视野,再从这些数据中找到第3页数据
垂直分库分表:
- 由于自增主键都还在,所以查询上好像每增加太多难度

若有收获,就点个赞吧
0 人点赞
