Redis下载地址:链接
Redis
Redis 是 C 语言开发的一个开源的高性能键值对(key-value)的内存数据库。
是一种 NoSQL(not-only sql,泛指非关系型数据库)的数据库。
数据在内存中,读写速度非常快,支持并发 10W QPS。
为什么这么快?
- k-v 数据结构简单,对数据操作也简单
- io多路复用器模块是单线程,避免了不必要的上下文切换和竞争条件(采用队列模式将并发访问变为串行访问)
Redis比memcached有哪些优势
- memcached所有的值均是简单的字符串,redis作为其替代者,支持更为丰富的数据类型(数据结构),减少IO
- 单线程请求,所有命令串行执行,并发情况下不需要考虑数据一致性问题。
- redis可以持久化其数据,memcache没有持久化功能,可以将内存中数据保存在磁盘中,重启时加载。
epoll
额外的探索
- 遵从 BSD 协议
- redis的key和string类型value限制均为512MB。
- 默认16个库
Reids常用5种数据类型及数据结构
☆Redis 内部内存管理
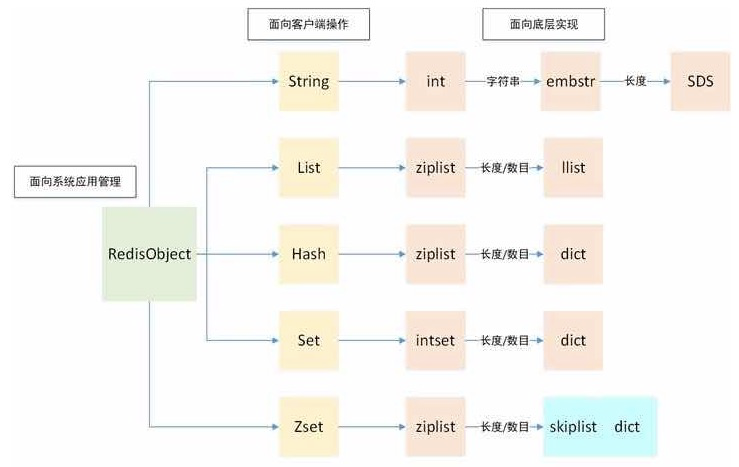
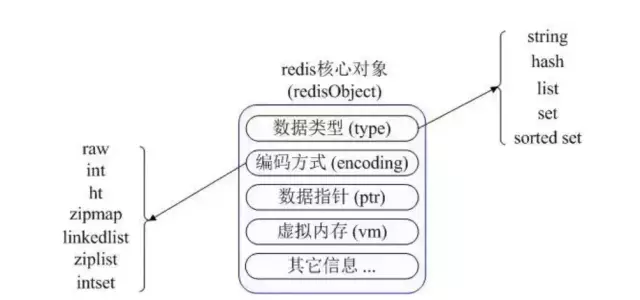
Redis 内部使用一个 redisObject 对象来表示所有的 key 和 value。
redisObject 最主要的信息:
- type值表示对象的属性也就是那5种类型。
- encoding值是底层实现类型。
- refcount是对象的引用次数,redis里面使用的是引用计数法去管理内存(因为系统已经是写死的,不会出现相互引用的情况),在每次释放资源的时候就会-1并检查是否为0为0就释放。
lru是这个对象最后一次被访问的时间,用于内存管理如果系统开了maxmemory并且服务器的内存回收算法是lru那么内存满后就会回收这些时间长的对象。
typedef struct redisObject {// 类型unsigned type:4;// 编码(底层实现类型)unsigned encoding:4;// 对象最后一次被访问的时间unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */// 引用计数int refcount;// 指向底层数据结构的指针void *ptr;} robj;
Redis内存模型
used_memory:Redis分配器分配的内存总量(单位是字节),包括使用的虚拟内存(即swap);Redis分配器后面会介绍。used_memory_human只是显示更友好。
- used_memory_rss: Redis进程占据操作系统的内存(单位是字节),与top及ps命令看到的值是一致的;除了分配器分配的内存之外,used_memory_rss还包括进程运行本身需要的内存、内存碎片等,但是不包括虚拟内存。
- mem_fragmentation_ratio: 内存碎片比率,该值是used_memory_rss / used_memory的比值。
- mem_allocator: Redis使用的内存分配器,在编译时指定;可以是 libc 、jemalloc或者tcmalloc,默认是jemalloc;截图中使用的便是默认的jemalloc。
客户端类型
1. String类型
set name zhaojianyu # 如果已经存在则会覆盖setnx name aaa # 如果已经存在,不会覆盖返回0set email 111@qq.comsetrange email 3 163.com # 从第四位开始替换,将qq.com替换为163.com# 设置为0时替换整个字符串get <key>
1.2 应用
- 计数器(浏览次数)
incr readcount::{帖子id} 执行+1 incrby key 3 加3incrby key -2 减2
- 分布式全局唯一id
- 分布式集群架构中的session(分布式,持久化)
- 分布式锁
2. Hash类型
hset/hmset设置值- hget / hmget
- hkeys 性能低 / hvalues获取所有值
- hgetall
2.2 应用
点赞,收藏,详情页
分布式缓存
2.3 删除大key
生产环境中遇到过多次因业务删除大Key,导致Redis阻塞,出现故障切换和应用程序雪崩的故障。如果数千w个元素的大Key时,会导致Redis阻塞上10秒可能导致集群判断Redis已经故障,出现故障切换;或应用程序出现雪崩的情况。
Redis是单线程处理。单个耗时过大命令,导致阻塞其他命令,容易引起应用程序雪崩或Redis集群发生故障切换。所以避免在生产环境中使用耗时过大命令。
应该从3.4版本开始,Redis会支持lazy delete free的方式,删除大键的过程不会阻塞正常请求
hscan命令
3. list类型 (栈)(数组) (优先级队列)
- LPUSH(RPUSH从链表尾部) key value1 [value2] 将一个或多个值插入到链表头部
- LPOP(RPOP) key 弹出一个元素
- LRANGE key start stop 获取列表指定范围内的元素 0 到 -1 取所有
- LTRIM key start stop 对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除。
- LSET /LINDEX 存取到指定位置
- LREM key 3 a 删除3个value为a
- LINSERT 在key前或者后插入元素
3.1 应用场景:
List 应用场景非常多,也是 Redis 最重要的数据结构之一,比如 Twitter 的关注列表,粉丝列表都可以用 List 结构来实现。
消息队列
3.2 数据结构
字符串长度及元素个数小于一定范围使用 ziplist 编码,任意条件不满足,则转化为 linkedlist 编码;
4. 集合Set(抽奖活动)
无序集合。
参加抽奖活动
- sadd key {userId} [user2]
获取所有抽奖用户 (消耗性能)
- smembers key
- srem key xxx 删除某个用户
抽取count名中奖者,并从抽奖活动中移除
- spop key count
抽取count名中奖者,不从抽奖活动中移除
srandmember key count count为正数,取出数量不能超过已有集合大小
负数时可能抽出重复
spop key count 抽出一个
sinner[store] 求交集
sunion 并集
sdiff 差集
数据结构
集合是通过哈希表(字典)实现的,所以添加,删除,查找的复杂度都是O(1)。
集合是通过 hashtable 实现的。Set 中的元素是没有顺序的,而且是没有重复的。常用命令:sdd、spop、smembers、sunion 等。
5. 有序集合ZSet (排行榜, 延迟队列*)
zset和set一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
zset的成员是唯一的,但分数(score)却可以重复。
- zadd 添加元素到集合,元素在集合中存在则更新对应score
- zcount key min max 查看分数范围内有多少数量
- zrange 查出索引下的数据 zrangebyscore通过分值取 还有反向取REV命令
zrange key 0 -1 withscores
- zscore key v 取出v的分值 , zrank key v 取出v的排名
- zincrby key score field 增加分数
- zrem key member [member…]
使用
Set<Tuple> tupleSet = client.zrangeByScoreWithScores(DELAY_QUEUE, 0, System.currentTimeMillis());for (Tuple t : tupleSet) {}
滑动窗口是限流常见的一种策略。如果我们把一个用户的 ID 作为 key 来定义一个 zset ,member 或者 score 都为访问时的时间戳。我们只需统计某个 key 下在指定时间戳区间内的个数,就能得到这个用户滑动窗口内访问频次,与最大通过次数比较,来决定是否允许通过。
内容小结
我们今天说来跳表这种数据结构。跳表使用空间换时间的设计思路,通过构建多级索引来提高查询的效率,实现了基于链表的”二分查找”。跳表也是一种动态的数据结构,支持快速的插入、删除、查找操作,时间复杂度都是O(logn)。
底层数据结构
- 字典:hashtable(拉链法单链表)、ziplist
String类型如果给一个整数就用int存,如果变成小的字符串就升级成embstr,如果字符串变大就升级成sds。
hash类型指向一个ziplist对象或者字典对象
Set类型指向一个intset对象或者字典对象
ZSet类型指向一个ziplist对象或者跳跃表+字典的组合结构对象
这里跳跃表加字典的组合结构,就是同时用字典和跳跃表去存储成员和score,优点是能以字典的特性在O(1)的时间查找某个值,以跳跃表的特性O(logN)的时间去查询范围。
以上结构(hash,list,zset)使用ziplist都是在数据量少的情况下,当数据量变多的时候就会将ziplist里面的数据转移到后面的对象中
Set如果最开始添加了一堆整数就是intset,加入了一些字符串或者元素个数超过512个就升级成字典。
1. int
存储数字的话,采用int类型的编码,如果是非数字的话,采用 raw 编码;
2. intset
typedef struct intset {
uint32_t encoding; // 编码类型 int16_t、int32_t、int64_t
uint32_t length; // 长度 最大长度:2^32
int8_t contents[]; // 柔性数组
} intset;
整数数据有序的存储在contents数组里面,通过二分查找来查找元素
2. embstr
Redis 的字符串共有两种存储方式,在长度特别短时,使用 emb 形式存储 (embedded),当长度超过44时,使用raw形式存储
embstr存储形式是这样一种存储形式,它将RedisObject 对象头和 SDS 对象连续存在一起,使用 malloc 方法一次分配。而raw存储形式不一样,它需要两次 malloc,两个对象头在内存地址上一般是不连续的
2. 动态字符串
简单动态字符串SDS 数据类型的定义:
1、len 保存了SDS保存字符串的长度
2、buf[] 数组用来保存字符串的每个元素
3、free 记录了 buf 数组中未使用的字节数量
Redis 中会涉及到字符串频繁的修改操作,SDS 实现了两种优化策略
- 空间预分配
对 SDS 修改及空间扩充时,除了分配所必须的空间外,len 长度小于 1M,那么将会额外分配与 len 相同长度的未使用空间。如果修改后长度大于 1M,那么将分配1M的使用空间。
- 惰性空间释放
SDS 缩短时,并不会回收多余的内存空间,而是使用 free 字段将多出来的空间记录下来。如果后续有变更操作,直接使用 free 中记录的空间,减少了内存的分配
- 二进制安全
不同于C语言以\0结尾,redis提取字符串是依据长度提取这样就保证安全。
3. 压缩链表ziplist
压缩列表的内存是连续分配的,遍历的速度很快。
压缩列表是 Redis 为了节约内存而开发的, 由一系列特殊编码的连续内存块组成的顺序型(sequential)数据结构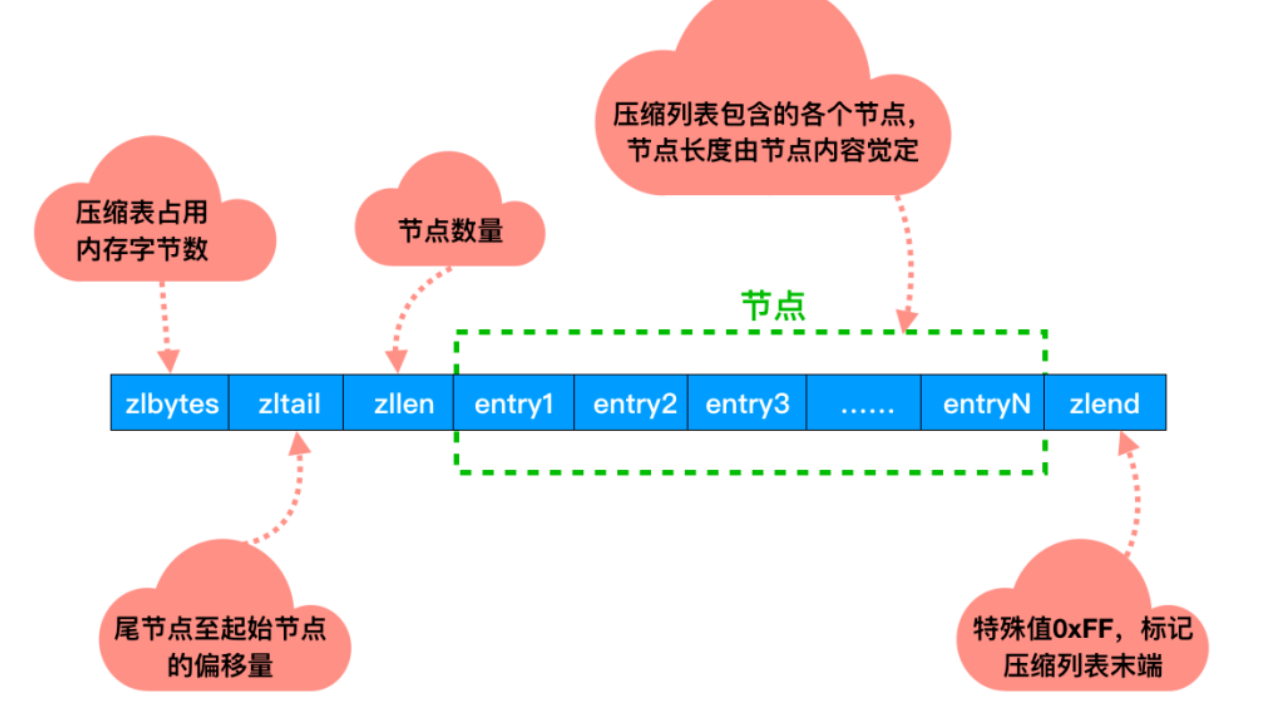
2. 字典
字典 数组+链表
typedef struct dict{
//类型特定函数
dictType *type;
//私有数据
void *privdata;
//哈希表
dictht ht[2];
//rehash索引
//当rehash不在进行时,值为-1
int rehashidx;
}dict;
rehash 扩容
Redis 为了高性能,不能堵塞服务,所以采用了 渐进式 rehash 策略。
渐进式 rehash 会在 rehash 的同时,保留新旧两个 hash 结构,查询时会同时查询两个hash 结构,然后在后续的定时任务中以及 hash 的子指令中,循序渐进地将旧 hash 的内容一点点迁移到新的 hash 结构中。
当 hash 移除了最后一个元素之后,该数据结构自动被删除,内存被回收。
不同于字符串一次性需要全部序列化整个对象,hash 可以对用户结构中的每个字段单独存储。这样当我们需要获取用户信息时可以进行部分获取。而以整个字符串的形式去保存用户信息的话就只能一次性全部读取,这样就会比较浪费网络流量。
正常情况下,当 hash 表中元素的个数等于第一维数组的长度时,就会开始扩容,扩容的新数组是原数组大小的 2 倍。不过如果 Redis 正在做 bgsave,为了减少内存页的过多分离 (Copy On Write),Redis 尽量不去扩容 (dict_can_resize),但是如果 hash 表已经非常满了,元素的个数已经达到了第一维数组长度的 5 倍 (dict_force_resize_ratio),说明 hash 表已经过于拥挤了,这个时候就会强制扩容。
4. 双向链表
双向链表,既可以支持反向查找和遍历,更方便操作,不过带来了额外的内存开销。
特性:
- 链表里每个节点都带有两个指针,prev 指向前节点,next 指向后节点。这样在时间复杂度为 O(1) 内就能获取到前后节点。
- 头节点里有 head 和 tail 两个参数,分别指向头节点和尾节点。这样的设计能够对双端节点的处理时间复杂度降至 O(1)
- 头节点里同时还有一个参数 len
5. 跳表
zset 对象中保存的元素个数小于及成员长度小于一定值使用 ziplist 编码,任意条件不满足,则使用 skiplist 编码。
Redis Sorted Set 的内部使用 HashMap 和跳跃表(skipList)来保证数据的存储和有序,HashMap 里放的是成员到 Score 的映射。
而跳跃表里存放的是所有的成员,排序依据是 HashMap 里存的 Score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。
‘skiplist 跳表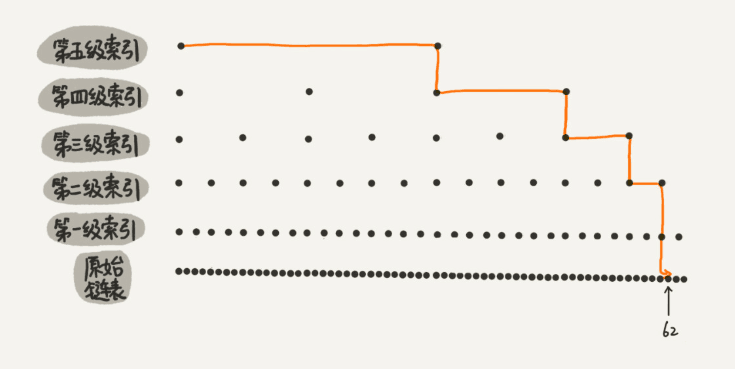
跳表就是在链表上加了多级索引和指针帮助我们提高搜索效率。
时间复杂度是O(logn)
跳表是通过随机函数来维护前面提到的平衡性。
- 跳表是可以实现二分查找的有序链表;
- 每个元素插入时随机生成它的level;
- 最底层包含所有的元素;
- 如果一个元素出现在level(x),那么它肯定出现在x以下的level中;
- 每个索引节点包含两个指针,一个向下,一个向右;(笔记目前看过的各种跳表源码实现包括Redis 的zset 都没有向下的指针,那怎么从二级索引跳到一级索引呢?留个悬念,看源码吧,文末有跳表实现源码)
- 跳表查询、插入、删除的时间复杂度为O(log n),与平衡二叉树接近;
为什么Redis要用跳表来实现有序集合,而不是红黑树呢?
Redis中的有序集合是通过跳表来实现的,严格点讲,其实还用到了散列表。如果查看redis开发手册会发现,redis中的有序集合支持的核心操作主要有:
- 插入一个数据
- 删除一个数据
- 查找一个数据
- 按照区间查找数据
- 迭代输出有序序列
其中,插入、删除、查找以及迭代输出有序序列,红黑树也可以完成,时间复杂度和跳表一样。但是按照区间来查找数据这个操作,红黑树的效率没有跳表高。
对于按照区间查找数据这个操作,跳表可以做到O(logn)的时间复杂度定位区间的起点,然后在原始链表中顺序往后遍历就可以了。
当然,redis之所以用跳表来实现有序集合还有其它的原因。比如,相比于红黑树,跳表的代码看起来更易于理解、可读性更好也不容易出错。而且跳表也更加的灵活,他可以通过改变索引构建策略,有效平衡执行效率和内存消耗。
不过,跳表也不能完全代替红黑树。红黑树比跳表出现的更早一些,很多编程语言中的Map类型都是基于红黑树实现的,当我们做业务开发的时候直接拿来用就好了,但是对于跳表我们就需要手动实现了。
6. stream
Redis Stream提供了消息的持久化和主备复制功能、新的RadixTree数据结构来支持更高效的内存使用和消息读取、甚至是类似于Kafka的Consumer Group功能。
7. bitmap
BitMap是什么就是通过一个bit位来表示某个元素对应的值或者状态,其中的key就是对应元素本身。我们知道8个bit可以组成一个Byte,所以bitmap本身会极大的节省存储空间。setbitgetbitbitcount
使用场景:用户在线状态前段时间开发一个项目,对方给我提供了一个查询当前用户是否在线的接口。不了解对方是怎么做的,自己考虑了一下,
使用bitmap是一个节约空间效率又高的一种方法,只需要一个key,然后用户ID为offset,如果在线就设置为1,
不在线就设置为0,和上面的场景一样,5000W用户只需要6MB的空间。
- 签到系统
Redis的位图数据结构就派上用场了,这样每天的签到记录只占据一个位, 365 天就是 365 个位,一个字节是8位,也就是一个用户签到一年,差不多46 个字节就可以完全容纳下,这就大大节约了存储空间。
redis> SETBIT bit 25 1
(integer) 0
redis> GETBIT bit 25
(integer) 1
redis> GETBIT bit 26 # bit 默认被初始化为 0
(integer) 0
发布订阅,hyperloglog
redis命令
基本命令
启动客户端:
redis-cli -h master -p 6379 -a root
Redis的常用命令主要分为两个方面、一个是键值相关命令、一个是服务器相关命令
1、键值相关命令
keys * 取出当前所有的key
exists name 查看redis是否有name这个key
del name / del key1 key2 key3 删除key name
rename key2 key3 重命名key2 为key3
type key 查看类型
select 0 选择到0数据库 redis默认的数据库是0~15一共16个数据库
move key 1 将当前数据库中的key移动到其他的数据库中,
randomkey 随机返回数据库里面的一个key
2、服务器相关命令
ping PONG返回响应是否连接成功
echo 在命令行打印一些内容
select 0~15 编号的数据库
quit /exit 退出客户端
dbsize 返回当前数据库中所有key的数量
info 返回redis的相关信息
flushdb 删除当前选择数据库中的所有key
flushall 删除所有数据库中的数据库
3、有效期命令
setex color 10 red # 设置color有效期为10秒
expire name 5 # 给key为name的设置5秒有效期
ttl name # 查看key为name的剩余有效期
persist name #取消过期时间
高级特性
- HyperLogLog基数统计 2.8.9在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。菜鸟教程之hyperLogLog
统计在线用户数||||统计用户每天搜索不同词条的个数
网站访问统计
- Geo3.2
将指定的地理空间位置(纬度、经度、名称)添加到指定的key中。
返回两个给定位置之间的距离。
支持存储地理位置信息用来实现诸如摇一摇,附近位置这类依赖于地理位置信息的功能。 - Pub/Sub发布订阅 . 菜鸟教程
- Redis Module扩展模块4.0
- BloomFilter
- RedisSearch
- Redis-ML
redis高级命令
事务
多个事务, exec先到先执行
Redis 事务可以一次执行多个命令,单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以 Redis 事务的执行并不是原子性的。
事务可以理解为一个打包的批量执行脚本,但批量指令并非原子化的操作,中间某条指令的失败不会导致前面已做指令的回滚,也不会造成后续的指令不做。
多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。
常用命令MULTI、EXEC、DISCARD、WATCH(客户端修复后果)multi开启事务exec提交事务discard回滚
配置命令
27.0.0.1:6379> CONFIG GET *
27.0.0.1:6379> CONFIG SET 属性名称 新值
查询redis当前的连接数(连接的客户端数量)
info clients
使用info 命令查看redis使用情况(负载状态)
127.0.0.1:6379> info
127.0.0.1:6379> info Server
面试题
(1) 使用过Redis做异步队列么,你是怎么用的?
一般使用list结构作为队列,rpush生产消息,lpop消费消息。当lpop没有消息的时候,要适当sleep一会再重试。如果对方追问可不可以不用sleep呢?list还有个指令叫blpop,在没有消息的时候,它会阻塞住直到消息到来。
如果对方追问能不能生产一次消费多次呢?使用pub/sub主题订阅者模式,可以实现1:N的消息队列。如果对方追问pub/sub有什么缺点?在消费者下线的情况下,生产的消息会丢失,得使用专业的消息队列如rabbitmq等。
如果对方追问redis如何实现延时队列?
使用sortedset,拿时间戳作为score,消息内容作为key调用zadd来生产消息,消费者用zrangebyscore指令获取N秒之前的数据轮询进行处理。
(2) Pipeline有什么好处,为什么要用pipeline?
可以将多次IO往返的时间缩减为一次,前提是pipeline执行的指令之间没有因果相关性。使用redis-benchmark进行压测的时候可以发现影响redis的QPS峰值的一个重要因素是pipeline批次指令的数目。

若有收获,就点个赞吧
0 人点赞
