功能介绍
- 拼写检查
- 自动建议查询词(自动补全)
官网:
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-suggesters.html
Suggesters基本的运作原理是将输入的文本分解为token,然后在索引的字典里查找相似的term并返回。
图示: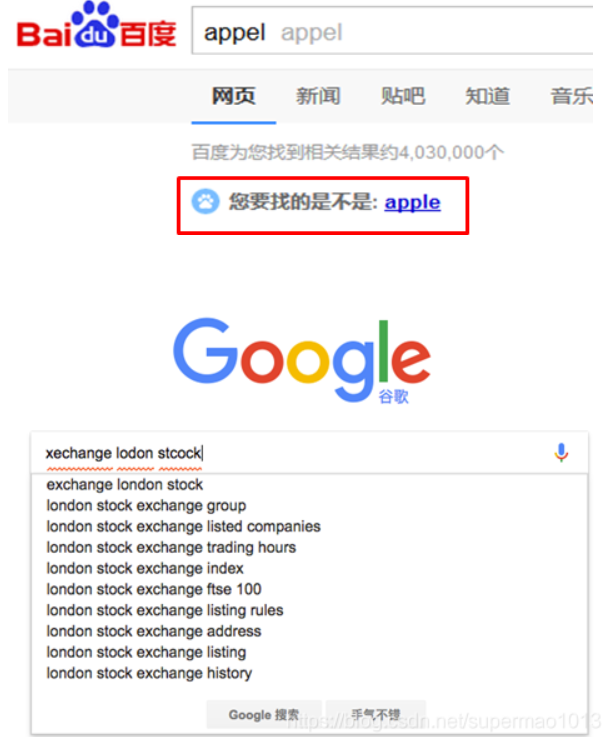
ES查询建议API
查询建议也是使用_search端点地址,在DSL中suggest节点来定义需要的建议查询。
POST twitter/_search{"query" : {"match": {"message": "tring out Elasticsearch"}},"suggest" : {"my-suggestion" : { #一个查询建议名称"text" : "tring out Elasticsearch", #查询文本"term" : {"field" : "message" #指定在哪个字段上获取建议词}}}}#多个建议查询可以使用全局的查询文本POST _search{"suggest": {"text" : "tring out Elasticsearch","my-suggest-1" : {"term" : {"field" : "message"}},"my-suggest-2" : {"term" : {"field" : "user"}}}}
Suggester介绍
term suggester
term 词项建议器,对给入的文本进行分词,为每个词进行模糊查询提供词项建议。对于在索引中存在词默认不提供建议词,不存在的词则根据模糊查询结果进行排序后取一定数量的建议词。
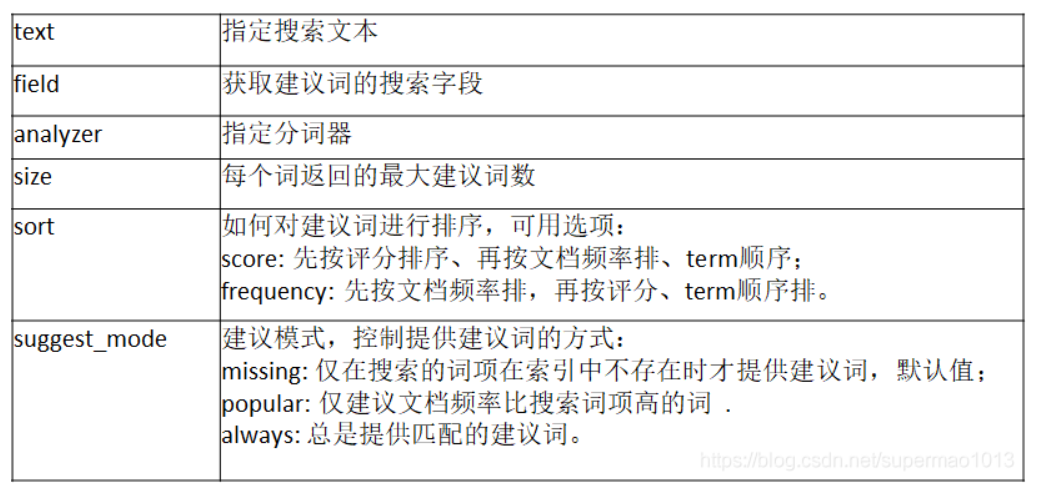
phrase suggester
phrase 短语建议,在term的基础上,会考量多个term之间的关系,比如是否同时出现在索引的原文里,相邻程度,以及词频等
POST /ftq/_search{"query": {"match_all": {}},"suggest" : {"myss":{"text": "java sprin boot","phrase": {"field": "title"}}}}
completion suggester 自动补全
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-suggesters.html#completion-suggester
针对自动补全场景而设计的建议器。
此场景下用户每输入一个字符的时候,就需要即时发送一次查询请求到后端查找匹配项,在用户输入速度较高的情况下对后端响应速度要求比较苛刻。
因此实现上它和前面两个Suggester采用了不同的数据结构,索引并非通过倒排来完成,而是将analyze过的数据编码成FST和索引一起存放。
对于一个open状态的索引,FST会被ES整个装载到内存里的,进行前缀查找速度极快。但是FST只能用于前缀查找,这也是Completion Suggester的局限所在。
Context Suggester
完成建议者考虑索引中的所有文档,但通常希望提供经过筛选和/或由某些标准增强的建议。
实战
为了使用自动补全,索引中用来提供补全建议的字段需特殊设计,字段类型为 completion。
定义一个索引:
PUT music{"mappings": {"_doc" : {"properties" : {"suggest" : {"type" : "completion" #定义该字段是自动补全的字段},"title" : {"type": "keyword"}}}}}
存入文档1和文档2,两个文档内容一样:
PUT music/_doc/1?refresh{"suggest" : {"input": [ "Nevermind", "Nirvana" ], #指定输入值"weight" : 34 #指定排序值(可选)}}PUT music/_doc/2?refresh{"suggest" : {"input": [ "Nevermind", "Nirvana" ],"weight" : 20}}
查询看看:
POST music/_search?pretty{"suggest": {"song-suggest" : {"prefix" : "nir","completion" : {"field" : "suggest"}}}}POST music/_search?pretty{"suggest": {"song-suggest" : {"prefix" : "nir","completion" : {"field" : "suggest","skip_duplicates": true #去重}}}}
接着存入文档3和文档4,存的是短语:
PUT music/_doc/3?refresh{"suggest" : {"input": [ "lucene solr", "lucene so cool","lucene elasticsearch" ],"weight" : 20}}PUT music/_doc/4?refresh{"suggest" : {"input": ["lucene solr cool","lucene elasticsearch" ],"weight" : 10}}
再查询看看:
POST music/_search?pretty{"suggest": {"song-suggest" : {"prefix" : "lucene s","completion" : {"field" : "suggest" ,"skip_duplicates": true}}}}
参考文章: https://blog.csdn.net/supermao1013/article/details/84311057

若有收获,就点个赞吧
0 人点赞
