介绍
跳表是可以实现了二分查找的有序链表,就比如拿普通的链表的来说,如果想查找一个元素,那么只能从头开始找,时间复杂度为O(n),而跳表是通过在原始链表的基础上创建多层的索引结构,查找的某一个元素的时候就可以使用类似二分查找的方式从上到下查找元素。查询、插入、删除的时间复杂度都是O(log n),与平衡二叉树差不多,但是比平衡二叉树简单,范围查找时比红黑树速度更快为O(logn)。
理解跳表,从单链表开始说起
下图是一个简单的有序单链表,单链表的特性就是每个元素存放下一个元素的引用。即:通过第一个元素可以找到第二个元素,通过第二个元素可以找到第三个元素,依次类推,直到找到最后一个元素。
现在我们有个场景,想快速找到上图链表中的 10 这个元素,我们从链表中每两个元素抽出来,加一级索引,一级索引指向了原始链表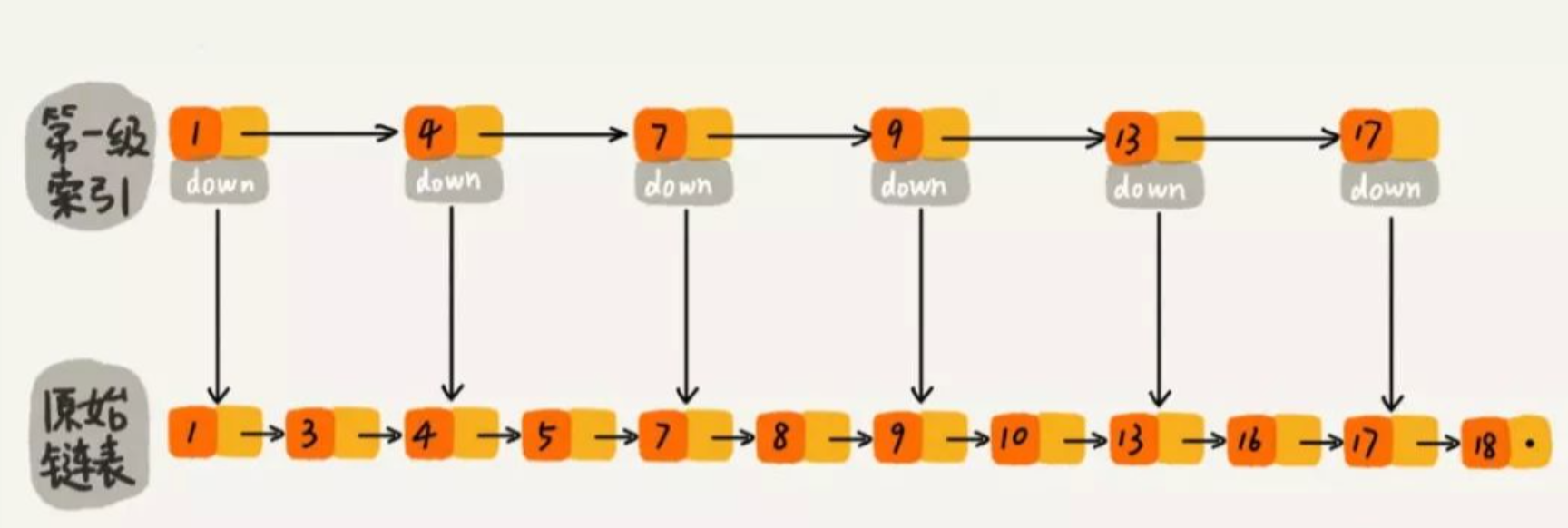
先在索引找 1、4、7、9,遍历到一级索引的 9 时,发现 9 的后继节点是 13,比 10 大,于是不往后找了,而是通过 9 找到原始链表的 9,然后再往后遍历找到了我们要找的 10。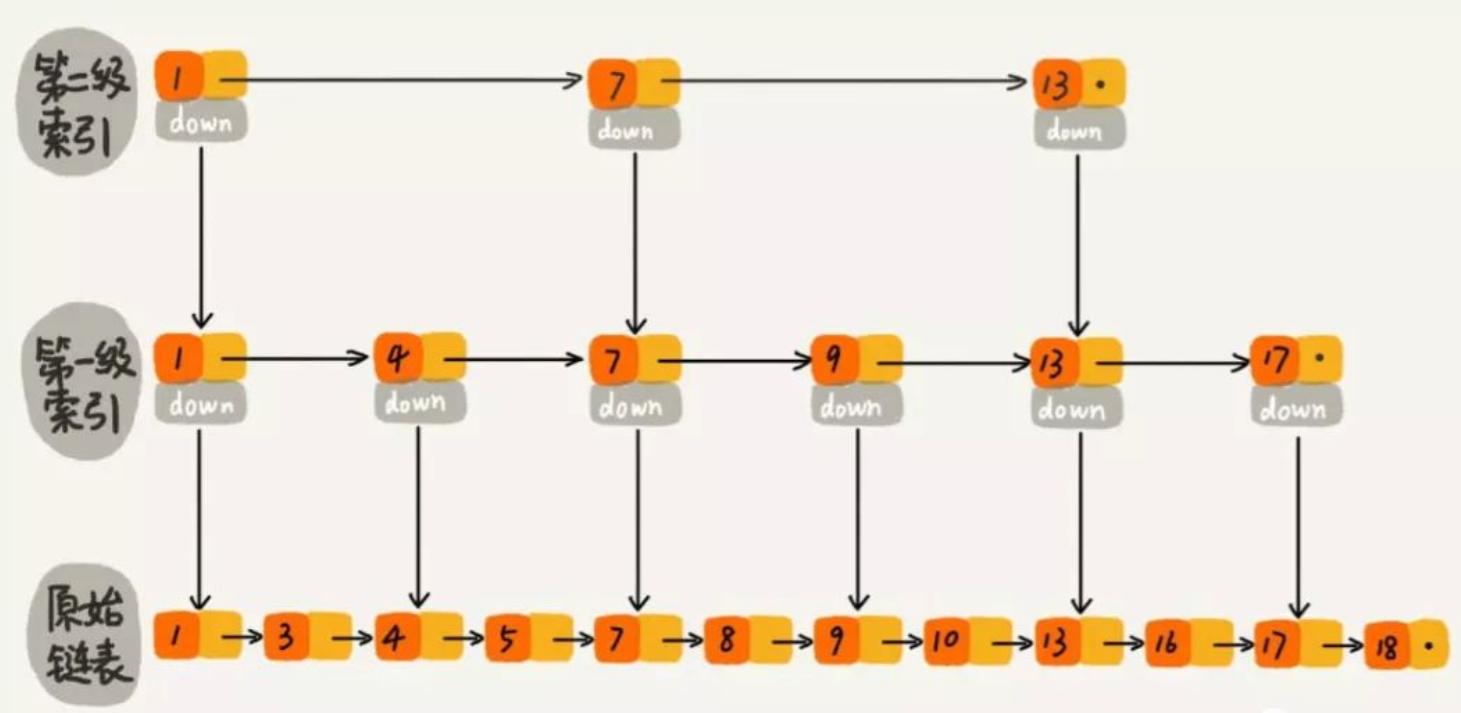
查找数据O(logn)从上到下
查找元素使用类似二分查找的方法,时间复杂度为O(logn),在Redis中使用散列表将查找的时间复杂度降为O(1)
插入数据O(logn)先从上到下找到位置,然后自底向上插入
插入数据的时候需要先查找到元素,然后插入元素,但是需要维护索引,如果不维护索引,那么随着数据越来越多,使用索引查找的复杂度由O(logn)变为O(n)
维护索引的设计思路
可以设计一种策略,保证原始链表每两个元素中选出一个元素建立一级索引,然后一级索引每两个选出一个再建立二级索引。如果要实现这种策略,就需要维护一个概率算法,每次插入新元素的时候,让这个元素有1/2的几率建立一级索引、1/4的几率建立二级索引、1/8的几率建立三级索引,以此类推。
概率算法代码设计思路
我们可以实现一个random()方法,这个方法会随机生成1~MAXLEVEL之间的数(MAXLEVEL表示索引的最高层数),并且这个方法有1/2的概率返回1那么就不创建索引、1/4的概率返回2就创建一级索引、1/8的概率返回3那么就创建二级索引,以此类推。然后就可以通过这个random() 方法,控制新元素的插入,进而控制整个跳表每级索引中元素的个数。补充:(这个和我之前写过的加权轮询的算法类似,但是那个是平滑的,你能找出每一轮分配的规律,而这个是完全随机,类似投硬币,正反面概率只是趋近1/2,但是谁都不能保证是1/2,所以我感觉我的比较高级,这个使用Python的random.choice就可以实现)
不知道在这里你是否有疑问?
random()方法返回2表示需要建立一级索引,但是我们想要控制一级索引元素个数为1/2,而random()方法返回2的概率为1/4,这是不是有问题,下面我举个例子证明这个是没问题的?
举例证明一级索引元素个数为1/2
不知道你有没有发现了一个特点:当建立二级索引的时候,同时也需要建立一级索引;同理,当建立三级索引时,也会建立一级、二级索引。所以根据random()概率算法代码逻辑可以知道只要返回值>1就会建索引,但是无论建几级索引都必然会有一级索引,又因为random()方法返回1的概率为1/2,所以random()返回值>1的概率为1 - 1/2 = 1/2。通过这个流程就可以证明一级索引中元素个数占原始数据个数的 1/2。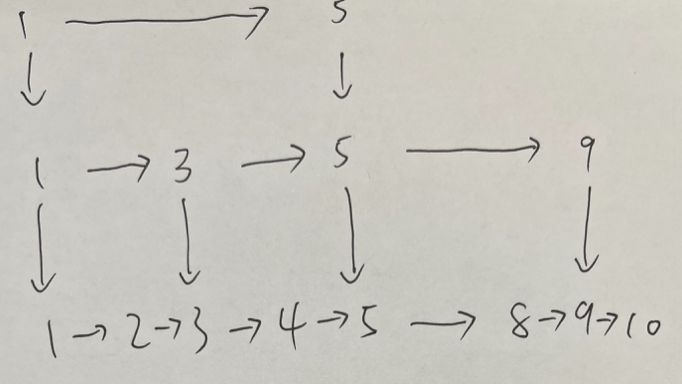
时间复杂度
下面来算一下插入的时间复杂度,因为插入数据的时候需要先查找元素O(logn),又因为元素插入到单链表的时间复杂度为O(1),索引的高度最多为logn(两个选一个,推算出是logn),所以最坏情况就是每层都插入新元素,总时间复杂度是 O(logn)。【查找元素的时间复杂度+插入logn个元素元素的时间复杂度】为 O(logn) + O(logn) = 2O(logn),插入元素的时间复杂度为 O(logn)。
删除数据O(logn)先从上到下找,找到后删除
时间复杂度
删除元素的过程跟查找元素的过程类似,只不过查找后需要执行删除操作。因为跳表中每一层索引都是一个有序的单链表,单链表删除元素的时间复杂度为O(1),索引的高度最多为logn,所以最坏情况就是每层都需要删除元素,总时间复杂度是 O(logn),【查找元素的时间+删除logn个元素的时间】为 O(logn) + O(logn) = 2 O(logn),删除元素的时间复杂度为 O(logn)。
空间复杂度O(n)
跳表通过建立索引提高查找元素的效率,是一种典型的“空间换时间”的思想。
假如原始链表有n个元素,那么一级索引元素个数是n/2、二级索引元素个数是n/4、三级索引元素个数是n/8,以此类推。总结一下就可以发现这是一个等比数列,a1=n/2,q=1/2,当n趋于无穷大的时候,总和就等于n/2 + n/4 + n/8 + … + 8 + 4 + 2 = n-2,空间复杂度是 O(n)。但是索引结点只会存储key和指针,并不需要存储完整的对象,所以当对象比索引大很多时,索引占用的空间复杂度是 O(1)。
为什么Redis选择使用跳表而不是红黑树来实现有序集合?
由以下四个方面对比跳表和红黑树:
- 插入一个元素
- 删除一个元素
- 查找一个元素
- 按照范围查找元素(比如查找值在 [100, 356] 之间的数据)
其中,前三个操作红黑树也可以完成,且时间复杂度跟跳表是一样的。但是按照范围来查找数据这个操作,红黑树的效率没有跳表高,因为跳表是先通过 O(logn)的时间复杂度查找到数据起点,然后在原始链表中顺序遍历就可以了,并且在Redis中可以散列表将查找的时间复杂度降为O(1)

若有收获,就点个赞吧
0 人点赞
