:::info 本文主要参考:Retrieval-Augmented Generation for Large Language Models: A Survey
:::
当下领先的大语言模型 (LLMs) 是基于大量数据训练的,目的是让它们掌握广泛的普遍知识,这些知识被储存在它们神经网络的权重(也就是参数记忆)里。但是,如果我们要求 LLM 生成的回答涉及到它训练数据之外的知识——比如最新的、专有的或某个特定领域的信息——这时就可能出现事实上的错误(我们称之为“幻觉”)。比如:
当前主流模型优化方法
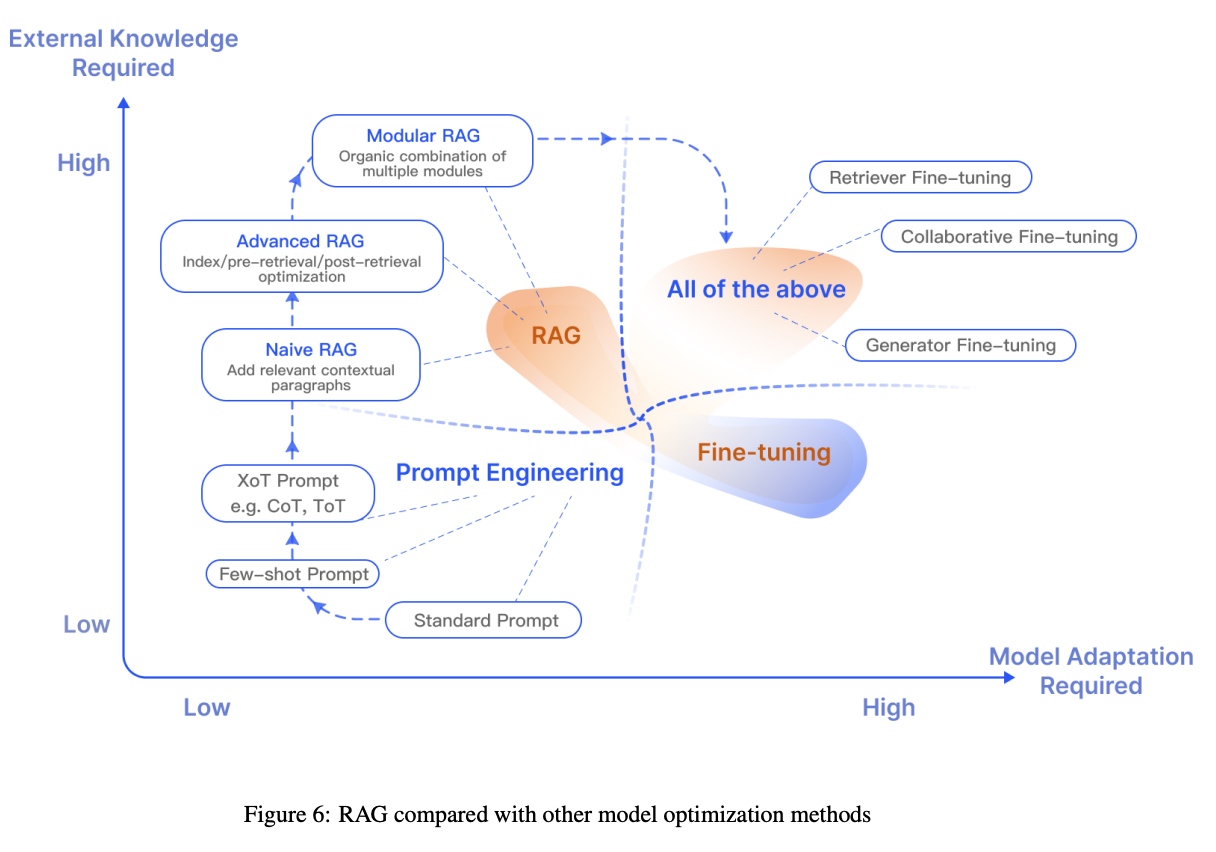
当前主流的模型优化方法主要有以下几种:
- Prompt Engineering:即提示词工程,比如Few-shot Prompt,思维链 COT ,思维树 TOT,思维图 GOT 等。
- Fine-tuning:即模型微调,在已有预训练模型的基础上提供新的参数重新训练,以期增强特定方向的能力,缺点是训练成本较高,每次有新数据的时候都需要重新训练。
- RAG:即本文要说的检索增强生成,旨在为大语言模型(LLM)提供额外的、来自外部知识源的信息,优势是成本较低,当前比较主流的优化方法。
Devv.ai
Devv.ai 是一个面向开发者的 AI 搜索引擎,也使用了 RAG 这项技术,有兴趣的同学可以追踪开发者的 X Thread,其实看这篇帖子也足够了解了:
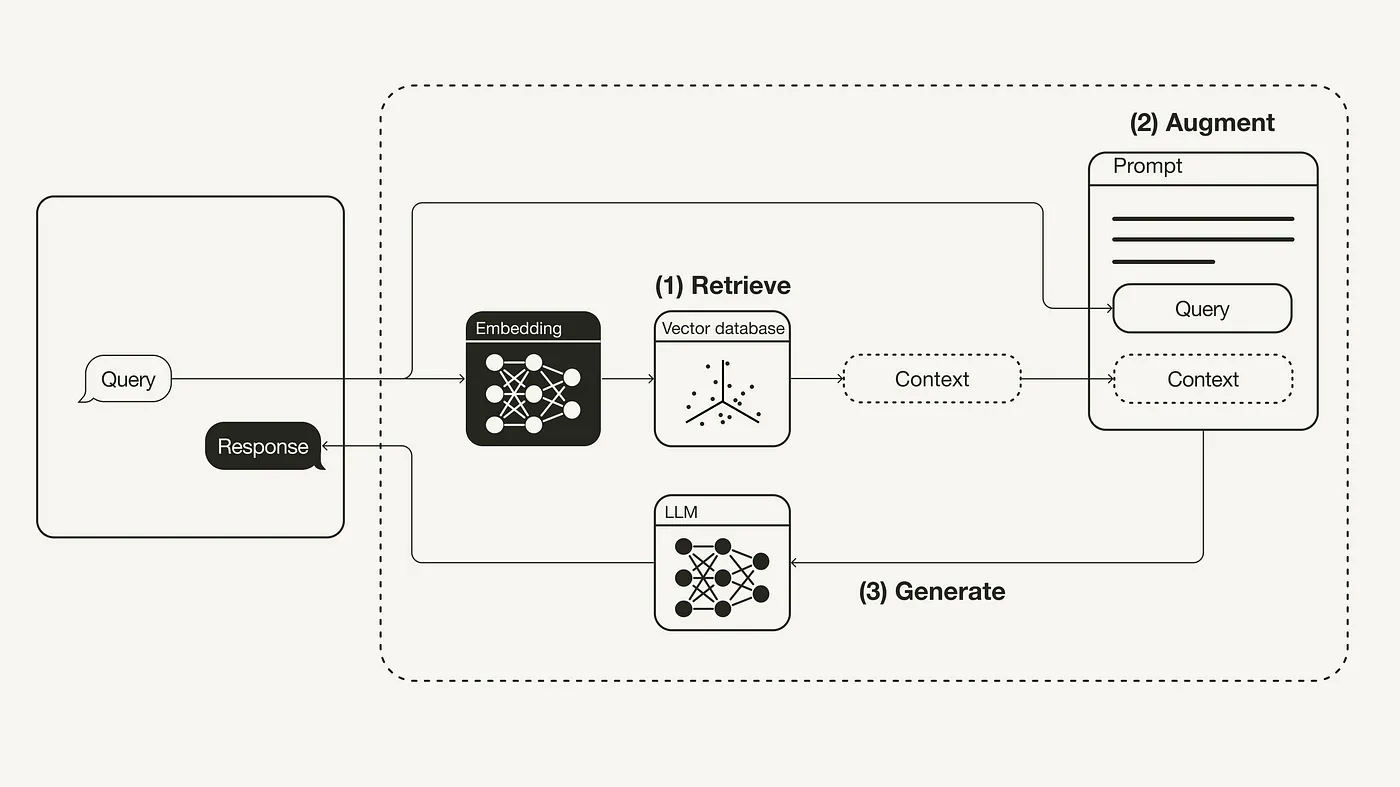
什么是 RAG?
RAG 是英文 Retrieval-Augmented Generation 的缩写,中文译为:检索增强生成。最初来源于 2020 年 Facebook 的一篇论文:Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,嗯,是的,这个技术实际在 2020 年就已经提出。
大型语言模型(LLMs)展示了显著的能力,但面临幻觉、过时知识和非透明、不可追踪的推理过程等挑战。检索增强生成(RAG)已经成为一种有前途的解决方案,通过整合来自外部数据库的知识来提高模型的准确性和可信度,特别适用于知识密集型任务,并允许持续更新知识和整合领域特定信息。RAG通过将LLMs的内在知识与外部数据库的庞大、动态知识库相结合,提高了模型提供准确和相关响应的能力,从而缓解了传统LLMs面临的限制。
检索增强生成(RAG)是一个概念,它旨在为大语言模型(LLM)提供额外的、来自外部知识源的信息。这样,LLM 在生成更精确、更贴合上下文的答案的同时,也能有效减少产生误导性信息的可能。
RAG 工作流程示意图
参考:
检索增强生成(RAG):从理论到 LangChain 实践 [译]
向量数据库
向量数据库,用于计算向量距离:
专栏 - 在 AI 时代,开发者还需要传统数据库吗? | TiDB 社区
Getting Started with Weaviate: A Beginner’s Guide to Search with Vector Databases
术语解释
Few-shot Prompt
:::info “Few-shot prompt”是一种机器学习领域的术语,指的是在模型训练过程中只使用少量样本数据来进行学习的技术。这种方法通常用于解决数据稀缺的问题,通过在少量样本上训练模型来实现对新任务或新类别的泛化能力。Few-shot learning技术在自然语言处理、计算机视觉等领域得到广泛应用,能够帮助模型更好地适应新的数据和任务。
:::
COT 思维链
:::info 思维链(Chain of Thought,CoT)是大模型在处理复杂问题时的一种提示方法,要求模型在输出最终答案之前,显式输出中间逐步的推理步骤。这种方法可以增强大模型的逻辑推理能力,使其能够展示推理过程,而不仅仅是给出最终答案。思维链的核心思想是向大语言模型展示一些少量的示例,解释推理过程,从而引导模型进行推理。通过思维链,模型可以更好地处理复杂问题,尤其是需要逻辑推理的数学题等情景 。
:::
参考

若有收获,就点个赞吧
0 人点赞
