什么是 Token?
在 ChatGPT 中,token 是指文本被切割成的最小单位,而计算 token 数量是为了衡量文本的长度,从而确定是否符合模型的限制。It’s important to note that the exact tokenization process varies between models. Newer models like GPT-3.5 and GPT-4 use a different tokenizer than our legacy GPT-3 and Codex models, and will produce different tokens for the same input text.需要注意的是不同模型之间使用的分词器是不同的,这点需要注意区分。比如 GPT 3.5 和 GPT 4.0 的分词方式相同,一个中文字符通常被算作一个 token,而在 GPT 3 中会被计算为两个 token。
为什么要注意 Token 管理?
https://platform.openai.com/docs/guides/text-generation/managing-tokens
在 OpenAI 的文档中也写到了:
- 首先关系到你的费用情况,因为 ChatGPT 是通过 token 数量付费。
- 其次关系到回答的时长,token 越长回答时间越长。
- 最后关系到 API 是否能够正常使用,因为总的 token 不能超过模型的上限。
需要注意的一点是输入的 Token 和输出的 Token 都会被计算入总量,如果对话过长的话回复会被截断。
OpenAI 分词器体验
OpenAI 提供了分词器供用户了解大模型是如何分词的:
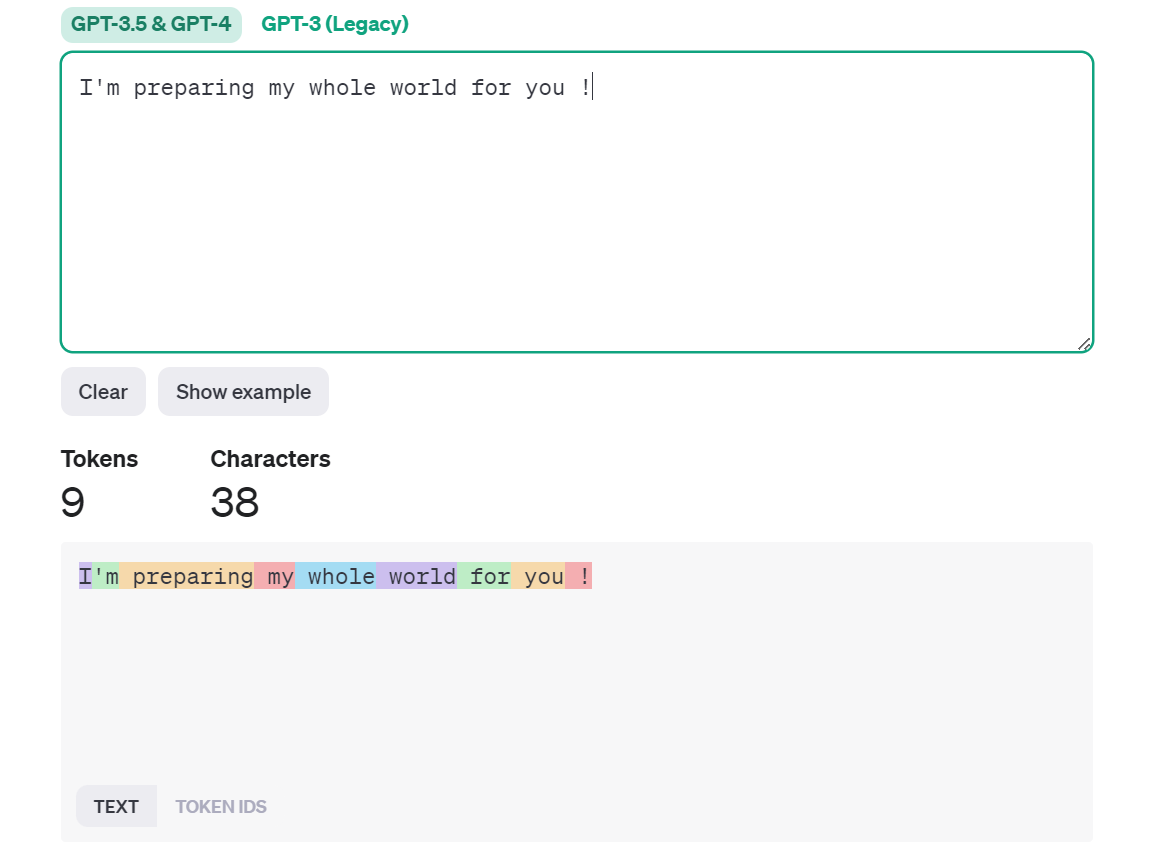
ChatGPT 的 Token 计算规则
- 对于英文单词和标点符号,一个 token 通常对应一个字符。
- 对于常见的非英文语言,一个 token 也通常对应一个字符。
- 对于一些特殊字符和罕见的非英文字符,一个token可能对应多个字符。
- 对于中文字符,一个 token 通常对应一个汉字。
- 在某些情况下,一个中文字符可能会被切割成多个 token。
TokenIDs
即 token 在分词字典中对应 ID:

如何计算分词
If you need a programmatic interface for tokenizing text, check out our tiktoken package for Python. For JavaScript, the community-supported @dbdq/tiktoken package works with most GPT models.
关于如何查看分词效果,OpenAI 本身除了一个 tiktoken 的 python 包,而对于其他语言则由社区同学开发维护,比如 JS 可以使用 tiktoken。
JS 版本的 tiktoken 提供两种使用方式,一种是对原 python 包的 wasm 绑定,另一种是纯 js 重写的 js-tiktoken:
npm install js-tiktoken
import assert from "node:assert";import { getEncoding, encodingForModel } from "js-tiktoken";const enc = getEncoding("gpt2");assert(enc.decode(enc.encode("hello world")) === "hello world");
分词器编码
不同模型使用的分词器不同,ChatGPT 和 GPT-4所使用的是同一个,名为“cl100k_base”的词表,其词典参考:https://raw.githubusercontent.com/weikang-wang/ChatGPT-Vocabulary/main/cl100k_base_vocab.json
参考文章

若有收获,就点个赞吧
1 人点赞
