插件简介
官网简介:
:::info Segment Anything Model (SAM): a new AI model from Meta AI that can “cut out” any object, in any image, with a single click.
:::
简单而言,SAM 是一个 Meta 出品的 AI 模型,用于一键将物体从图中分割出来,在 AIGC 领域非常有用,你可以通过该插件准确标注出你想要 AI 重绘的区域从而精确生成。该插件可以用来代替 Photoshop 等专业软件的抠图功能,可以为不太会使用专业工具的人提供便利。关于局部重绘可以参考:
插件地址
GitHub - continue-revolution/sd-webui-segment-anything: Segment Anything for Stable Diffusion WebUI
安装方式
扩展 => 从网址安装,或者直接将 git 仓库安装到 extensions 文件夹下,然后应用并重载前端。
git@github.com:continue-revolution/sd-webui-segment-anything.git
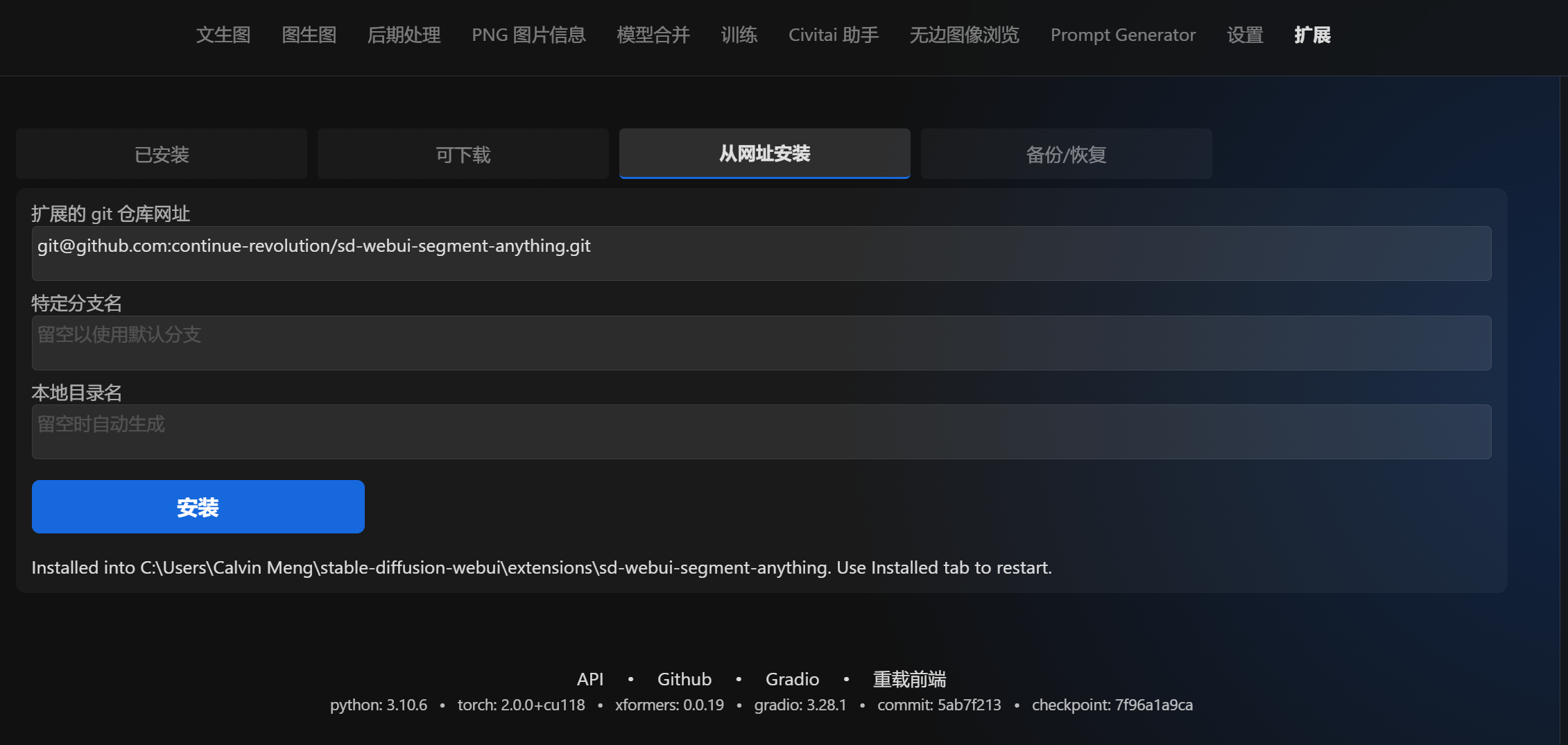
在文生图或者图生图中能够看到插件配置页面即可:

下载模型
在 sam 的 github 仓库下有三种不同类型的大模型,模型越大效果越好,但占用的显存也会越多,模型下载完成后放到sd目录下的 models/sam目录下。
:::color4 注意是 sd webui 的目录,以及注意不要改变模型名称,如果没有 sam 文件夹可以自行创建。
stable-diffusion-webui\models\sam
:::
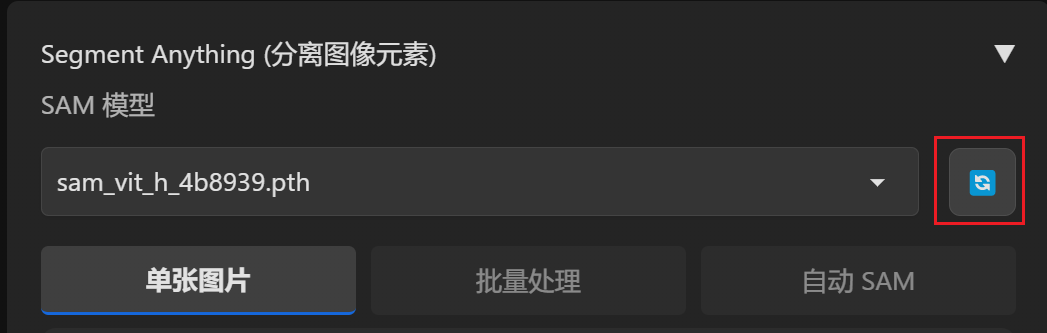
模型放到指定文件夹目录后,点开 SAM 模型控制界面,点击后面的按钮加载模型。
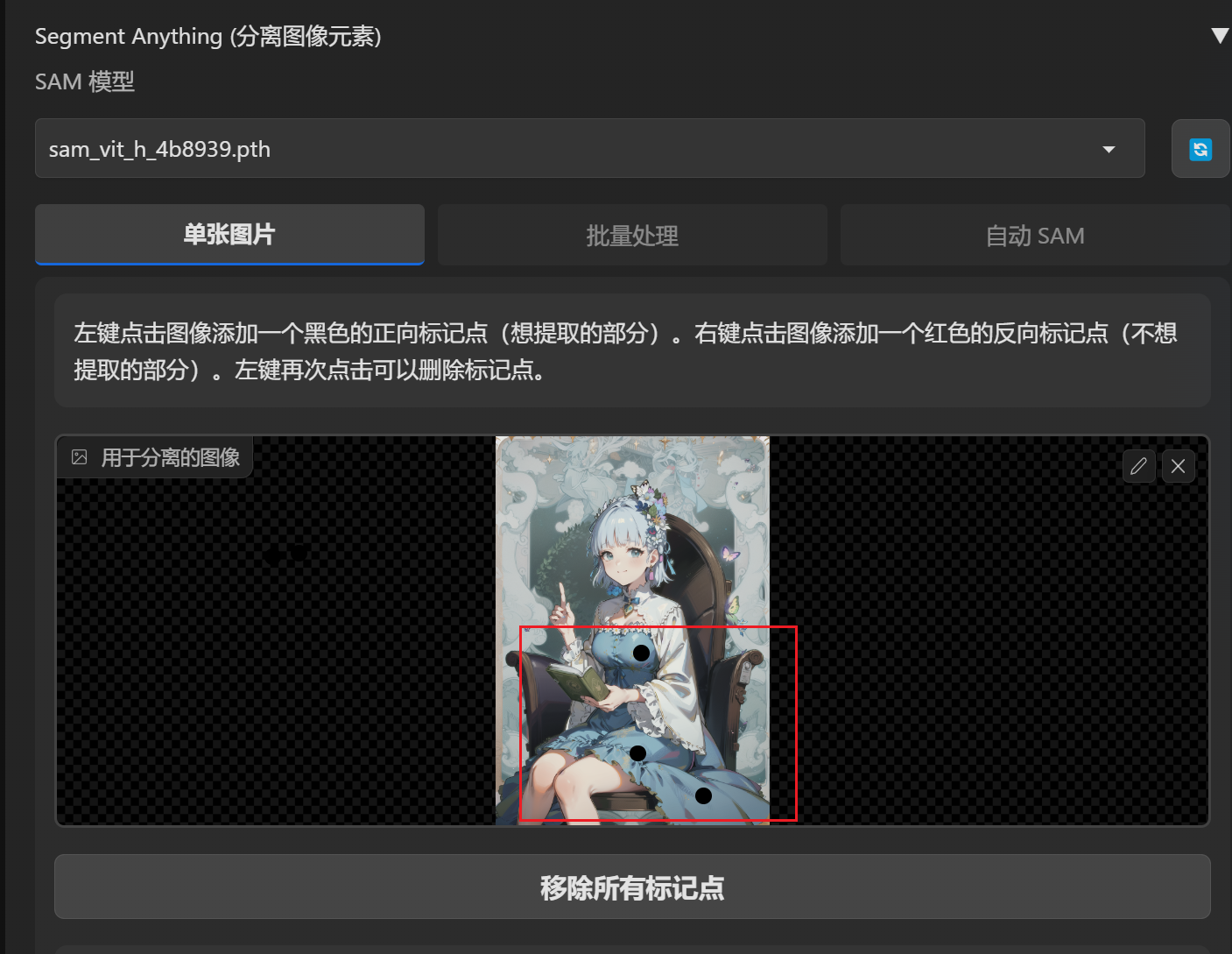
使用方式
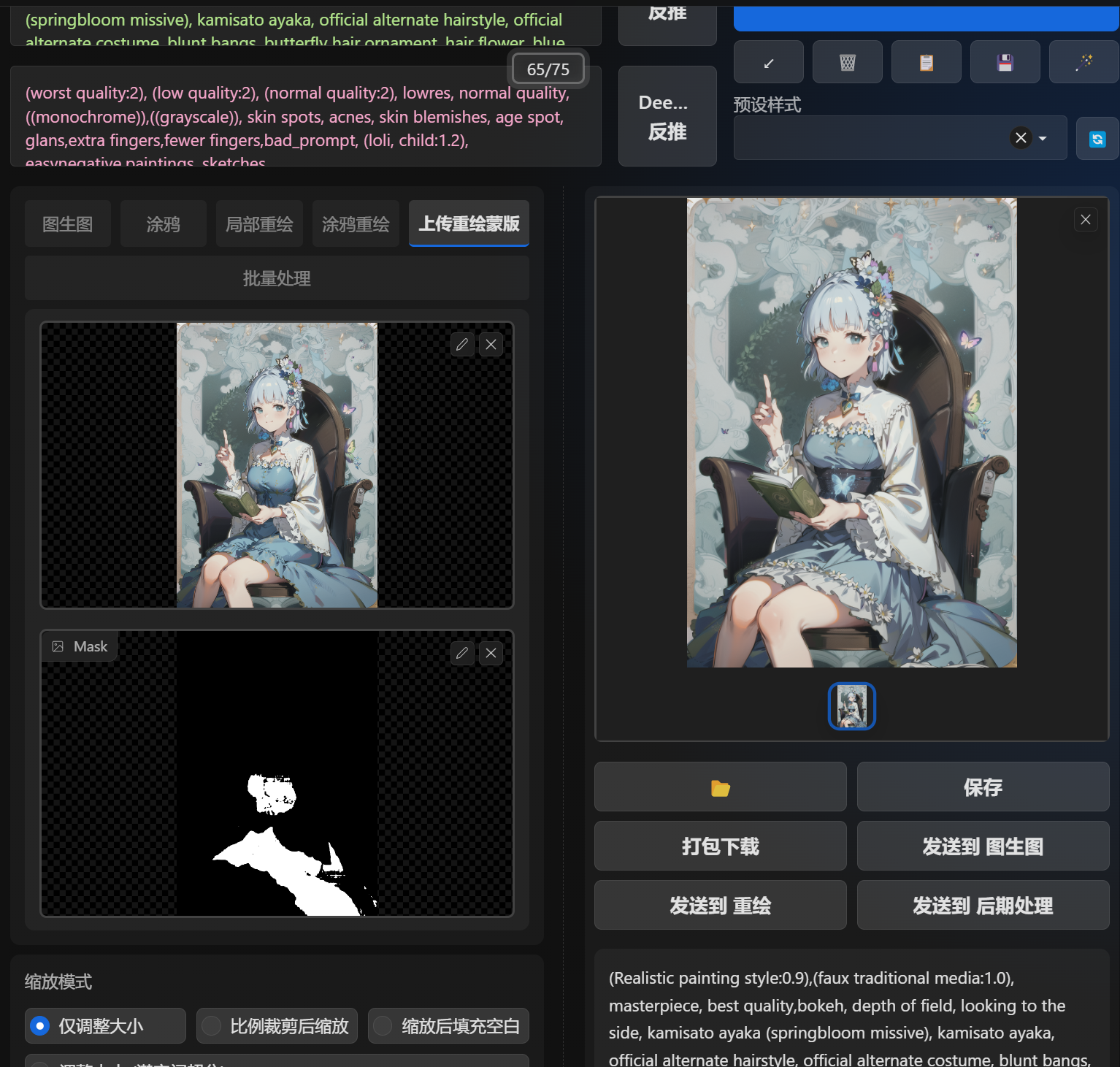
选择一张图像,然后点击添加黑点,黑点代表你想提取的部分,红点代表你不想提取的部分,点击点可以取消。比如下面的图我想重新生成裙子,所以我在裙子上选择了三个点,然后点击“预览分离结果”
SAM 模型会生成三种不同分离维度的提取蒙版,这里我选择第一张。

将选中的蒙版图片上传至”上传重绘蒙版“中,可以比较精确的控制重绘区域。
GroundingDINO
除了通过点提示词的方式生成蒙版之外,你会发现还可以开启 GroundingDINO ,这是上海 IDEA Research 团队的作品:

GroundingDINO 提供了通过提示词对图片内容进行对象检测和语义分割的方式,即通过检测词定位图片内容:

这里由于GroundingDINO 需求 cuda 12.1 来编译 torch 1.18,这里就不作演示了:

参考

若有收获,就点个赞吧
0 人点赞
