- 1. 没有用最新版的Zeppelin
- 2. 不要用Windows
- 3. 怎么查错
- 4. Flink的版本用的不对
- 5. Scala用的版本不对
- 6. 端口冲突
- 7. Jar包冲突了
- 8. Job页面
- 9. ClassNotFound 问题
- 10. Per Job 模式
- 11. Java 版本过低
- 12. Zeppelin 和 Sql-Client的关系
- 13. Zeppelin docker 镜像过期问题
- 14. 如何控制YARN 模式 TM 个数
- 15. 为什么调用 streaming wordcount的 print 在Zeppelin页面看不到输出
- 16. Zeppelin里的段落状态PENDING
- 17. 提交作业到一定量之后,有部分作业PENDING
- 18. 更多Zeppelin的使用文档
- 钉钉群+公众号
1. 没有用最新版的Zeppelin
先确认下你是否用的是最新版本,因为 Flink 和 Zeppelin 两个项目都是快速不断的升级迭代,有些问题可能是因为你没有用最新的Zeppelin版本,扫描下方二维码进钉钉群,钉钉群的群文件里一直会有最新版本的Zeppelin可供下载。
2. 不要用Windows
Zeppelin 已经不支持windows了,所以不要用windows了。
3. 怎么查错
如果你碰到了问题,不要马上到群里问,首先自己按照下面的步骤去尝试自己寻找原因。这样不仅可以节省他人时间,也可以锻炼自己解决问题的能力。
- Step 1. 看Zeppelin 页面上的错误信息,仔细看到底报的是什么错误
- Step 2. 如果Step 1 没有给你太多线索,那么去看看flink的interpreter log,在zeppelin目录下去找 logs/zeppelin-interpreter-flink-*.log
- Step 3. 去Flink Web UI上去看log
基本上以上3个步骤都能为你找到大部分问题的root cause。
4. Flink的版本用的不对
目前Zeppelin只支持Flink 1.10及以后的版本,千万别用Flink 1.9或者更老的版本,最新版本的Zeppelin会自动检查Flink版本,如果不支持会报错。
5. Scala用的版本不对
Flink的发行版有2个,一个是针对scala 2.11的,一个是scala 2.12,目前Zeppelin只支持Scala 2.11,所以请务必下载Scala 2.11的版本。
6. 端口冲突
如果你在local模式下碰到了如下的错误,那么就意味着端口冲突了。因为local模式会在本地启动一个MiniCluster,默认JobManager会使用8081端口,然而Flink的standalone模式下的JobManager碰巧也是用8081端口,所以如果是碰到这种错误,那么检查下你是否在本地起了一个Flink Standalone 集群,或者有没有其他进程使用了8081端口。如果有,就需要在 %flink.conf 里修改 rest.port 这个配置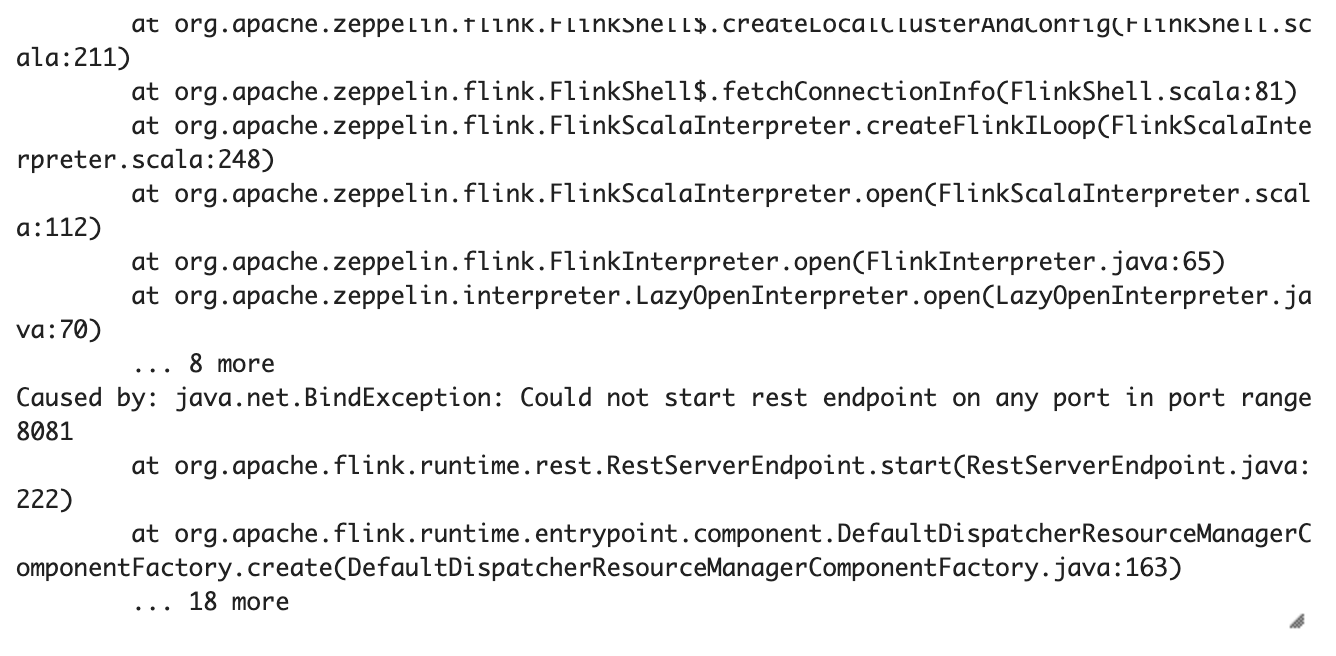
7. Jar包冲突了
如果你的flink job 用到了kafka,而你又碰到了如下的错误,那么就要注意了,多半是由于你的kafka jar包冲突了(你的classpath里有多个flink kafka connector的jar包)。
多半原因是你既用了flink.execution.packages ,又把相应的kafka connector放到了flink的lib目录下,所以导致了你的classpath里有多个flink kafka connector的jar包。
在Zeppelin中添加connector jar包依赖的最佳实践是使用 flink.execution.packages, 这个配置会自动为你从网上下载对应的package,然后放到classpath里。尽量不要把connector的jar放到flink lib下面(其他jar也是一样,尽量保持flink的lib目录是干净的,除了flink自带的jar尽量不要放任何其他jar进去),因为放到flink lib下面会影响所有的flink job,很容易造成jar包冲突,所以尽量用flink.exection.packages。如果你的机器不能访问外网,那么可以直接下载jar包上传到服务器上,然后用flink.execution.jars 来指定这些依赖。
8. Job页面
Job页面会展示所有Note的状态,但是这个页面在Note数量很多的情况下有可能会导致性能问题,所以目前默认情况是禁掉的。如果要启用这个页面,需要修改zeppelin-site.xml中的这个配置,然后重启Zeppelin。
<property><name>zeppelin.jobmanager.enable</name><value>true</value></property>
9. ClassNotFound 问题
有时候大家会碰到ClassNotFound 的问题,这类问题基本都是由于CLASSPATH问题导致的。首先你要确认是哪个class 没有 found,属于哪个jar。然后你可以用下面这个命令来确认当前Flink Interpreter进程的CLASSPATH, 然后看看是否你需要的jar在CLASSPATH上。是否有同一个依赖的多个版本的jar(这会导致冲突)
ps aux | grep RemoteInterpreterServer
10. Per Job 模式
Flink on Zeppelin 都是Session 模式,没有Per Job。Per Job和Session模式的区别其实很简单,Per Job模式就是一个Flink Cluster一个Job, Session模式是可以向一个Flink Cluster提交多个Job。所以你只要自己确保一个Flink Session Cluster里只有一个Flink Job,那么他就类似Per Job模式(启用Per Note Isolated 模式,然后每个Note只提交一个Job 就可以达到Per Job效果)。
另外一点这种方式和真正的Per Job模式不同点在于Flink Job结束之后,Session Cluster不会自动销毁,要么你点击restart interpreter手动销毁或者设置 TimeoutLifecycleManager来自动销毁。
11. Java 版本过低
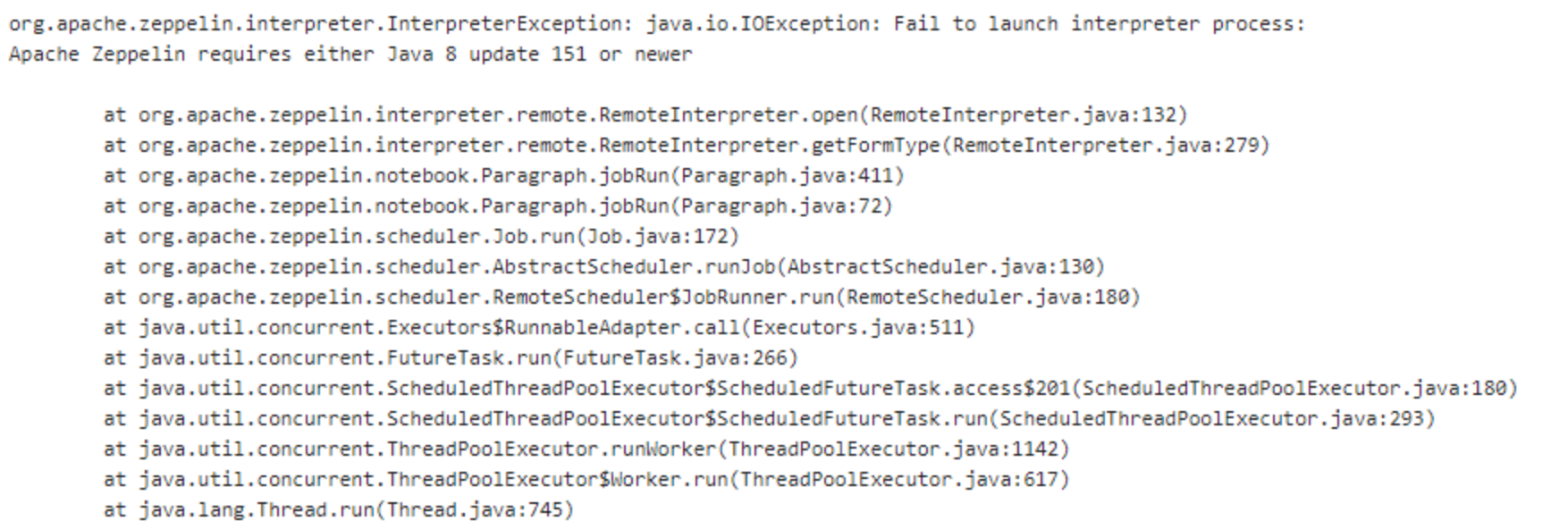
Zeppelin 对 Java版本是要求的,需要至少Java 8 update 151,如果你的Java版本过低,会出现上面的错误。一个workaround是去掉 bin/interpreter.sh 里的这句 
12. Zeppelin 和 Sql-Client的关系
Zeppelin 和 Sql-Client 没有任何依赖或被依赖关系,所以Sql-Client的配置是不能在Zeppelin 应用的。
13. Zeppelin docker 镜像过期问题
如果你在使用Zeppelin + Flink 1.12的时候碰到下面的错误,那基本上是因为你用了一个老的zeppelin 0.9.0 镜像。解决办法是删除本地镜像,从dockerhub重新下载(不要下载国内docker源,国内的源没有更新)
java.lang.NoSuchMethodError: org.apache.flink.api.common.ExecutionConfig.disableSysoutLogging()Lorg/apache/flink/api/common/ExecutionConfig;at org.apache.zeppelin.interpreter.LazyOpenInterpreter.open(LazyOpenInterpreter.java:76)atorg.apache.zeppelin.interpreter.remote.RemoteInterpreterServer$InterpretJob.jobRun(RemoteInterpreterServer.java:760)at
14. 如何控制YARN 模式 TM 个数
slotmanager.number-of-slots.max
15. 为什么调用 streaming wordcount的 print 在Zeppelin页面看不到输出
streaming wordcount 的print 和 batch wordcount的print是不一样的,batch wordcount的print是在提交job的客户端打印的,对Zeppelin来说就是Flink Interpreter,所以你总是能在Zeppelin页面看到batch wordcount的print结果。但是streaming wordcount的print是在TaskManager打印的,这里又要分2种情况,如果是local 模式,TaskManager和提交作业的客户端都是在同一个JVM进程里(也就是Flink Interpreter 进程),所以Local 模式下你是能看到streaming wordcount的print结果的,但如果是其他模式(比如yarn 或者remote模式),那么在Zeppelin页面你是看不到输出结果,只能在TaskManger的log里才能看到。
16. Zeppelin里的段落状态PENDING
Scala类型段落是FIFO,也就是一个Scala段落执行完后才能跑下一个Scala段落,Python类型段落也是FIFO,执行完一个Python段落后执行下一个Python段落。SQL类型段落是并发的,可以同时并发跑多个SQL段落(最多跑10个,具体参考语雀里的SQL文档),你看到的如果Scala或者Python段落处于PENDING状态,那么很有可能就是有其他Scala和Python段落在RUNNING,如果是SQL类型段落PENDING,那么有可能是超过了最大SQL并发量。
17. 提交作业到一定量之后,有部分作业PENDING
调大zeppelin-site里如下参数
zeppelin.interpreter.connection.poolsize (默认100)
�zeppelin.scheduler.threadpool.size (默认100)
�另外单独一个Flink Appliction能同时跑的Paragraph也是有限制的,默认为10个,可以调整flink的interpreter setting property: zeppelin.flink.concurrentStreamSql.max 和 zeppelin.flink.concurrentBatchSql.max
�
18. 更多Zeppelin的使用文档
https://www.yuque.com/jeffzhangjianfeng/ggi5ys
钉钉群+公众号


若有收获,就点个赞吧
0 人点赞
